Command Palette
Search for a command to run...
Fish Speech v1.4 Demo Des Tools Zum Klonen Von Stimmen – Text in Sprache
Einführung in das Tutorial

Zu den Hauptfunktionen von Fish Speech gehören Text-to-Speech, Unterstützung mehrerer Sprachen, Sprachanpassung, eine hochwertige Soundbibliothek und kostenlose Open Source. Es eignet sich für eine Vielzahl von Szenarien, wie etwa Inhaltserstellung, Bildung, Kundendienst, Zusatztools usw. Das Modell bietet außerdem Unterstützung für die API-Integration und Feinabstimmung des Modells, sodass Benutzer es entsprechend ihren Anforderungen anpassen und optimieren können.
Die neueste Version 1.4 hat bedeutende Durchbrüche bei der Unterstützung mehrerer Sprachen und der Leistung erzielt und die Menge der Trainingsdaten hat sich auf 700.000 Stunden verdoppelt., unterstützt 8 Hauptsprachen, darunter Englisch, Chinesisch, Deutsch, Japanisch, Französisch, Spanisch, Koreanisch und Arabisch. Die neue Version führt außerdem die sofortige Stimmklonierung ein, sodass Benutzer schnell einen bestimmten Stimmstil replizieren können, und bietet flexible Bereitstellungsoptionen und API-Dienste.
In diesem Tutorial wurden das Modell und die Umgebung bereitgestellt. Sie können Sprachklonierungs- oder Text-to-Speech-Aufgaben direkt gemäß den Anweisungen im Tutorial durchführen.
Wie man läuft
1. 首先克隆容器, 按步骤启动容器
2. 复制生成的 API 地址到浏览器即可使用
3. 该教程主要包含 2 个功能:文本转语音和声音克隆
3.1 文本转语音:在「Input Text」输入生成的文本,点击「Generate」即可生成结果

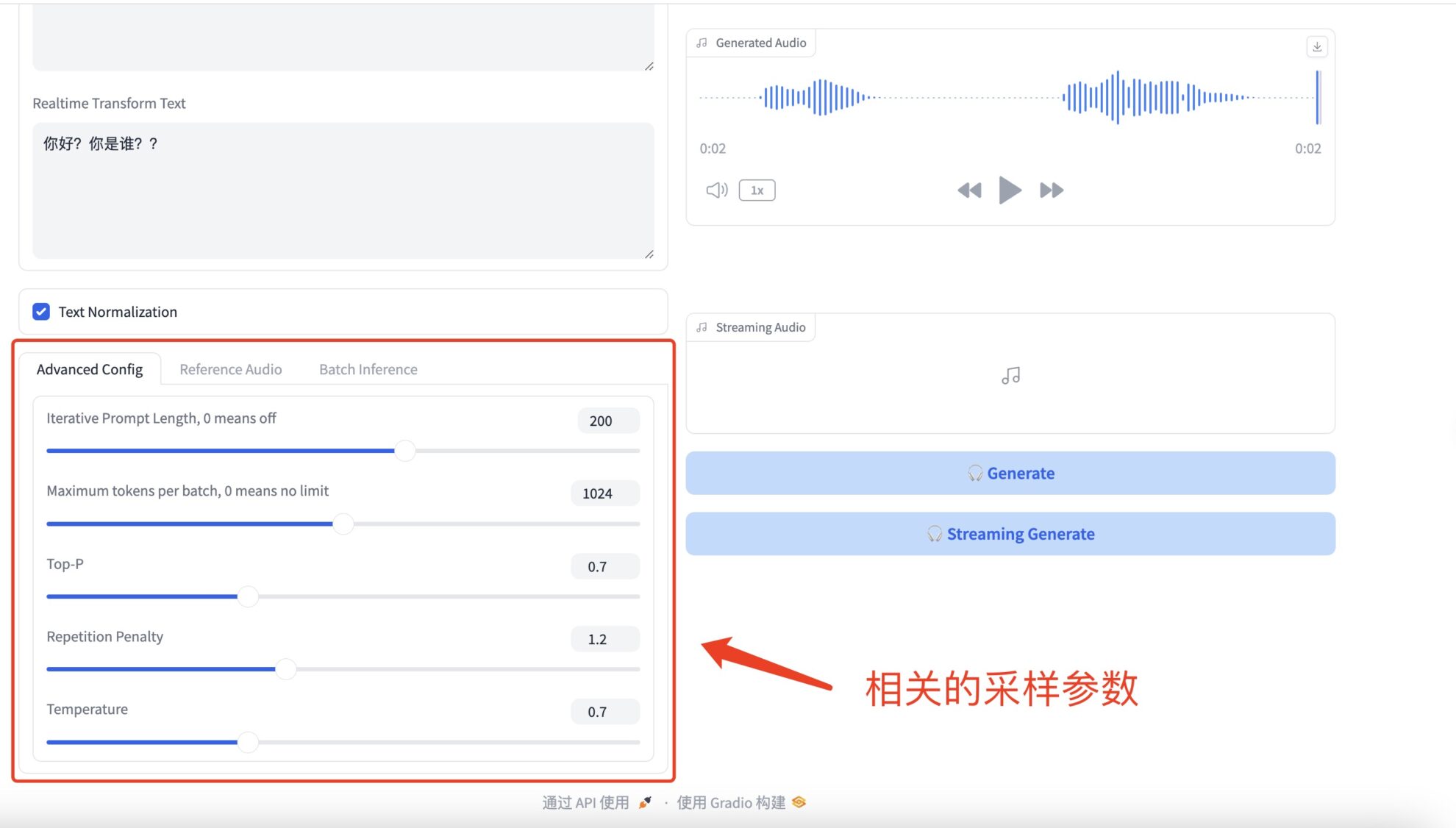
* Advanced Configs
相关的采样参数具体如下:
- Iterative Eingabeaufforderungslänge: bezieht sich auf die Länge des vorherigen Textes, die das Modell bei der Textgenerierung berücksichtigt. Wenn ein Wert ungleich Null festgelegt ist, berücksichtigt das Modell bei jedem Generierungsschritt die angegebene Anzahl neuer Wörter oder Token als Kontext. Wenn der Wert auf 0 gesetzt ist, ist diese Funktion deaktiviert und das Modell kann den gesamten verfügbaren Kontext berücksichtigen oder die Kontextlänge basierend auf anderen Parametern wie der Modellfenstergröße festlegen.
- Die maximale Anzahl an Token pro Stapel begrenzt die maximale Anzahl an Token, die das Modell in jedem Stapel generieren kann. Tags beziehen sich normalerweise auf Wörter, Satzzeichen usw. Wenn der Wert auf 0 gesetzt ist, gibt es keine Begrenzung und das Modell generiert Text mit der erforderlichen Länge oder bis die interne maximale Längenbeschränkung des Modells erreicht ist.
- Top-P (auch als Kernel-Sampling oder Wahrscheinlichkeits-Sampling bezeichnet) ist eine Textgenerierungsstrategie, bei der das Modell bei der Generierung jedes neuen Wortes nur die kleinste Menge an Wörtern berücksichtigt, deren kumulative Wahrscheinlichkeit größer als P ist. Dies bedeutet, dass das Modell das nächste Wort aus diesem Satz zufällig auswählt, wodurch die Vielfalt des generierten Textes erhöht wird und gleichzeitig die Generierung irrelevanter Wörter mit geringer Wahrscheinlichkeit vermieden wird.
- Die Wiederholungsstrafe wird verwendet, um sich wiederholende Inhalte im generierten Text zu reduzieren. Wenn das Modell dazu neigt, bereits generierte Wörter oder Phrasen zu wiederholen, kann die Anwendung dieses Parameters die Wahrscheinlichkeit der Auswahl dieser Wörter verringern. Dies geschieht durch Anpassen (normalerweise Senken) der Wahrscheinlichkeitswerte der bereits generierten Wörter, wodurch das Modell dazu angeregt wird, andere Wörter auszuwählen.
- Die Temperatur steuert die Zufälligkeit des generierten Textes.
3.2 声音克隆:选择「Reference Audio」并点击「Enable Reference Audio」,
上传「Reference Audio(参考音频)」,以及「Reference Text(参考文本)」,在「Input Text」输入生成的文本,点击「Generate」即可生成声音克隆结果

4. 其他参数说明
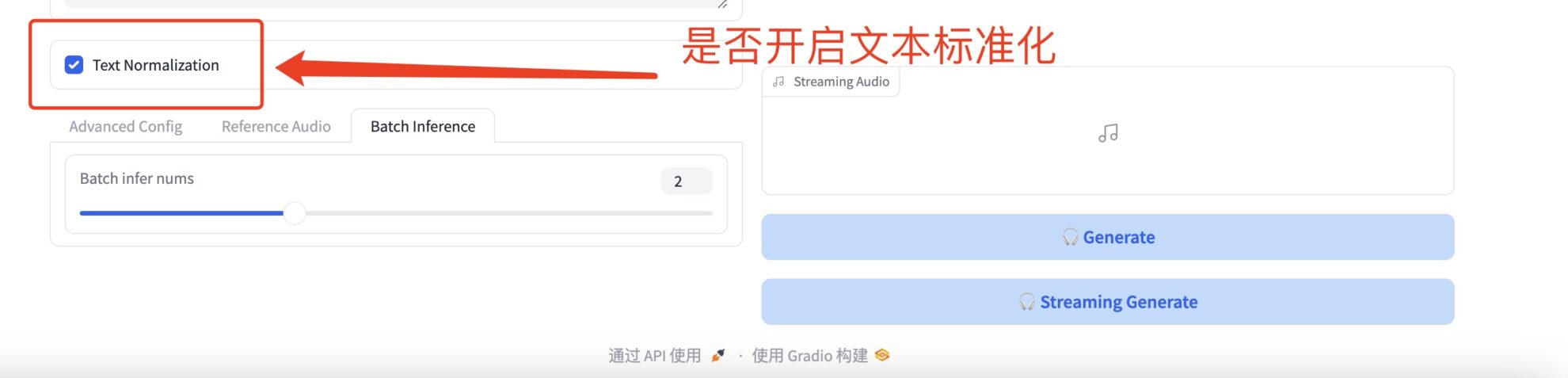
* Text Normalization
是否开启文本标准化(例如日期、固话、金钱等等)
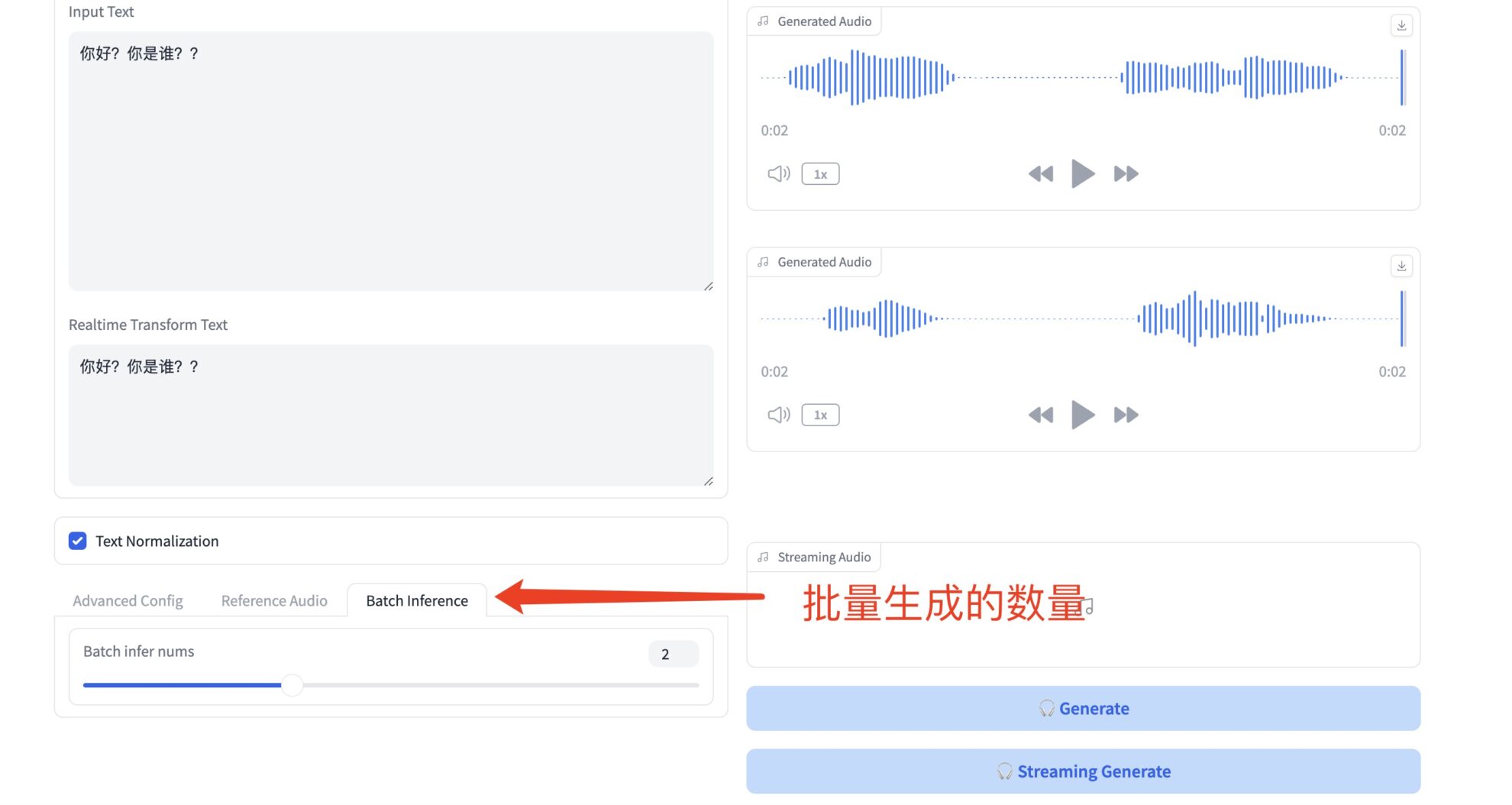
* Batch Inference
设置生成语音数量
Austausch und Diskussion
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【教程交流】入群探讨各类技术问题、分享应用效果↓

KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.