Command Palette
Search for a command to run...
OpenAudio-s1-mini: Ein Hocheffizientes TTS-Generierungstool
Datum
Lizenz
Apache 2.0
GitHub
1. Einführung in das Tutorial

Dieses Tutorial verwendet Ressourcen für eine einzelne RTX 4090-Karte.
2. Projektbeispiele
Text-zu-Sprache
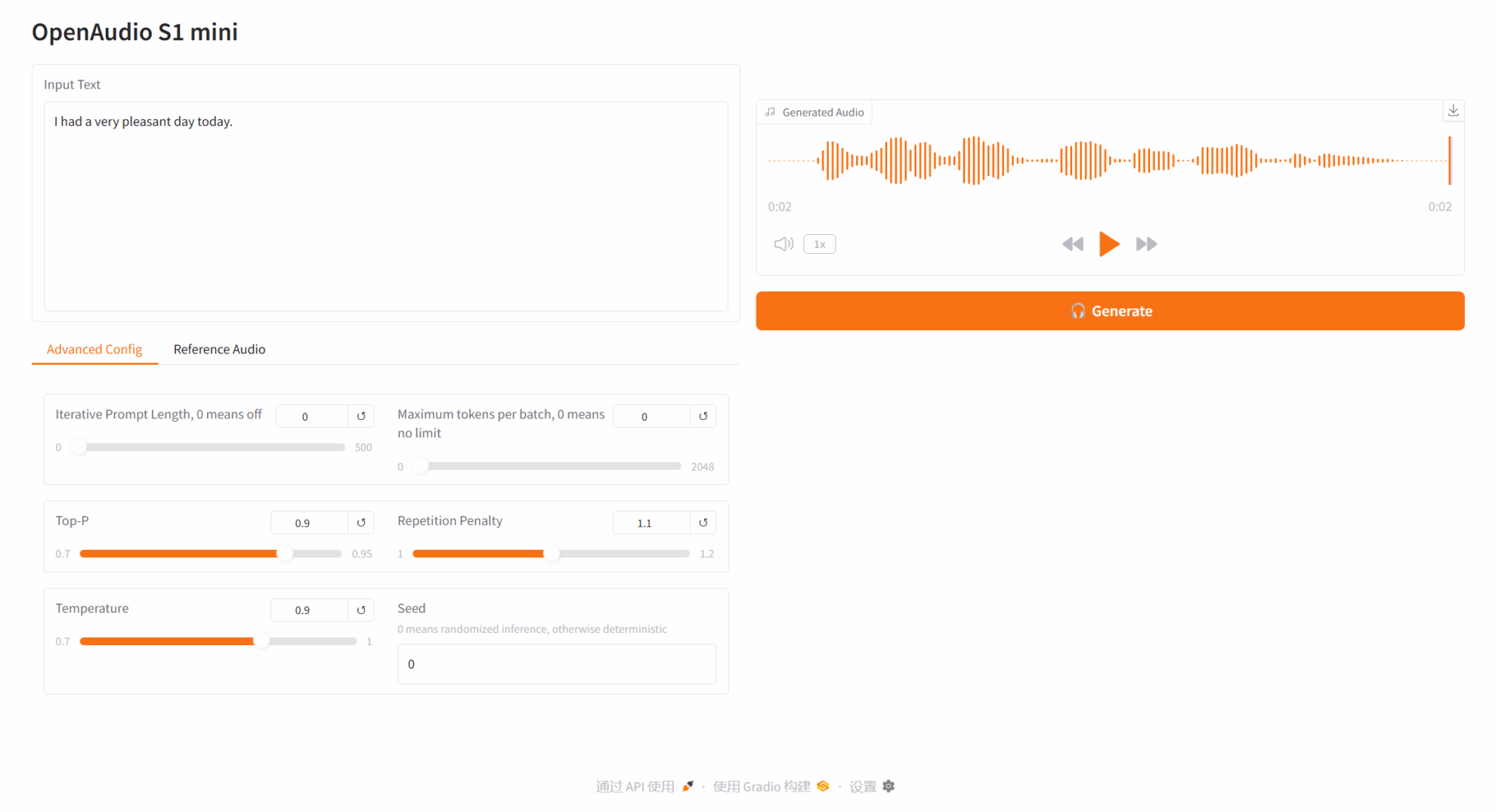

3. Bedienungsschritte
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
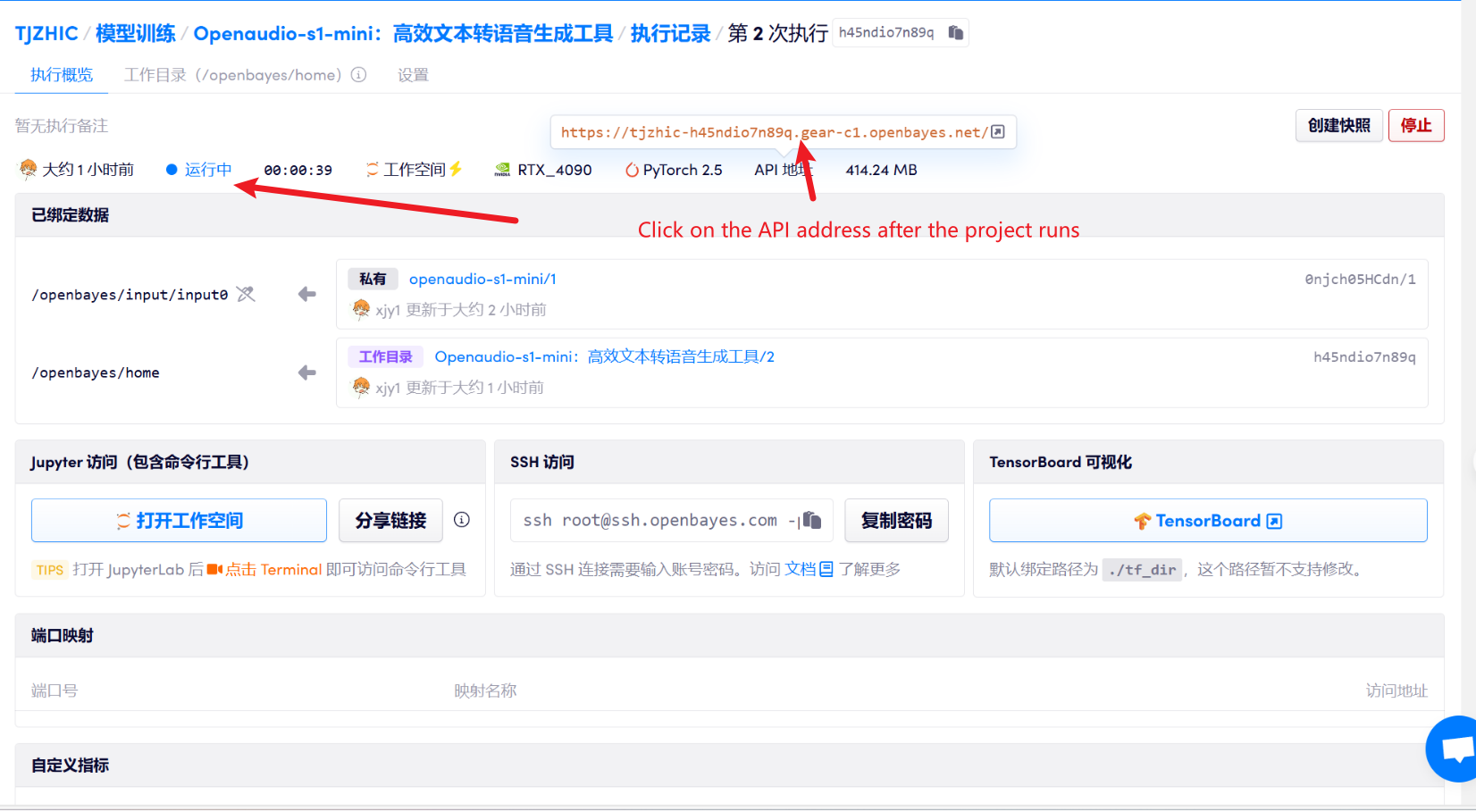
2. Sobald Sie die Webseite betreten, können Sie das Modell verwenden
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 1–2 Minuten und aktualisieren Sie die Seite. Bei Verwendung des Safari-Browsers wird der Ton möglicherweise nicht direkt abgespielt und muss vor der Wiedergabe heruntergeladen werden.
Anwendung
2.1 Text zu Audio
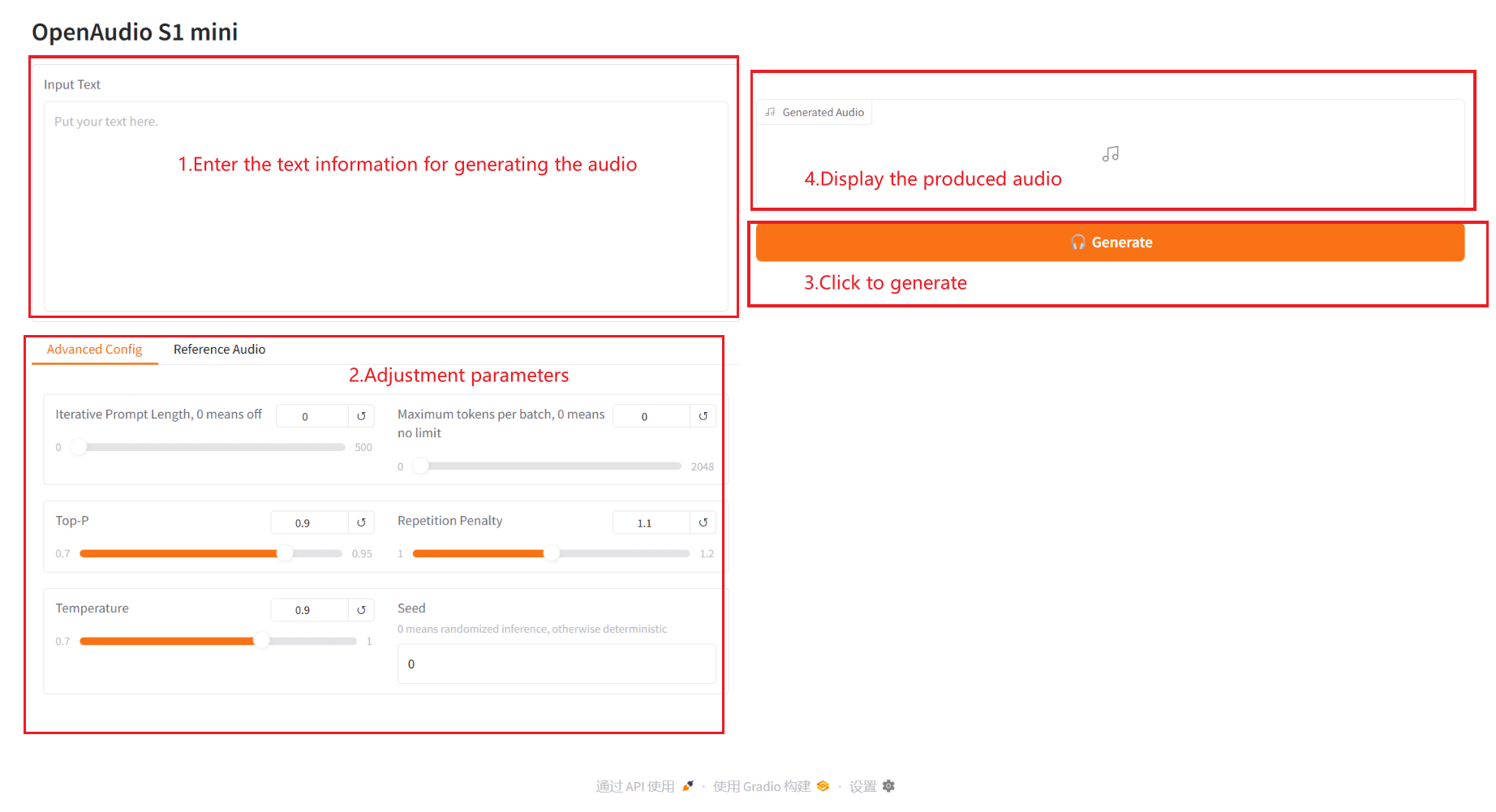
Parameterbeschreibung:
- Erweiterte Konfiguration:
- Iterative Prompt-Länge: Iterative Prompt-Länge. 0 bedeutet deaktiviert. Ein Wert ungleich Null steuert die Länge des Prompt-Textes, der bei der iterativen Sprachgenerierung verwendet wird.
- Maximale Anzahl Token pro Batch: Die maximale Anzahl Token pro Batch. 0 bedeutet unbegrenzt. Ein Wert ungleich Null begrenzt die maximale Anzahl der pro Batch verarbeiteten Token.
- Oben – P: Kernel-Sampling-Wahrscheinlichkeit, die die Vielfalt und Sicherheit des generierten Textes steuert.
- Wiederholungsstrafe: Wiederholungsstrafkoeffizient, der verwendet wird, um die Häufigkeit wiederholter Inhalte im generierten Text zu steuern. Je höher der Wert, desto mehr Wiederholungen werden vermieden.
- Temperatur: Temperaturkoeffizient, der die Zufälligkeit des generierten Textes anpasst. Je größer der Wert, desto zufälliger ist er.
- Seed: Zufalls-Seed, der zum Generieren fester Zufallszahlen verwendet wird, um reproduzierbare Ergebnisse sicherzustellen.
- Referenz-Audio:
- Speichercache verwenden: Wählen Sie aus, ob der Speichercache verwendet werden soll.
- Referenz-Audio: Laden Sie eine Audiodatei (WAV-Datei) hoch, die als Referenz für den Toninhalt verwendet werden soll.
- Referenztext: Geben Sie den Textinhalt des hochgeladenen Audios ein.
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓

Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@misc{fish-speech-v1.4,
title={Fish-Speech: Leveraging Large Language Models for Advanced Multilingual Text-to-Speech Synthesis},
author={Shijia Liao and Yuxuan Wang and Tianyu Li and Yifan Cheng and Ruoyi Zhang and Rongzhi Zhou and Yijin Xing},
year={2024},
eprint={2411.01156},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2411.01156},
}
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.