Command Palette
Search for a command to run...
Stable-audio-open-small: Demo Des Audiogenerierungsmodells
Datum
Größe
1.47 GB
Lizenz
MIT
Paper-URL
1. Einführung in das Tutorial

Dieses Tutorial verwendet eine A6000-Einzelkarte. Die generierten Eingabeaufforderungen unterstützen nur Englisch.
2. Projektbeispiele
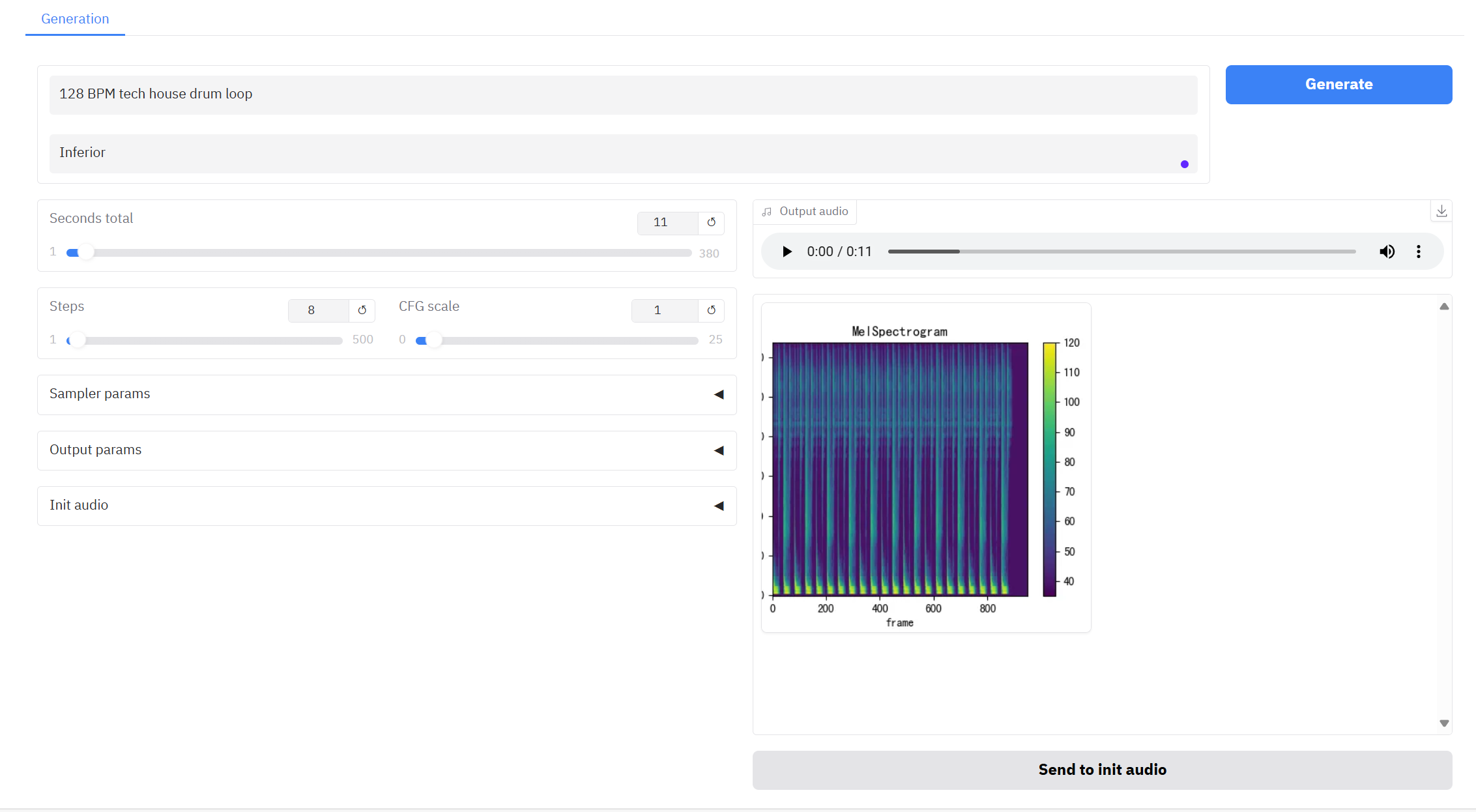
3. Bedienungsschritte
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 1–2 Minuten und aktualisieren Sie die Seite.
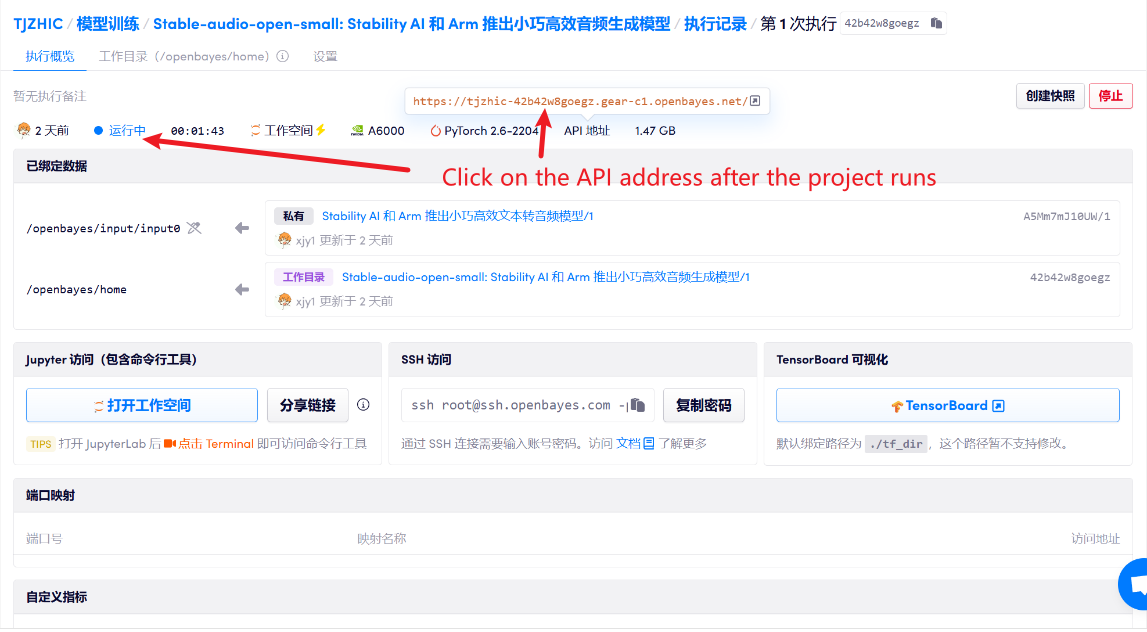
2. Nachdem Sie die Webseite aufgerufen haben, können Sie ein Gespräch mit dem Modell beginnen
Tipps: Falsche Parametereinstellungen können zu Rauschen führen. Bei Verwendung des Safari-Browsers wird der Ton möglicherweise nicht direkt abgespielt und muss vor der Wiedergabe heruntergeladen werden.
Anwendung
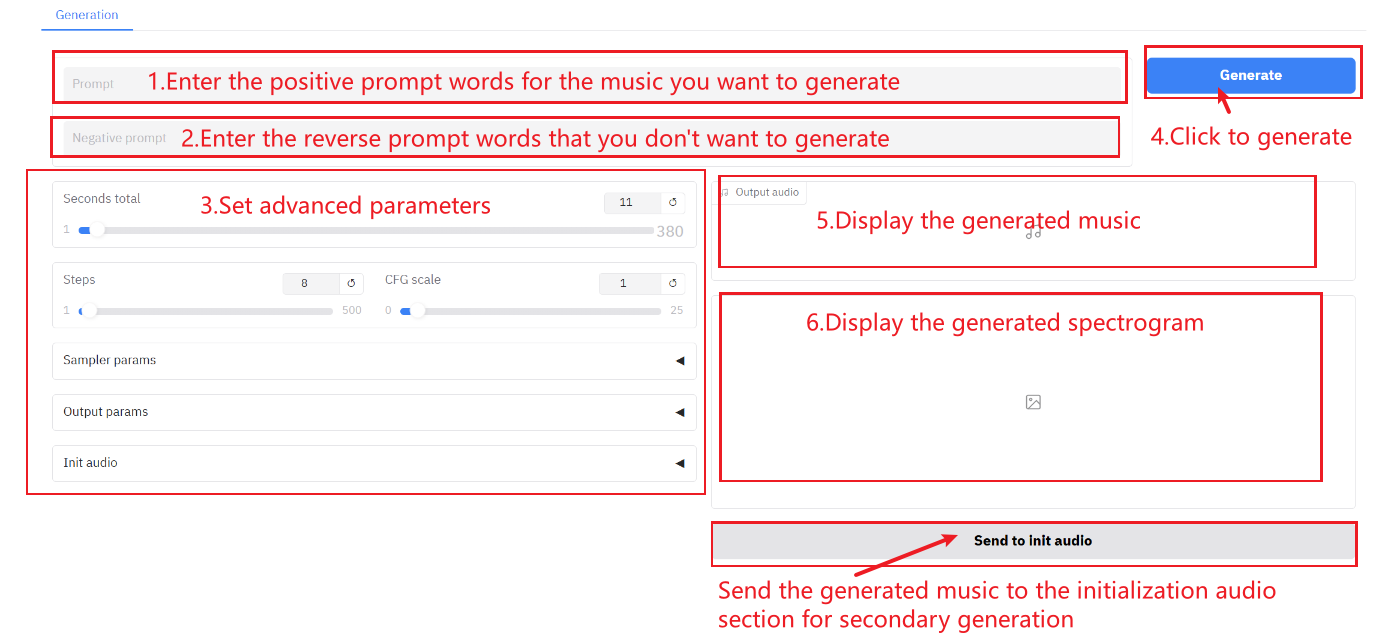
Parameterbeschreibung:
- Sekunden gesamt: Die Gesamtdauer des generierten Audios.
- Schritte: Die Anzahl der Iterationen bzw. Schritte im Inferenzprozess des Modells entspricht der Anzahl der Optimierungsschritte, die das Modell benötigt, um das Ergebnis zu erzielen. Eine höhere Anzahl von Schritten führt im Allgemeinen zu präziseren Ergebnissen, kann aber auch die Rechenzeit verlängern.
- CFG-Skala: Es wird verwendet, um den Einfluss bedingter Eingaben auf die generierten Ergebnisse im generativen Modell zu steuern. Je höher der Wert, desto besser entspricht es der Textbeschreibung.
Sampler-Parameter
- Samen: Der Zufallsstartwert bleibt konstant und kann wiederholt dieselben Ergebnisse erzeugen.
- CFG-Intervall min: Stellen Sie die bedingte Anleitung auf den zeitlichen Startpunkt des Diffusionsprozesses ein.
- CFG-Intervall max: Stellen Sie die bedingte Führung auf den Zeitpunkt des Diffusionsprozesses ein.
- CFG-Neuskalierungsbetrag: Durch dynamisches Anpassen der Bedingungsstärke wird ein numerischer Überlauf verhindert und die Generierungsstabilität bei hoher Bedingungsstärke verbessert.
Ausgabeparameter
- Dateiformat: Wählen Sie das Ausgabedateiformat.
- Dateibenennung: Wählen Sie die Benennungsmethode für die Ausgabedatei aus.
- Spezifikationsvorschau alle: Wählen Sie aus, ob eine Vorschau des Spektrumdiagramms angezeigt werden soll.
- Schnitt auf Sekunden Gesamt: Ob auf die angegebene Dauer gekürzt werden soll.
- Automatische Wiedergabe: Ob automatisch abgespielt werden soll.
- Unendliches Radio: Ob in einer Schleife generiert werden soll.
- Automatischer Download: Ob der Download automatisch erfolgen soll.
Audio initialisieren
- Audio initialisieren: Wählen Sie die ursprüngliche Audiodatei aus, um neues Audio zu generieren.
- Init-Geräuschpegel: Initialisiert den Geräuschpegel, der die anfängliche Zufälligkeit des generierten Audios steuert.
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓

KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.