HyperAI
Command Palette
Search for a command to run...
WIT image-text Dataset
Date
4 years ago
Size
25.2 GB
Organization
Publish URL
Paper URL
License
Other
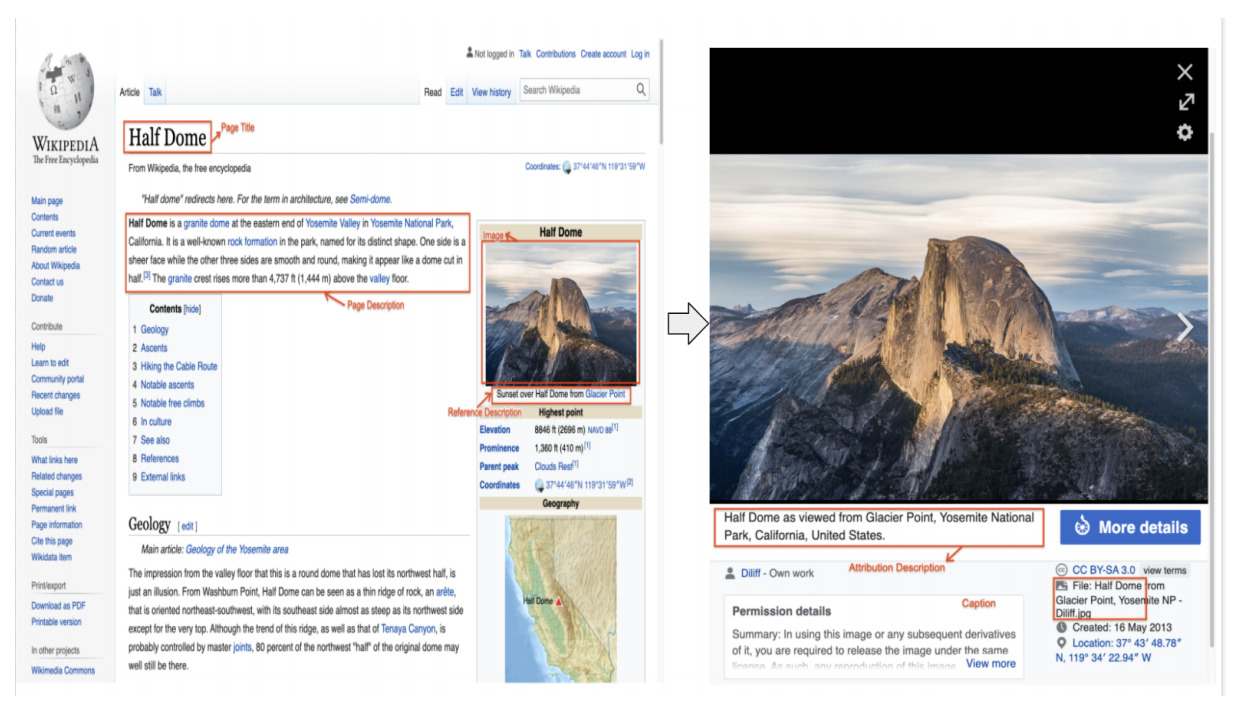
WIT, short for Wikipedia-based Image Text, is a large multimodal and multilingual dataset. The dataset consists of a curated collection of 37.6 million entity-rich image-text examples, including 11.5 million unique images in 108 Wikipedia languages. The scale of the dataset allows it to be used as a pre-training dataset for multimodal machine learning models. WIT has four unique advantages:
- WIT is the largest multimodal dataset in terms of the number of image-text examples.
- Over 100 languages are covered (with at least 12,000 examples per language), and cross-lingual text is provided for many images.
- Relative to previous datasets, WIT represents a more diverse set of concepts and real-world entities.
- WIT provides a very challenging real-world test set.
WIT.torrent
Seeding 1Downloading 0Completed 611Total Downloads 809
This dataset is contributed by community users and is intended for educational and informational purposes only. If any content involves copyright infringement, please contact us at [email protected] for prompt review and removal.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.
AI Co-coding
Ready-to-use GPUs
Best Pricing
HyperAI Newsletters
Subscribe to our latest updates
We will deliver the latest updates of the week to your inbox at nine o'clock every Monday morning
Powered by MailChimp