Die in diesem Tutorial verwendeten Rechenressourcen sind Dual-Card-A6000.
OpenCodeReasoning-Nemotron-32B, veröffentlicht von NVIDIA am 9. Mai 2025, ist ein leistungsstarkes, speziell für Codeanalyse und -generierung entwickeltes Sprachmodell für große Codemengen. Es ist die Flaggschiffversion der OpenCodeReasoning (OCR)-Modellsuite und unterstützt eine Kontextlänge von 32.000 Tags. Zugehörige Forschungsarbeiten sind verfügbar. OpenCodeReasoning: Fortschrittliche Datendestillation für wettbewerbsfähiges Programmieren .
2. Projektbeispiele
3. Bedienungsschritte
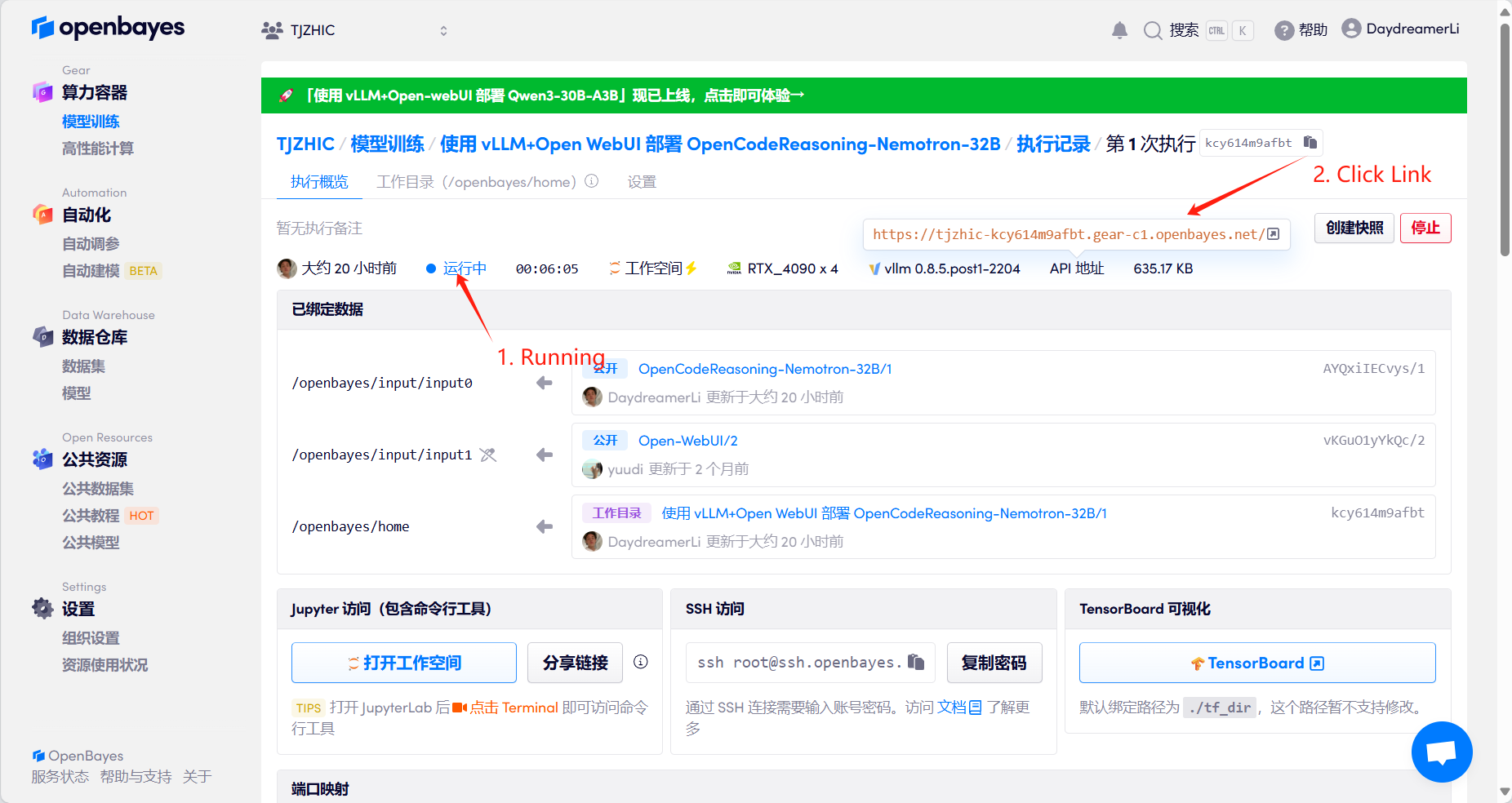
1. Starten Sie den Container
Wenn „Modell“ nicht angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 2–3 Minuten und aktualisieren Sie die Seite.
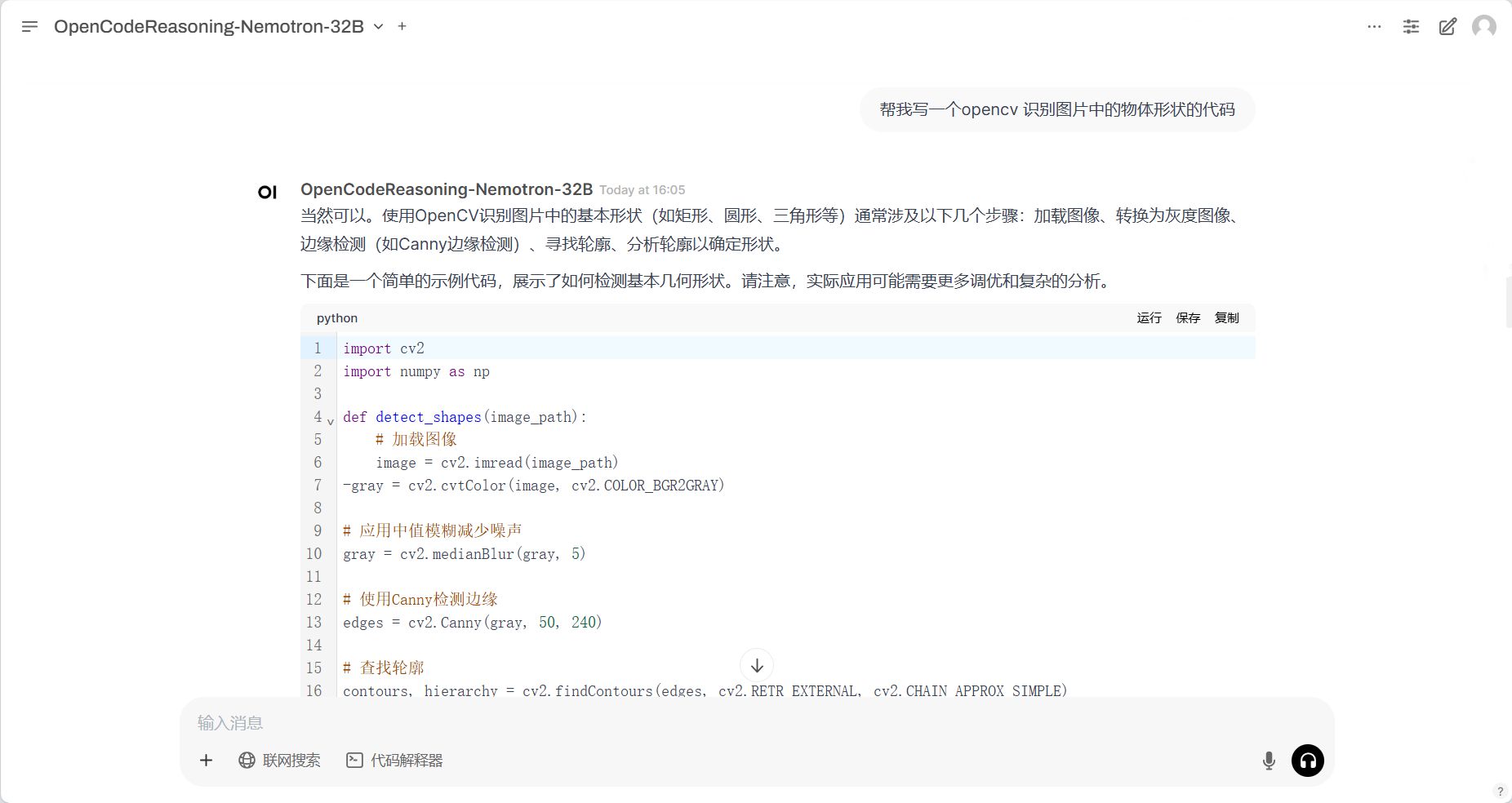
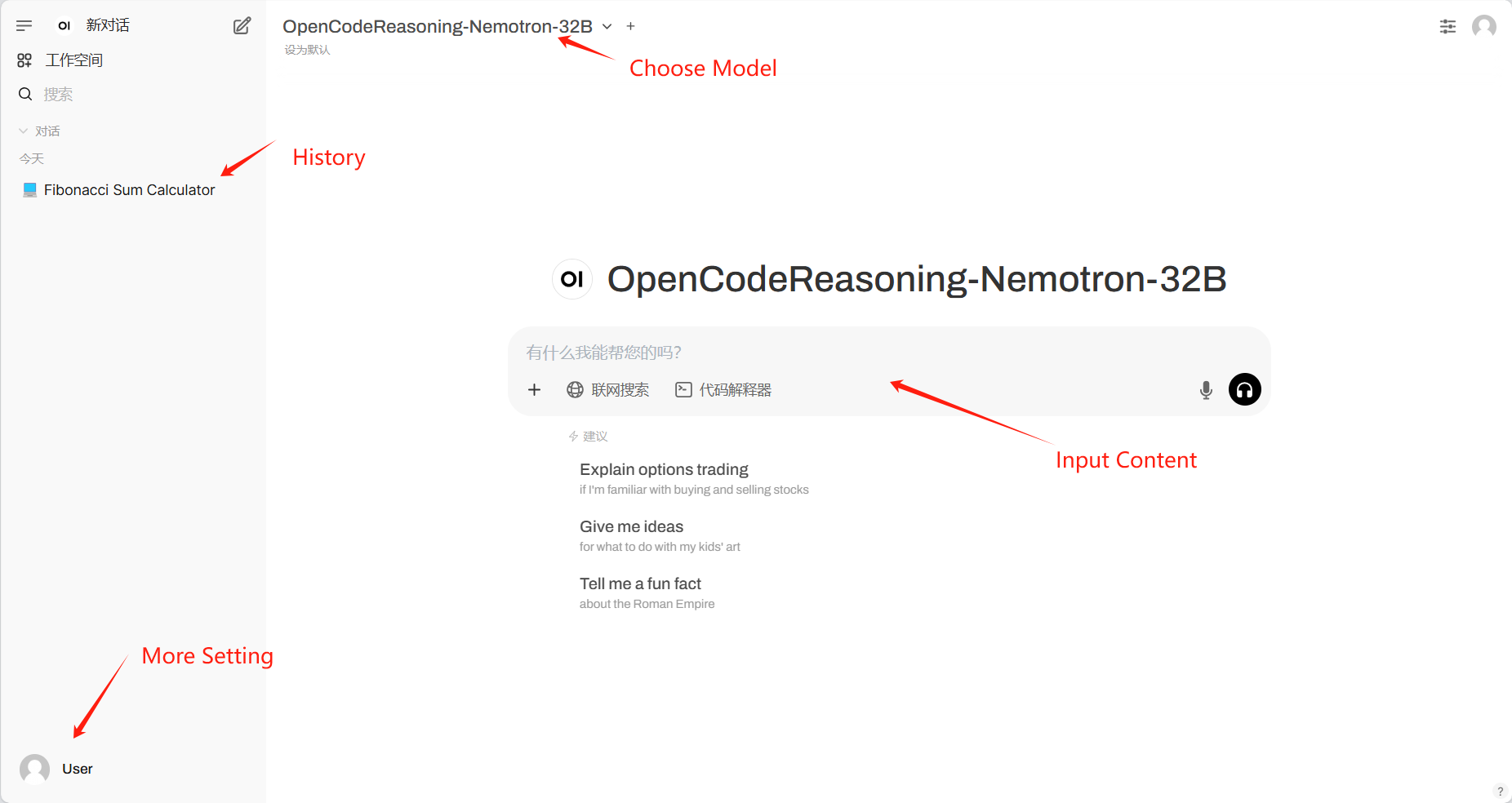
2. Nachdem Sie die Webseite aufgerufen haben, können Sie ein Gespräch mit dem Modell beginnen
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓
Zitationsinformationen
Dank an den Github-Benutzer SuperYang Bereitstellung dieses Tutorials. Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@article{ahmad2025opencodereasoning,
title={OpenCodeReasoning: Advancing Data Distillation for Competitive Coding},
author={Wasi Uddin Ahmad, Sean Narenthiran, Somshubra Majumdar, Aleksander Ficek, Siddhartha Jain, Jocelyn Huang, Vahid Noroozi, Boris Ginsburg},
year={2025},
eprint={2504.01943},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2504.01943},
}
Dieses Notebook wurde von Community-Nutzern beigesteuert und dient ausschließlich Bildungs- und Informationszwecken. Bei urheberrechtlichen Bedenken kontaktieren Sie uns bitte unter [email protected] zur umgehenden Prüfung und Entfernung.
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.
Die in diesem Tutorial verwendeten Rechenressourcen sind Dual-Card-A6000.
OpenCodeReasoning-Nemotron-32B, veröffentlicht von NVIDIA am 9. Mai 2025, ist ein leistungsstarkes, speziell für Codeanalyse und -generierung entwickeltes Sprachmodell für große Codemengen. Es ist die Flaggschiffversion der OpenCodeReasoning (OCR)-Modellsuite und unterstützt eine Kontextlänge von 32.000 Tags. Zugehörige Forschungsarbeiten sind verfügbar. OpenCodeReasoning: Fortschrittliche Datendestillation für wettbewerbsfähiges Programmieren .
2. Projektbeispiele
3. Bedienungsschritte
1. Starten Sie den Container
Wenn „Modell“ nicht angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 2–3 Minuten und aktualisieren Sie die Seite.
2. Nachdem Sie die Webseite aufgerufen haben, können Sie ein Gespräch mit dem Modell beginnen
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓
Zitationsinformationen
Dank an den Github-Benutzer SuperYang Bereitstellung dieses Tutorials. Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@article{ahmad2025opencodereasoning,
title={OpenCodeReasoning: Advancing Data Distillation for Competitive Coding},
author={Wasi Uddin Ahmad, Sean Narenthiran, Somshubra Majumdar, Aleksander Ficek, Siddhartha Jain, Jocelyn Huang, Vahid Noroozi, Boris Ginsburg},
year={2025},
eprint={2504.01943},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2504.01943},
}
Dieses Notebook wurde von Community-Nutzern beigesteuert und dient ausschließlich Bildungs- und Informationszwecken. Bei urheberrechtlichen Bedenken kontaktieren Sie uns bitte unter [email protected] zur umgehenden Prüfung und Entfernung.
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.