Das von Microsoft Research im April 2025 veröffentlichte BitNet-b1.58-2B-4T stellt einen bedeutenden Fortschritt im Bereich der künstlichen Intelligenz dar. Als erstes Open-Source-natives 1-Bit-Modell für große Datenmengen überwindet es die Einschränkungen herkömmlicher Quantisierungstechniken und beweist, dass Modelle mit geringerer Präzision den Rechenaufwand deutlich reduzieren und gleichzeitig die Leistung beibehalten können. Dies ebnet den Weg für den lokalen Einsatz von KI auf Edge-Geräten. Die zugehörige Forschungsarbeit finden Sie hier: Technischer Bericht zu BitNet b1.58 2B4T .
Dieses Tutorial verwendet BitNet-b1.58-2B-4T als Demonstration, das Bild verwendet PyTorch 2.6-2204 und die Rechenressource verwendet RTX 4090.
2. Kernfunktionen
Effiziente Architektur: Durch die Verwendung ternär quantisierter Gewichte (-1, 0, +1) benötigt jedes Gewicht nur 1,58 Bit Speicherplatz. In Kombination mit 8-Bit-Aktivierungswerten (W1.58A8-Konfiguration) beträgt die nicht eingebettete Speichernutzung nur 0,4 GB, was viel niedriger ist als bei ähnlichen Modellen (wie z. B. 1,4 GB bei Gemma-3 1B).
Trainingsinnovation: Training von Grund auf (nicht nach der Quantisierung), Einführung von BitLinear-Schichten, quadrierten ReLU-Aktivierungsfunktionen und RoPE-Positionskodierung, um die Stabilität des Trainings mit geringer Präzision zu gewährleisten.
Vorteil beim Energieverbrauch: Die CPU-Inferenzlatenz beträgt nur 29 Millisekunden und der Energieverbrauch liegt bei lediglich 0,028 Joule/Token, was einen effizienten Betrieb auf CPUs wie Apple M2 unterstützt.
3. Bedienungsschritte
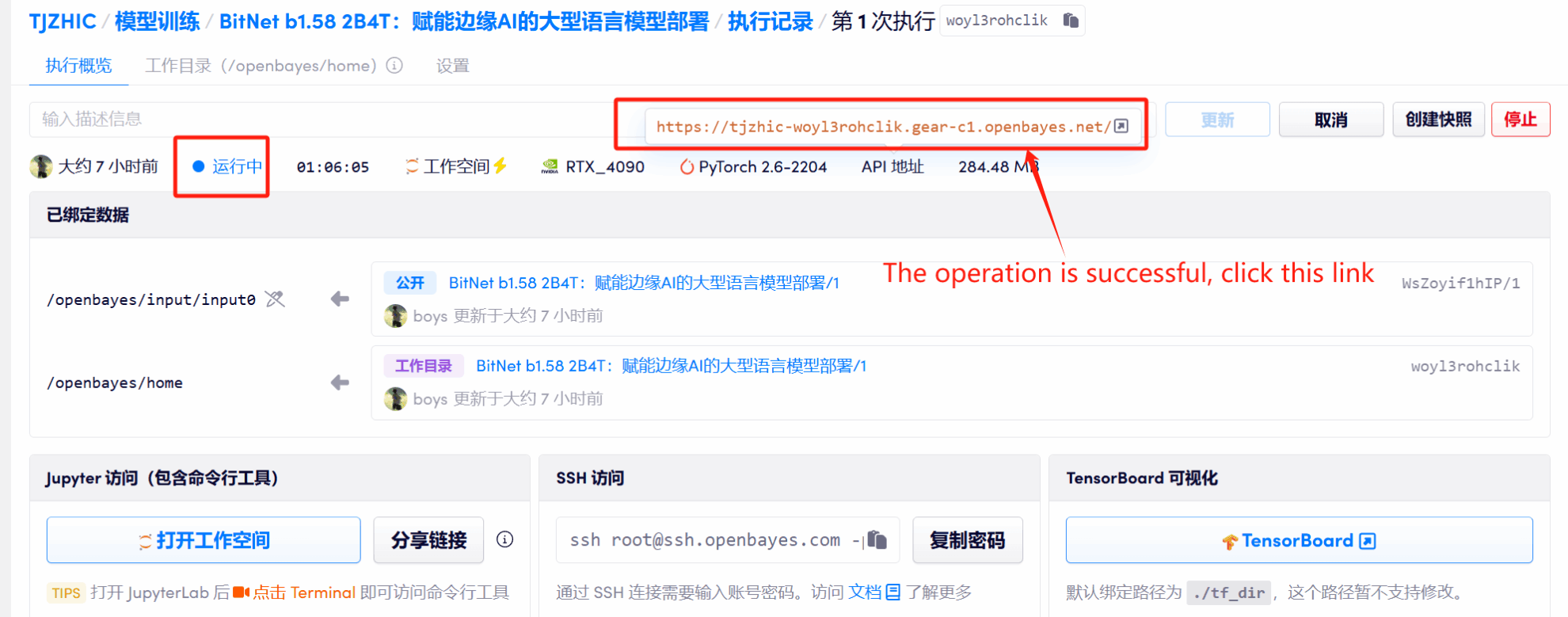
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 1–2 Minuten und aktualisieren Sie die Seite.
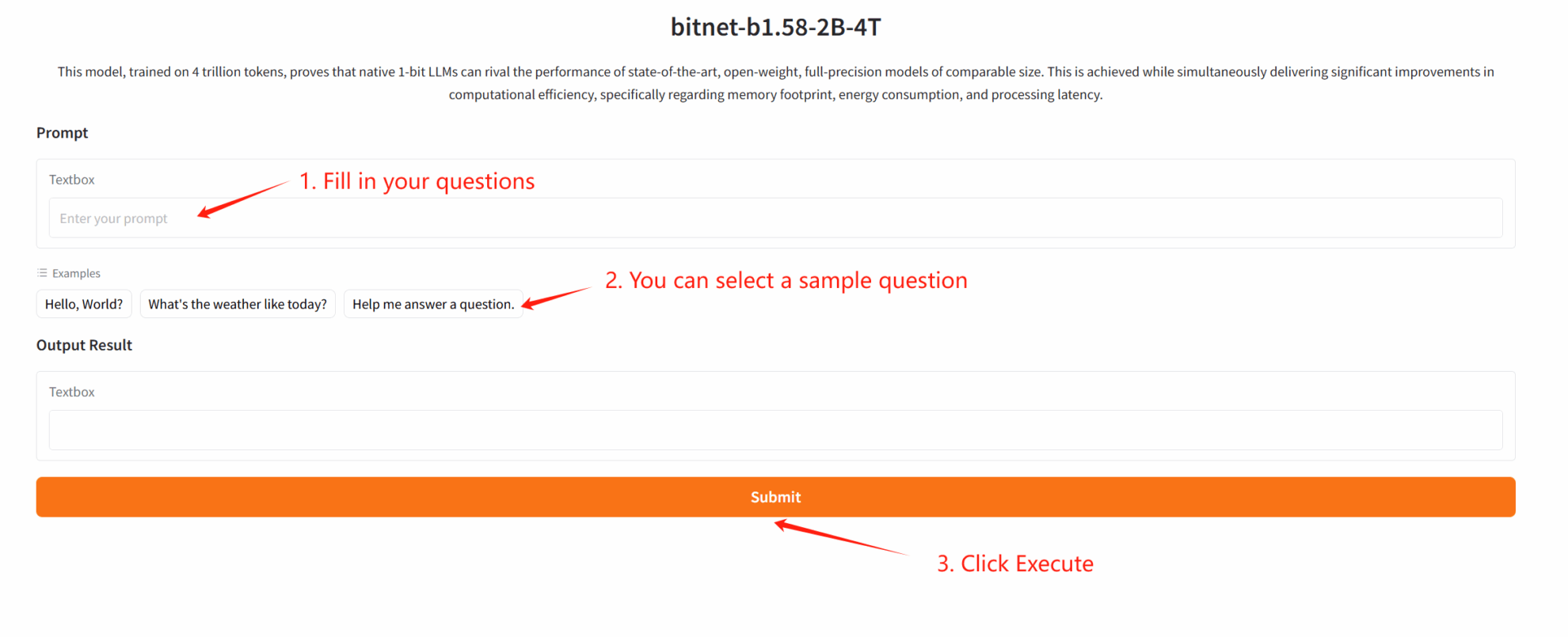
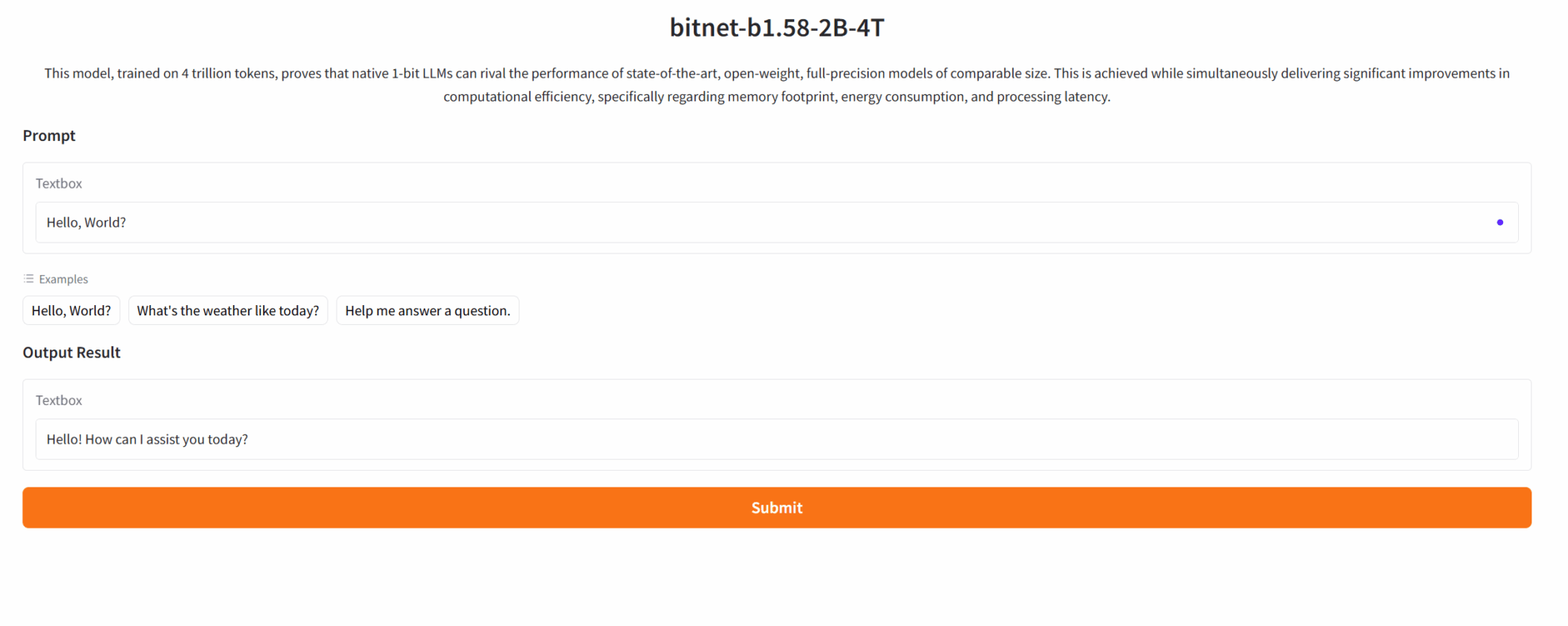
2. Funktionsdemonstration
Austausch und Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓
Dieses Notebook wurde von Community-Nutzern beigesteuert und dient ausschließlich Bildungs- und Informationszwecken. Bei urheberrechtlichen Bedenken kontaktieren Sie uns bitte unter [email protected] zur umgehenden Prüfung und Entfernung.
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.
Das von Microsoft Research im April 2025 veröffentlichte BitNet-b1.58-2B-4T stellt einen bedeutenden Fortschritt im Bereich der künstlichen Intelligenz dar. Als erstes Open-Source-natives 1-Bit-Modell für große Datenmengen überwindet es die Einschränkungen herkömmlicher Quantisierungstechniken und beweist, dass Modelle mit geringerer Präzision den Rechenaufwand deutlich reduzieren und gleichzeitig die Leistung beibehalten können. Dies ebnet den Weg für den lokalen Einsatz von KI auf Edge-Geräten. Die zugehörige Forschungsarbeit finden Sie hier: Technischer Bericht zu BitNet b1.58 2B4T .
Dieses Tutorial verwendet BitNet-b1.58-2B-4T als Demonstration, das Bild verwendet PyTorch 2.6-2204 und die Rechenressource verwendet RTX 4090.
2. Kernfunktionen
Effiziente Architektur: Durch die Verwendung ternär quantisierter Gewichte (-1, 0, +1) benötigt jedes Gewicht nur 1,58 Bit Speicherplatz. In Kombination mit 8-Bit-Aktivierungswerten (W1.58A8-Konfiguration) beträgt die nicht eingebettete Speichernutzung nur 0,4 GB, was viel niedriger ist als bei ähnlichen Modellen (wie z. B. 1,4 GB bei Gemma-3 1B).
Trainingsinnovation: Training von Grund auf (nicht nach der Quantisierung), Einführung von BitLinear-Schichten, quadrierten ReLU-Aktivierungsfunktionen und RoPE-Positionskodierung, um die Stabilität des Trainings mit geringer Präzision zu gewährleisten.
Vorteil beim Energieverbrauch: Die CPU-Inferenzlatenz beträgt nur 29 Millisekunden und der Energieverbrauch liegt bei lediglich 0,028 Joule/Token, was einen effizienten Betrieb auf CPUs wie Apple M2 unterstützt.
3. Bedienungsschritte
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 1–2 Minuten und aktualisieren Sie die Seite.
2. Funktionsdemonstration
Austausch und Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓
Dieses Notebook wurde von Community-Nutzern beigesteuert und dient ausschließlich Bildungs- und Informationszwecken. Bei urheberrechtlichen Bedenken kontaktieren Sie uns bitte unter [email protected] zur umgehenden Prüfung und Entfernung.
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.