Command Palette
Search for a command to run...
Ebook2Audiobook E-Book Zu Hörbuch

1. Einführung in das Tutorial
Ebook2Audiobook ist ein im Jahr 2024 als Open Source veröffentlichtes Tool zum Konvertieren elektronischer Bücher (E-Books) in Hörbücher (Audiobooks). Das Projekt verwendet fortschrittliche Text-to-Speech-Technologie (TTS), um den Textinhalt von E-Books automatisch in Sprache umzuwandeln und so Hörbücher zu erstellen, die die Benutzer anhören können. Ebook2Audiobook unterstützt mehrere E-Book-Formate wie EPUB, PDF, MOBI usw. und kann die Kapitelstruktur und Metadaten beibehalten, sodass die generierten Hörbücher leichter zu navigieren und zu verstehen sind.
Projektfunktionen:
- 📖 Konvertieren Sie eBooks mit Calibre in das Textformat.
- 📚Teilen Sie eBooks in Kapitel auf, um Audio zu organisieren.
- 🎙️Hochwertige Text-to-Speech-Funktion mit Coqui XTTSv2 und Fairseq.
- 🗣️Optionales Stimmenklonen, verwenden Sie Ihre eigenen Sprachdateien.
- 🌍Unterstützt 1107 Sprachen (standardmäßig Englisch)
Neue v2.0 Web-GUI-Schnittstelleneffekte

2. Bedienungsschritte
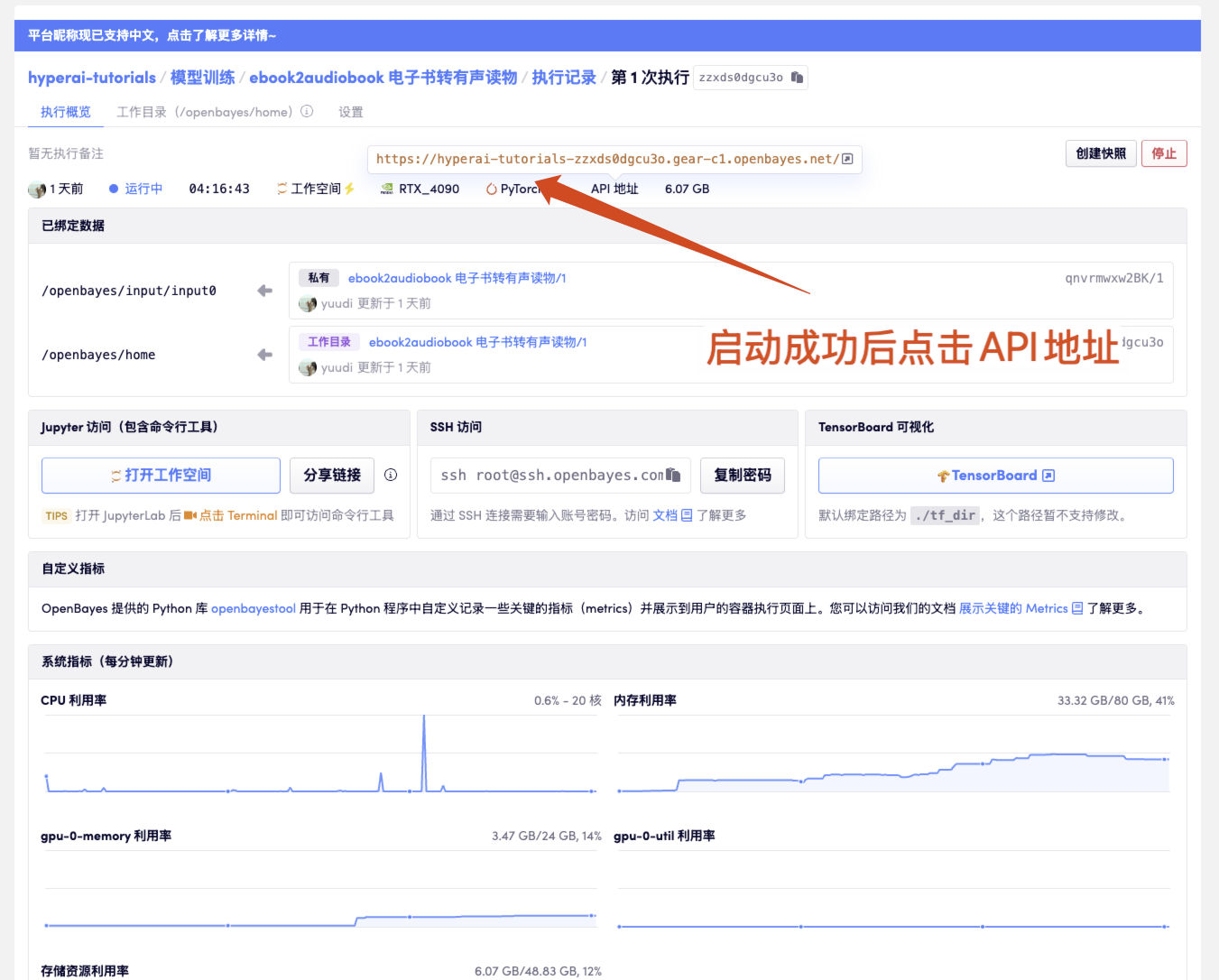
1. Starten Sie den Container
Klicken Sie dann auf die API-Adresse, um die Weboberfläche aufzurufen
2. Prozessdemonstration
Bitte beachten Sie:
- Dieses Projekt hat einen „Modellladevorgang“, der etwa 3-4 Minuten dauert;
- Wenn nach der Generierung des Fortschrittsbalkens das Online-Audio nicht angezeigt werden kann, aktualisieren Sie bitte die Webseite oder laden Sie es zur Anzeige auf Ihren lokalen Computer herunter.
- Bei Verwendung einer TXT-Datei wird nur die erste Zeile gelesen.
- Bitte beachten Sie, dass die Sprache des E-Books mit der ausgewählten Sprache übereinstimmen muss, da sonst eine „nicht-menschliche Sprache“ generiert wird;
- In diesem Projekt speichert Fine Tuned Models nur das Standardmodell im Cache.
Erforderlich:
- E-Book-Dokument
- Sprache auswählen

Abbildung 1 Hauptprozess
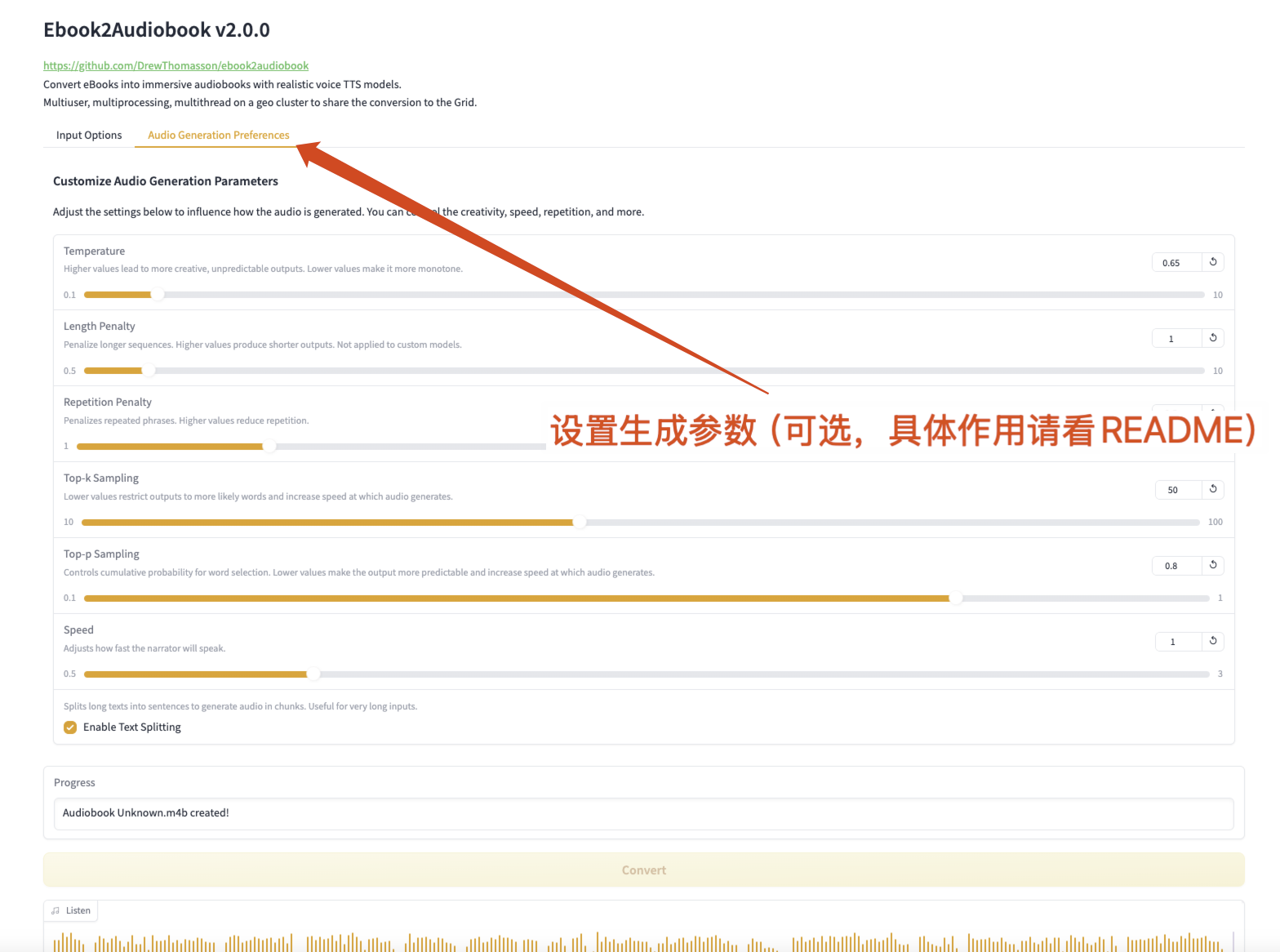
Abbildung 2 Parameterparameter generieren
Parameter generieren
- Temperatur: 0.65
- Höhere Werte erzeugen eine kreativere und unvorhersehbarere Ausgabe, niedrigere Werte machen die Ausgabe monotoner.
- Längenstrafe: Längere Sequenzen bestrafen
- Höhere Werte erzeugen eine kürzere Ausgabe (nicht für benutzerdefinierte Modelle geeignet).
- Wiederholungsstrafe: Wiederholte Phrasen bestrafen
- Höhere Werte reduzieren Wiederholungen.
- Top-k-Stichprobenverfahren: Niedrigere Werte beschränken die Ausgabe auf wahrscheinlichere Wörter und beschleunigen so die Audiogenerierung.
- Top-p-Stichproben: Kontrollieren Sie die kumulative Wahrscheinlichkeit der Wortauswahl
- Niedrigere Werte machen die Ausgabe vorhersehbarer und generieren Audio schneller.
- Erzählergeschwindigkeit: Passen Sie die Sprechgeschwindigkeit des Erzählers an.
- Textaufteilung: Teilen Sie langen Text in Sätze auf, um Audioblöcke zu generieren.
- Gut für sehr lange Eingaben.
- Textaufteilung aktivieren: Textaufteilung aktivieren.
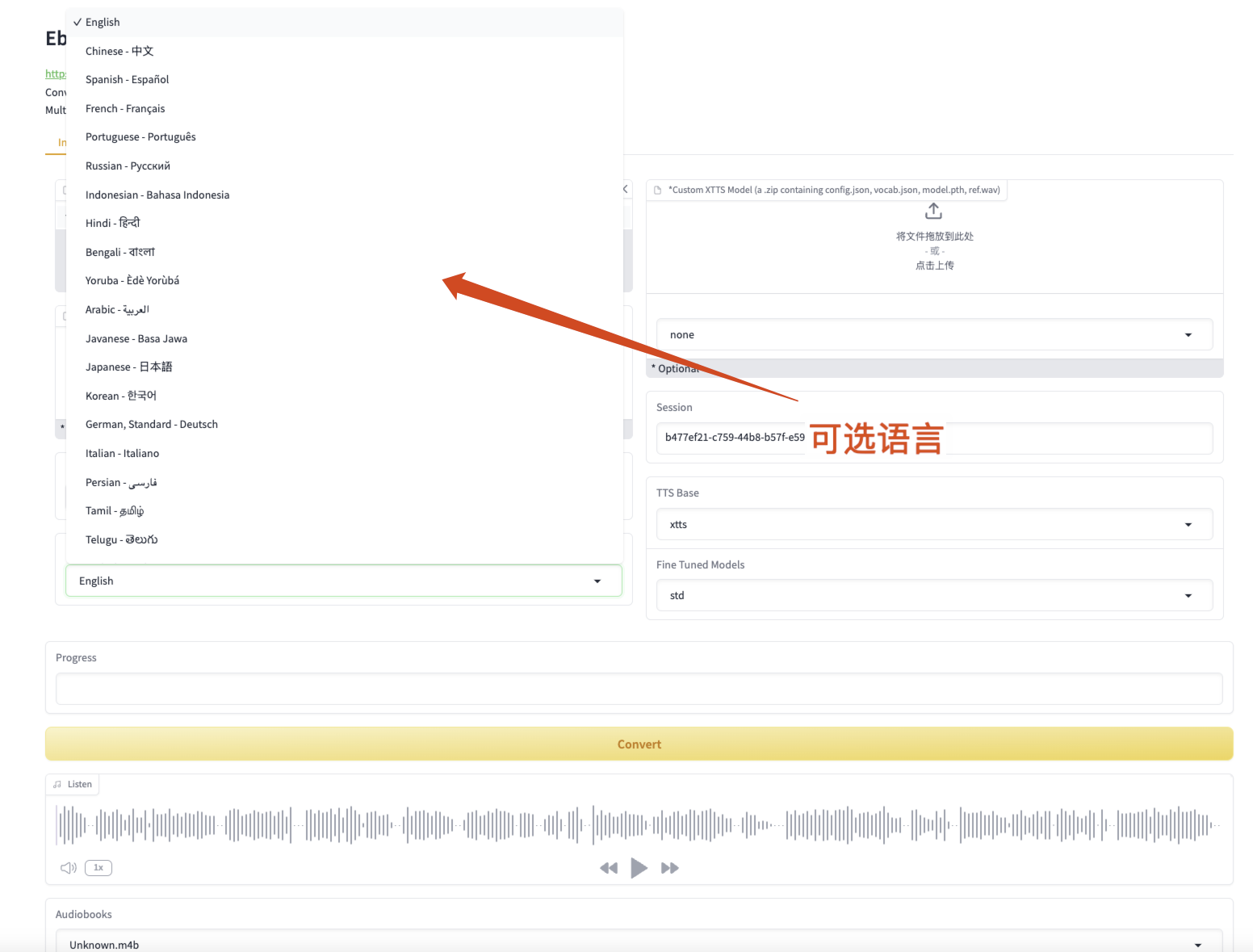
Abbildung 3 Optionale Sprachen
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.