Command Palette
Search for a command to run...
OuteTTS: Sprachgenerierungs-Engine
Datum
Größe
343.32 MB
Tags
Lizenz
Apache 2.0
GitHub
Paper-URL
1. Einführung in das Tutorial

- Text-to-Speech-Synthese: Geben Sie Text ein, um eine natürliche und flüssige Sprachausgabe zu erzeugen, die anpassbare Sprechgeschwindigkeit und Intonation unterstützt.
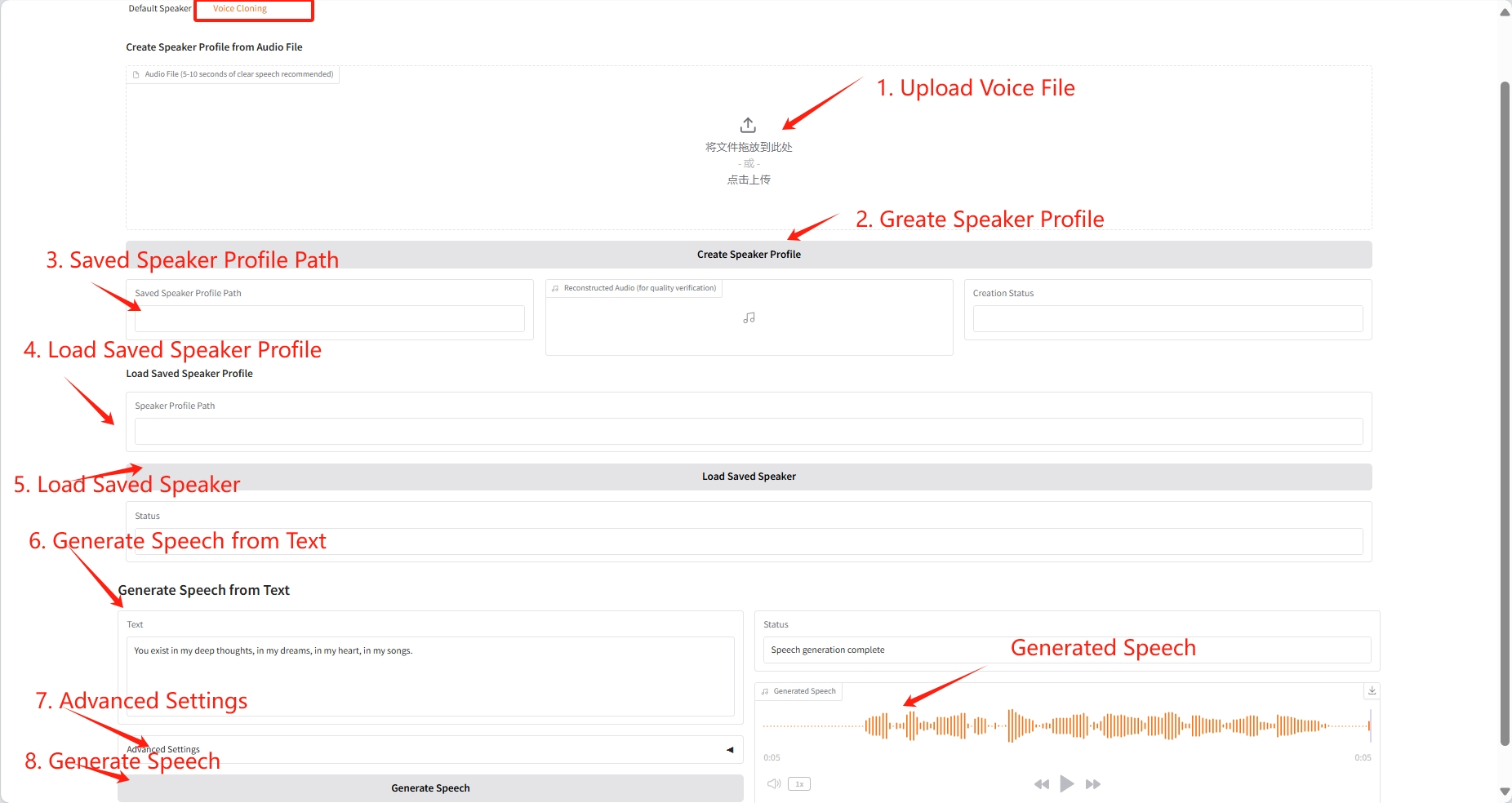
- Stimmenklonen: Benutzer können Referenzaudio von nur wenigen Sekunden und entsprechenden Text bereitstellen, um personalisierte Stimmen zu erstellen, die für benutzerdefinierte Sprachassistenten, Hörbücher und andere Szenarien geeignet sind.
Das in diesem Tutorial verwendete Modell ist das im März 2025 von Oute AI veröffentlichte Modell Llama-OuteTTS-1.0-1B. Die Parameter wurden von 350 Millionen auf 1 Milliarde erhöht, wodurch die Ausdruckskraft und Stabilität der Stimme deutlich verbessert wurden. Es unterstützt außerdem die lokalisierte Synthese in 20 Sprachen, und die sprachübergreifende Klonfunktion wurde weiter optimiert.
Die Rechenressourcen dieses Tutorials nutzen eine einzelne RTX 4090-Karte. Dieses Tutorial bietet hauptsächlich zwei Anwendungsbeispiele für Standardlautsprecher und Sprachklonen. Dieses Tutorial ist nur auf Englisch verfügbar.
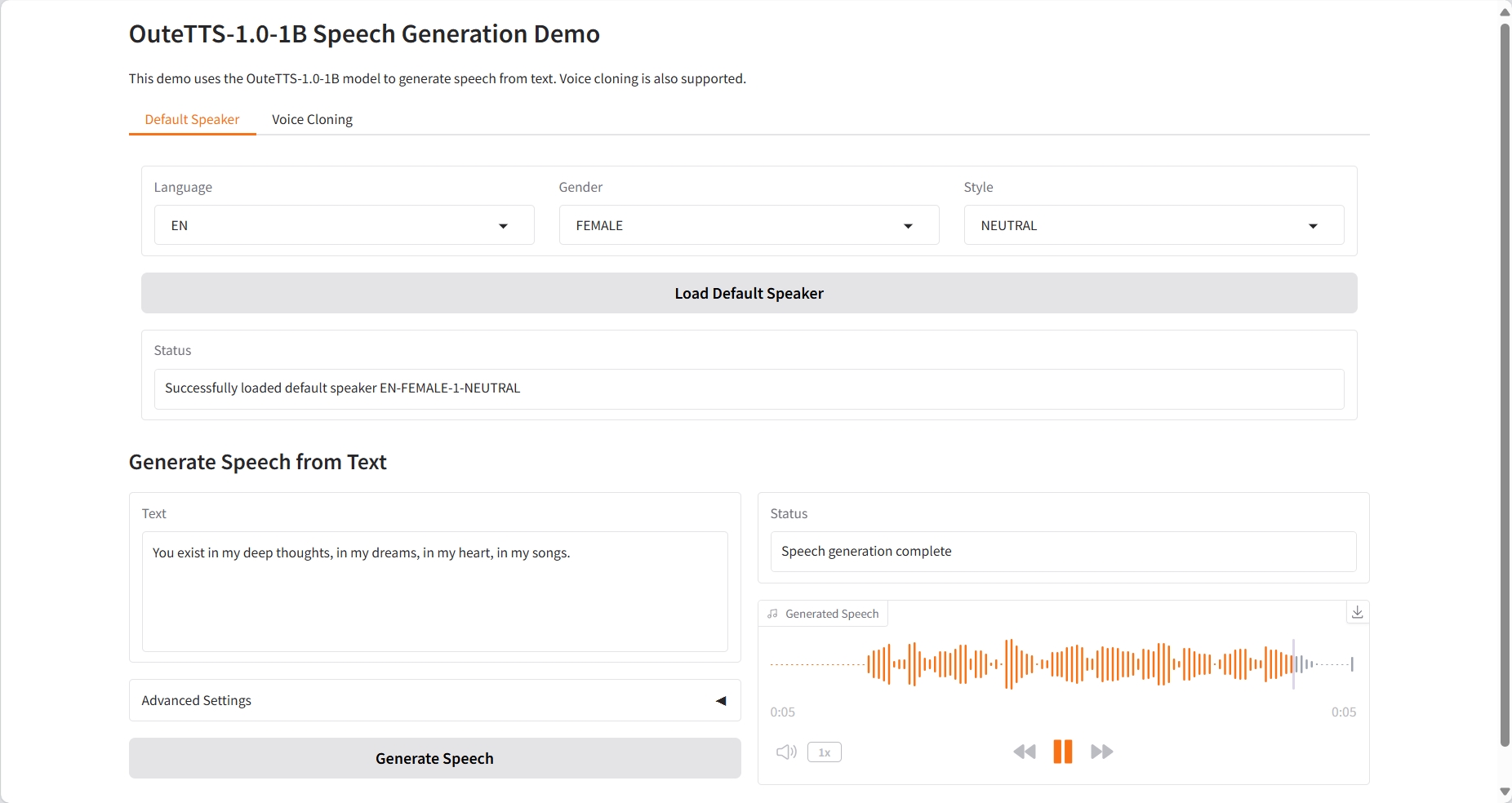
2. Effektanzeige
3. Bedienungsschritte
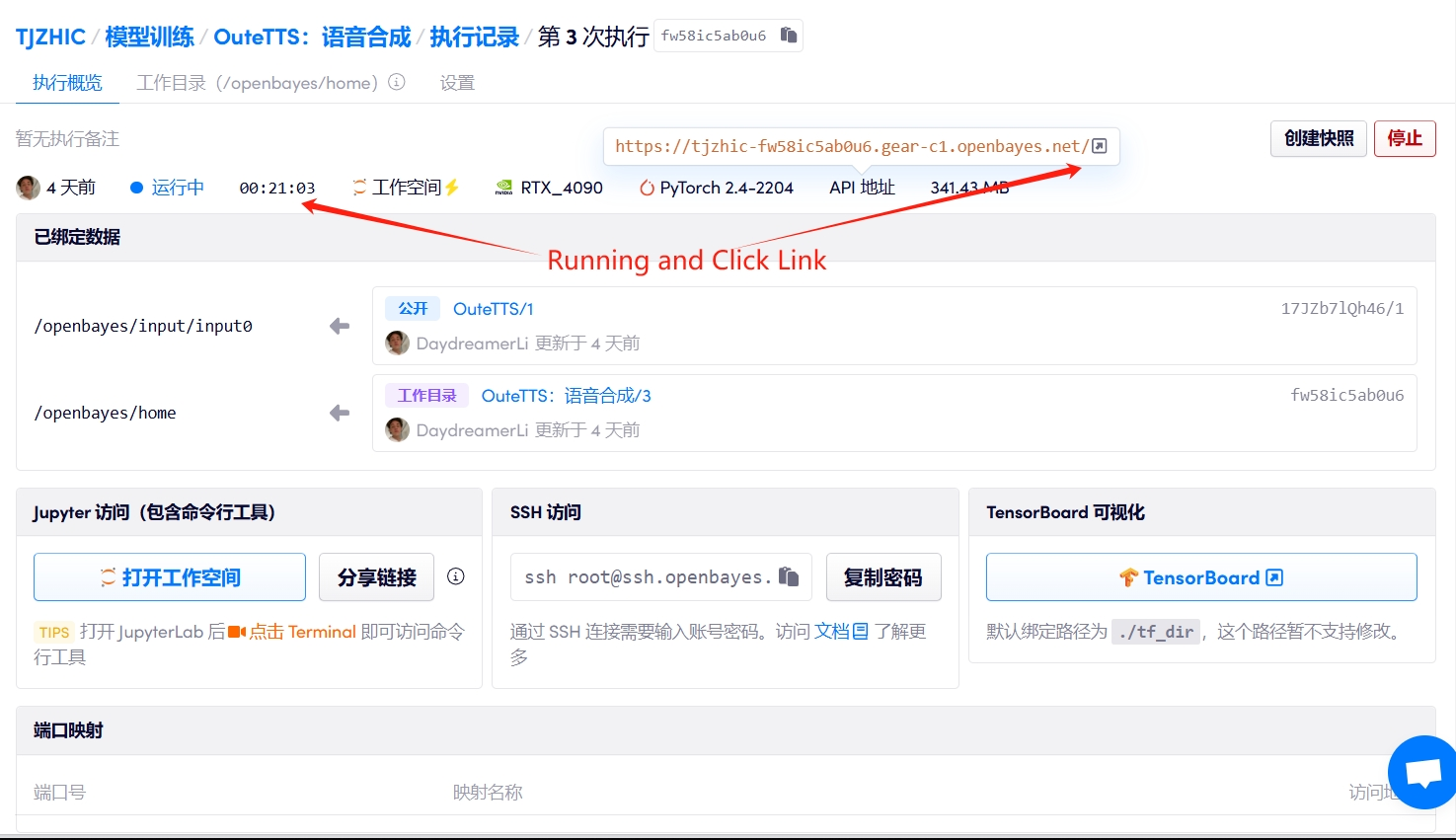
1. Starten Sie den Container
2. Anwendungsschritte
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 2–3 Minuten und aktualisieren Sie die Seite.
Bei Verwendung des Safari-Browsers wird der Ton möglicherweise nicht direkt abgespielt und muss vor der Wiedergabe heruntergeladen werden.
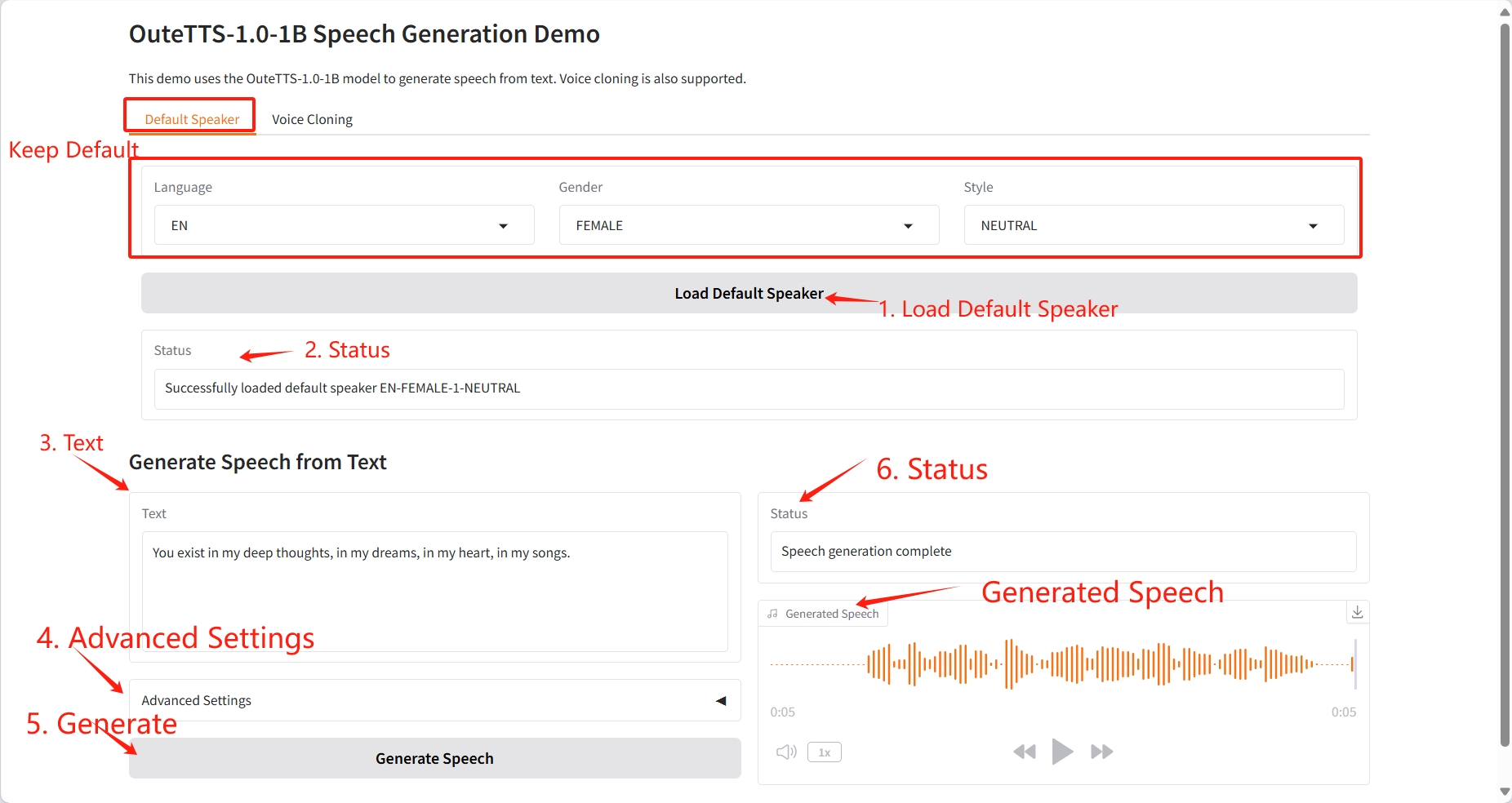
Spezifische Parameter:
- Text: Geben Sie den zu generierenden Text ein.
- Temperatur: Skalierungsfaktor, der die Zufälligkeit der Ausgabe steuert.
- Wiederholungsstrafe: Strafkoeffizient zur Unterdrückung wiederholter Generierung.
- Top-k: Begrenzen Sie die Anzahl der in jedem Schritt generierten Kandidatenwörter.
- Top-p: Dynamische Auswahl von Kandidatenwörtern (Kernel-Sampling).
- Minimale Wahrscheinlichkeit (min-p): Legt den Mindestwahrscheinlichkeitsschwellenwert für Kandidatenwörter fest.
1. Standardlautsprecher
2. Stimmenklonen
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓

KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.