Command Palette
Search for a command to run...
6 Classic Machine Learning Datasets, Voted by 3w+ Users, Recommended for Collection

Contents at a glance: This issue summarizes 6 datasets with the largest number of Super Neural Downloads, covering areas such as image recognition, machine translation, and remote sensing images. These datasets are of high quality and large data volume, and are worthy of collection and retention after being popular. Keywords: dataset, machine translation, machine vision
Datasets are the basis for machine learning model training. High-quality public datasets are of great significance to model training effects and the reliability of research results.
Since its launch, HyperAI has provided a large number of high-quality public data sets for data science practitioners.In this issue, we have selected 6 popular datasets.Its total download count has reached 32,569 times.I hope these data sets can further serve developers~
Note: The data sets sorted out in this article are all from the website:
No. 6: Tanks Temple 3D Reconstruction Dataset
Publishing Agency:Intel Labs
Quantity included:HD video of 21 types of objects
Data Type:video
Estimated size:52.53 GB
Release time:2017
Download address:hyper.ai/datasets/5148

The Tanks Temple image dataset provides high-resolution videos from which researchers can collect images.Perform three-dimensional reconstruction based on the image.The dataset includes two categories: training data and test data, where the test data is divided into intermediate group and advanced group.
No. 5: DOTA Aerial Image Dataset
Publishing Agency:Wuhan University
Quantity included:2,806 aerial images
Data Type:images
Estimated size:35.38 GB
Release time:2017
Download address:hyper.ai/datasets/4920

DOTA stands for A Large-scale Dataset for Object DeTection in Aerial Images. It is an image dataset containing 2,806 aerial images.It is used for target detection in aerial images to find and evaluate objects in the image.
These images come from different sensors and platforms. The pixel size of each image ranges from 800*800 to 4000*4000, and contains objects of different scales, orientations, and shapes.
For previous releases, please visit:
DOTA dataset: 2806 remote sensing images, nearly 190,000 annotated instances
No. 4: VGG-Face2 face recognition dataset
Publishing Agency:University of Oxford
Quantity included:3.31 million images
Data Type:images
Estimated size:37.49 GB
Release time:2015
Download address:hyper.ai/datasets/5711

VGG-Face2 is a face image dataset that contains facial data of 9131 people in total. The images are all from Google's image search.The people in the dataset vary widely in posture, age, race, and occupation.This dataset was released by the Visual Geometry Group of the Department of Engineering Science at the University of Oxford in 2015, and the related paper is "Deep Face Recognition".
No. 3: UCAS-AOD Remote Sensing Image Dataset
Publishing Agency:University of Chinese Academy of Sciences
Quantity included:910 images
Data Type:images
Estimated size:3.24 GB
Release time:2014
Download address:hyper.ai/datasets/5419

UCAS-AOD is a remote sensing image dataset.For aircraft and vehicle inspection.This dataset was first released by the University of Science and Technology of China in 2014 and supplemented in 2015. The related papers include "Orientation Robust Object Detection in Aerial Images Using Deep Convolutional Neural Network"
No. 2: OpenMantra comic machine translation dataset
Publishing Agency:University of Tokyo
Quantity included:214 pages of comics
Data Type:JSON files, images
Estimated size:32.46 MB
Release time:2020
Download address:hyper.ai/datasets/14137
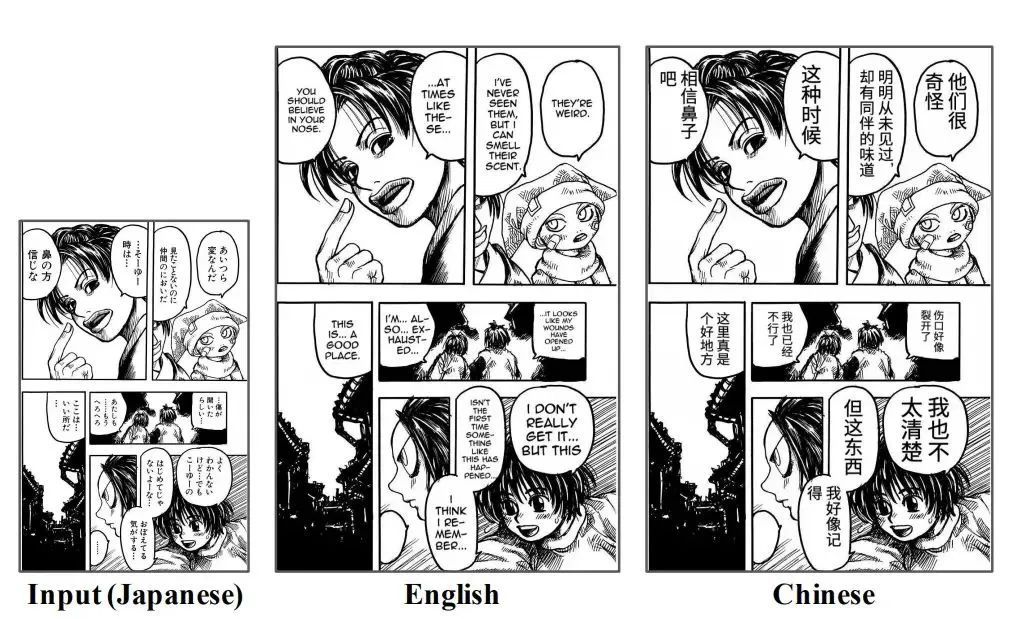
OpenMantra is a machine translation evaluation dataset for Japanese comics, containing comics in five different styles (fantacy, romance, battle, mystery, slice of life).The dataset contains 1593 sentences, 848 scenes and 214 pages of comics.Published by Mantra Team, University of Tokyo.
For previous pushes, please see:
HyperAI: Comic Translation, Embedded Word AI, Tokyo University Paper Included in AAAI'21 3 Likes · 1 Comment
No. 1: ImageNet 10 image recognition dataset
Publishing Agency:Princeton University
Quantity included:15 million images
Data Type:images
Estimated size:860.55 GB
Release time:2009
Download address:hyper.ai/datasets/4889

ImageNet is currently the world's largest image recognition database, created by Stanford University professor Fei-Fei Li and others.Mainly used for image classification and target detection in the field of machine vision.
The dataset is organized according to the WordNet hierarchy, where each node (also called category) consists of hundreds or even thousands of images. The dataset contains a total of 22,000 image categories and approximately 15 million images.
For previous releases, please visit:
This decision made Fei-Fei Li the queen of AI industrymp.weixin.qq.com/s/VyKUmG512pFJ3XTgVf4Qjg
The above are the 6 hyper.ai frequently downloaded datasets recommended in this issue. For more high-quality public datasets for data science, click at the end of the article.Read the original article,Or visit the following link to download:
This article was first published on WeChat public account "HyperAI Super Neural Network"6 classic machine learning datasets, voted by 3w+ users, recommended for collection』
-- over--








