Command Palette
Search for a command to run...
MonkeyOCR: Dokumentenanalyse Basierend Auf Dem Struktur-Erkennungs-Relations-Dreifachparadigma
1. Einführung in das Tutorial

MonkeyOCR ist ein am 5. Juni 2025 von der Huazhong University of Science and Technology in Zusammenarbeit mit Kingsoft Office als Open Source veröffentlichtes Dokumentenanalysemodell. Das Modell wandelt unstrukturierte Dokumentinhalte effizient in strukturierte Informationen um. Basierend auf präziser Layoutanalyse, Inhaltserkennung und logischer Sortierung verbessert es die Genauigkeit und Effizienz der Dokumentenanalyse signifikant. Im Vergleich zu herkömmlichen Methoden erzielt MonkeyOCR hervorragende Ergebnisse bei der Verarbeitung komplexer Dokumente (z. B. solcher mit Formeln und Tabellen) mit einer durchschnittlichen Leistungssteigerung von 5,11 TP3T sowie Verbesserungen von 15,01 TP3T bzw. 8,61 TP3T bei der Formel- bzw. Tabellenanalyse. Das Modell zeichnet sich durch seine hohe Leistungsfähigkeit bei der Verarbeitung mehrseitiger Dokumente aus und erreicht 0,84 Seiten pro Sekunde – ein Wert, der andere vergleichbare Tools deutlich übertrifft. MonkeyOCR unterstützt verschiedene Dokumenttypen, darunter wissenschaftliche Artikel, Lehrbücher und Zeitungen, und ist mit mehreren Sprachen kompatibel. Es bietet somit eine leistungsstarke Unterstützung für die Dokumentendigitalisierung und automatisierte Verarbeitung. Zugehörige Forschungsarbeiten sind verfügbar. MonkeyOCR: Dokumentanalyse mit einem Struktur-Erkennungs-Relations-Triplet-Paradigma .
Hauptmerkmale:
- Dokumentanalyse und -strukturierung: Konvertieren Sie unstrukturierte Inhalte (einschließlich Text, Tabellen, Formeln, Bilder usw.) in Dokumenten verschiedener Formate (wie PDF, Bilder usw.) in strukturierte, maschinenlesbare Informationen.
- Mehrsprachige Unterstützung: Unterstützt mehrere Sprachen, darunter Chinesisch und Englisch.
- Effiziente Verarbeitung komplexer Dokumente: Die Leistung ist gut bei der Verarbeitung komplexer Dokumente (z. B. solcher mit Formeln, Tabellen, mehrspaltigen Layouts usw.).
- Schnelle Verarbeitung mehrseitiger Dokumente: Effiziente Verarbeitung mehrseitiger Dokumente mit einer Verarbeitungsgeschwindigkeit von 0,84 Seiten pro Sekunde, deutlich besser als andere Tools (z. B. MinerU 0,65 Seiten pro Sekunde, Qwen2.5-VL-7B 0,12 Seiten pro Sekunde).
- Flexible Bereitstellung und Erweiterung: Unterstützt die effiziente Bereitstellung auf einer einzelnen NVIDIA 3090-GPU, um Anforderungen unterschiedlicher Größenordnungen gerecht zu werden.
Technisches Prinzip:
- Struktur-Erkennungs-Beziehung (SRR)-Tripelparadigma: Ein auf YOLO basierender Dokumentlayout-Detektor, der die Position und Kategorie von Schlüsselelementen in einem Dokument (wie Textblöcken, Tabellen, Formeln, Bildern usw.) identifiziert. Die Inhaltserkennung erfolgt für jede erkannte Region. Die End-to-End-Erkennung erfolgt mithilfe eines großen multimorphen Modells (LMM), um eine hohe Genauigkeit zu gewährleisten. Basierend auf einem Mechanismus zur Vorhersage der Lesereihenfolge auf Blockebene wird die logische Beziehung zwischen den erkannten Elementen ermittelt, um die semantische Struktur des Dokuments zu rekonstruieren.
- MonkeyDoc-Datensatz: MonkeyDoc ist der bislang umfassendste Datensatz zur Dokumentanalyse. Er enthält 3,9 Millionen Instanzen und deckt mehr als zehn Dokumenttypen in Chinesisch und Englisch ab. Der Datensatz basiert auf einer mehrstufigen Pipeline, die sorgfältige manuelle Annotation, programmatische Synthese und modellbasierte automatische Annotation integriert. Er dient zum Trainieren und Evaluieren von MonkeyOCR-Modellen und gewährleistet so starke Generalisierungsmöglichkeiten in vielfältigen und komplexen Dokumentszenarien.
- Modelloptimierung und -bereitstellung: Der AdamW-Optimierer und die Cosinus-Lernratenplanung werden in Kombination mit umfangreichen Datensätzen für das Training verwendet, um ein Gleichgewicht zwischen Modellgenauigkeit und Effizienz zu gewährleisten. Basierend auf dem LMDeplov-Tool kann MonkeyOCR effizient auf einer einzelnen NVIDIA 3090-GPU ausgeführt werden und unterstützt schnelles Denken und die Bereitstellung im großen Maßstab.
Dieses Tutorial verwendet eine einzelne RTX 5090-Grafikkarte als Rechenressource.
2. Effektanzeige
Beispiel für ein Formeldokument

Beispiel für ein Tabellendokument

Zeitungsbeispiel

Beispiel für einen Finanzbericht


3. Bedienungsschritte
1. Starten Sie den Container
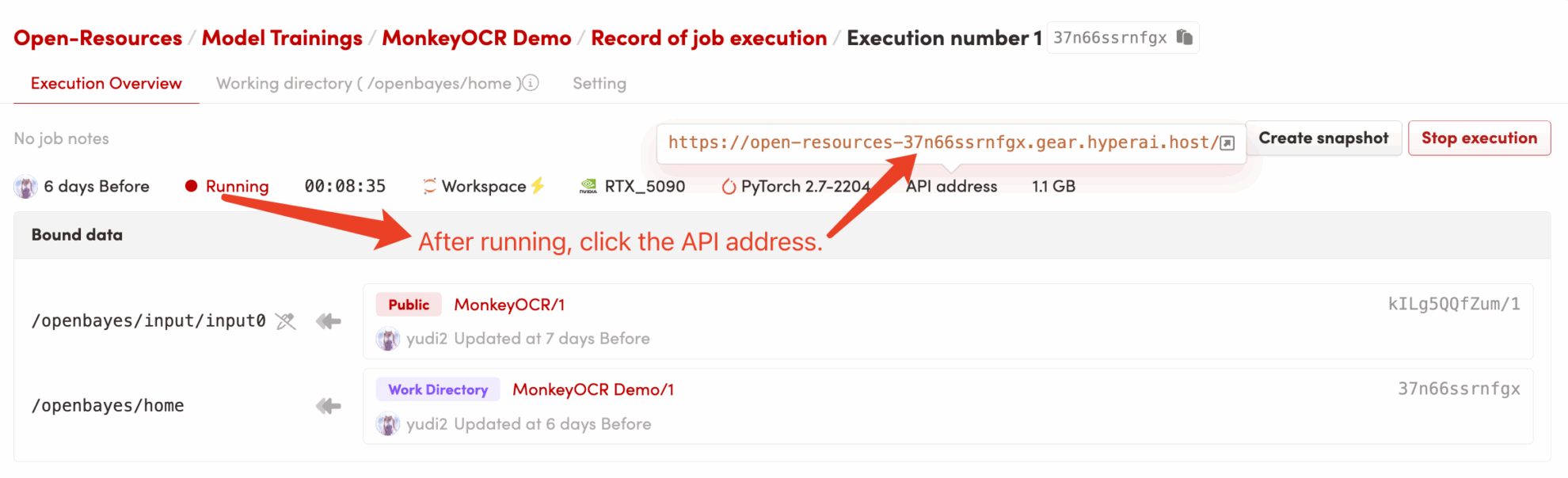
2. Anwendungsschritte
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 2–3 Minuten und aktualisieren Sie die Seite.

Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@misc{li2025monkeyocrdocumentparsingstructurerecognitionrelation,
title={MonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm},
author={Zhang Li and Yuliang Liu and Qiang Liu and Zhiyin Ma and Ziyang Zhang and Shuo Zhang and Zidun Guo and Jiarui Zhang and Xinyu Wang and Xiang Bai},
year={2025},
eprint={2506.05218},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.05218},
}
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.