Command Palette
Search for a command to run...
Zusammenstellung Von Datensätzen | Open-Source-Inferenzdatensätze Von NVIDIA, OpenAI Und Verschiedenen Forschungseinrichtungen, Die Mathematik, Panorama-Weltraum, Wiki-Fragenbeantwortung, Forschungsaufgaben, Visuellen Gesunden Menschenverstand usw. abdecken.

Da sich große Modelle von der bloßen Fähigkeit, „sprechen und schreiben zu können“, hin zur Fähigkeit, „logisch zu denken und zu argumentieren“, entwickeln, wird die Bedeutung von Daten neu definiert.
Früher stützten umfangreiche, allgemeine Korpora die Ausdruckskraft von Sprachmodellen; heute liegt die eigentliche Herausforderung für die Leistungsfähigkeit von Modellen zunehmend in der Verarbeitung von Daten mit klarer Struktur, strenger Logik und mehrstufigen Deduktionsprozessen. Ob komplexe mathematische Probleme, domänenübergreifende Wissensfragen oder mehrstufige Entscheidungsfindung und Werkzeugaufrufe – all dies ist auf hochwertige Datensätze für logisches Denken angewiesen.
Inferenzdatensätze können sich auf Mathematik und Logik konzentrieren oder komplexe Schlussfolgerungsketten durch Synthese konstruieren. Sie können auch zur Beurteilung von Multitasking-Fähigkeiten oder als wissenschaftliche Benchmarks und zur Optimierung von Frage-Antwort-Systemen verwendet werden. Allerdings weisen diese Datenressourcen eine erhebliche Fragmentierung auf und liegen oft in unterschiedlichen Formaten vor, was ihre einheitliche Nutzung erschwert. Dies führt dazu, dass viele Entwickler und Forscher viel Zeit allein mit der Datensuche verbringen.
daher,HyperAI hat eine Sammlung hochwertiger Inferenzdatensätze zusammengestellt, die Multi-Domain- und Multi-Task-Inferenz, synthetische Inferenz-Trainingsdaten, wissenschaftliche Forschungs-Benchmarks und groß angelegte Frage-Antwort-Daten abdecken.Es unterstützt auch das Herunterladen oder die Online-Nutzung von Datensätzen und senkt so die Einstiegshürde für die Verwendung von Inferenzdatensätzen.
Weitere hochwertige Datensätze:
Open-RL Inferenzproblem-Datensatz
* Online nutzen:
Open-RL ist ein von Turing im Jahr 2026 veröffentlichter Datensatz für domänenübergreifende Denkprobleme, der unabhängige, überprüfbare und explizite STEM-Denkprobleme in den Bereichen Physik, Mathematik, Biologie und Chemie enthält.
Jedes Problem erfordert mehrstufiges Denken, beinhaltet symbolische Operationen und/oder numerische Berechnungen und hat eine objektiv überprüfbare Endlösung. Dieser Datensatz eignet sich für die Feinabstimmung von Reinforcement Learning, die Modellierung von Belohnungen, das ergebnisorientierte Training und das Benchmarking überprüfbarer Schlussfolgerungen.
CHIMERA Allgemeines Inferenz-Synthetik-Datensatz
* Online nutzen:
CHIMERA ist ein synthetischer Datensatz für logisches Denken, der speziell für das Training von Denkfähigkeiten entwickelt wurde und ein breites Spektrum an MINT-Fächern abdeckt sowie lange Gedankenketten (CoT) bereitstellt.
Dieser Datensatz enthält 9.225 Fragen aus acht Fachgebieten (Mathematik, Informatik, Chemie, Physik, Literatur, Geschichte, Biologie und Phonetik). Alle Beispiele wurden mithilfe eines großen Sprachmodells (LLM) generiert und automatisch ohne manuelle Annotation validiert.
Themenverteilung:
* Mathematik: 4.452
*Informatik: 1.303
*Chemie: 1.102
*Physik: 742
*Literatur: 504
*Geschichte: 422
*Biologie: 383
*Linguistik: 317
Nemotron-Math-v2 Datensatz für mathematische Inferenz
* Online nutzen:
Nemotron-Math-v2 ist ein Datensatz für mathematisches Schließen, der von der NVIDIA Corporation veröffentlicht wurde. Er wird hauptsächlich verwendet, um LLMs für strukturiertes mathematisches Schließen zu trainieren, die Unterschiede zwischen werkzeuggestütztem Schließen und reinem sprachlichem Schließen zu untersuchen und Systeme für kontextübergreifendes oder mehrspuriges Schließen zu entwickeln.
Dieser Datensatz enthält ca. 347.000 hochwertige mathematische Probleme und 7 Millionen modellgenerierte Inferenztrajektorien. Jedes Problem wird in sechs Konfigurationen gelöst: hohe/mittlere/niedrige Inferenztiefe und mit/ohne Python TIR. Die Lösungen werden anschließend mithilfe einer Pipeline validiert, die ein LLM als Arbitrator verwendet.
OmniSpatial Panoramic Spatial Reasoning Benchmark-Datensatz
* Online nutzen:
OmniSpatial ist ein umfassender Benchmark-Datensatz für räumliches Denken, der 2025 von der Tsinghua-Universität in Zusammenarbeit mit dem Shanghai Institute for Advanced Study in Space Technology, dem Shanghai Artificial Intelligence Laboratory und weiteren Institutionen veröffentlicht wurde. Die zugehörige Publikation trägt den Titel „OmniSpatial: Towards Comprehensive Spatial Reasoning Benchmark for Vision Language Models“ und zielt darauf ab, die Lücke in der Evaluierung des räumlichen Verständnisses von Bild-Sprach-Modellen zu schließen.
Dieser Datensatz umfasst ca. 1.533 Bild-Fragen-Antworten und deckt vier Hauptkategorien räumlicher Denkaufgaben ab: Dynamisches Denken, Komplexe räumliche Logik, Räumliche Interaktion und Perspektivenübernahme. Insgesamt sind 50 Teilaufgaben enthalten. Die Datenquellen sind vielfältig und umfassen Internetbilder, psychologische Tests und Fragen aus Fahrprüfungen. Die Annotationen wurden mehrfach geprüft, um Qualität und Diversität zu gewährleisten. Im Vergleich zu herkömmlichen Benchmarks verzichtet OmniSpatial auf vorlagenbasierte Konstruktion und bildet komplexe Szenarien aus der realen Welt besser ab. Es testet nicht nur grundlegende räumliche Beziehungen (wie vorne/hinten, links/rechts und Entfernung), sondern legt auch Wert auf Interaktionen mehrerer Objekte, Szenenwechsel und perspektivisches Denken.
Dieser Datensatz eignet sich zum Trainieren und Evaluieren der räumlichen Denkfähigkeiten großer multimodaler Modelle, insbesondere in Anwendungen wie intelligenter Navigation, erweiterter/virtueller Realität und dem Verständnis komplexer Szenen. Es handelt sich um einen umfassenden und anspruchsvollen standardisierten Benchmark-Datensatz.
FrontierScience Inference Research Task Evaluation Dataset
* Online nutzen:
FrontierScience ist ein Datensatz zur Bewertung von Schlussfolgerungs- und wissenschaftlichen Forschungsaufgaben, der von OpenAI im Jahr 2025 veröffentlicht wurde. Ziel ist die systematische Bewertung der Fähigkeiten großer Modelle in wissenschaftlichen Schlussfolgerungs- und Forschungsaufgaben auf Expertenniveau.
Dieser Datensatz verwendet einen Designmechanismus aus „Expertenerstellung + zweischichtiger Aufgabenstruktur + automatischem Bewertungsmechanismus“ und ist in zwei Teilmengen unterteilt, die zwei Arten von Fähigkeiten entsprechen: geschlossenes präzises Denken und offenes wissenschaftliches Denken.
Olympiade-Datensatz
Die ursprünglich von Medaillengewinnern und Nationalmannschaftstrainern der Internationalen Physik-, Chemie- und Biologie-Olympiade entworfenen Fragen haben einen Schwierigkeitsgrad, der mit internationalen Spitzenwettbewerben wie IPhO, IChO und IBO vergleichbar ist. Der Fokus liegt auf Aufgaben zum logischen Denken mit kurzen Antworten. Das Modell muss einen einzelnen numerischen Wert, einen algebraischen Ausdruck oder einen biologischen Begriff ausgeben, der unscharf zugeordnet werden kann, um die Überprüfbarkeit der Ergebnisse und die Stabilität der automatischen Auswertung zu gewährleisten.
Forschungsdatensatz
Die von Doktoranden, Postdoktoranden und Professoren verfassten Fragen simulieren Teilprobleme, die in der realen wissenschaftlichen Forschung auftreten können, und decken die drei Hauptgebiete der Physik, Chemie und Biologie ab. Jede Frage wird von einem differenzierten 10-Punkte-Bewertungssystem begleitet, das die Leistungsfähigkeit des Modells in mehreren Schlüsselaspekten bewertet, die über die reine Richtigkeit der Antwort hinausgehen. Dazu gehören die Vollständigkeit der Modellannahmen, die nachvollziehbaren Argumentationswege und die Zwischenergebnisse.
HotpotQA-Frage-Antwort-Datensatz
* Online nutzen:
Der HotpotQA-Datensatz ist ein umfangreicher Frage-Antwort-Datensatz aus der englischen Wikipedia mit 113.000 von Nutzern beigesteuerten Fragen. Um diese Fragen zu beantworten, müssen Sie die Einleitungsabschnitte zweier Wikipedia-Artikel konsultieren.
Jede Frage enthält zwei Leitsätze und eine Liste von Sätzen aus diesen Leitsätzen, die als notwendig erachtete Fakten zur Beantwortung der Frage liefern. Dieser Datensatz weist folgende Merkmale auf:
Um diese Frage beantworten zu können, ist die Suche und das logische Durchdenken mehrerer unterstützender Dokumente erforderlich;
* Die Probleme sind vielfältig und nicht durch eine bestehende Wissensbasis oder ein Wissensmodell eingeschränkt;
Dieser Datensatz liefert unterstützende Fakten auf Satzebene, die für das Schlussfolgern erforderlich sind und es QA-Systemen ermöglichen, unter strenger Aufsicht zu schlussfolgern und Vorhersagen zu interpretieren;
Dieser Datensatz stellt ein neuartiges Faktenvergleichsproblem dar, um die Fähigkeit eines QA-Systems zu testen, relevante Fakten zu extrahieren und notwendige Vergleiche anzustellen.
VCR-Datensatz zum visuellen gesunden Menschenverstand
* Online nutzen:
VCR steht für Visual Commonsense Reasoning und ist ein umfangreicher Datensatz für visuelles, gesundes Menschenverstand-Reasoning. Der Datensatz stellt anspruchsvolle Fragen zu Bildern und die Maschine muss zwei Teilaufgaben erfüllen: die Frage richtig beantworten und Gründe für die Rechtfertigung ihrer Antwort angeben.
Der VCR-Datensatz enthält eine große Anzahl von Fragen, darunter 212.000 für das Training, 26.000 für die Validierung und 25.000 für Tests. Antworten und Gründe stammen aus über 110.000 einzigartigen Filmszenen.

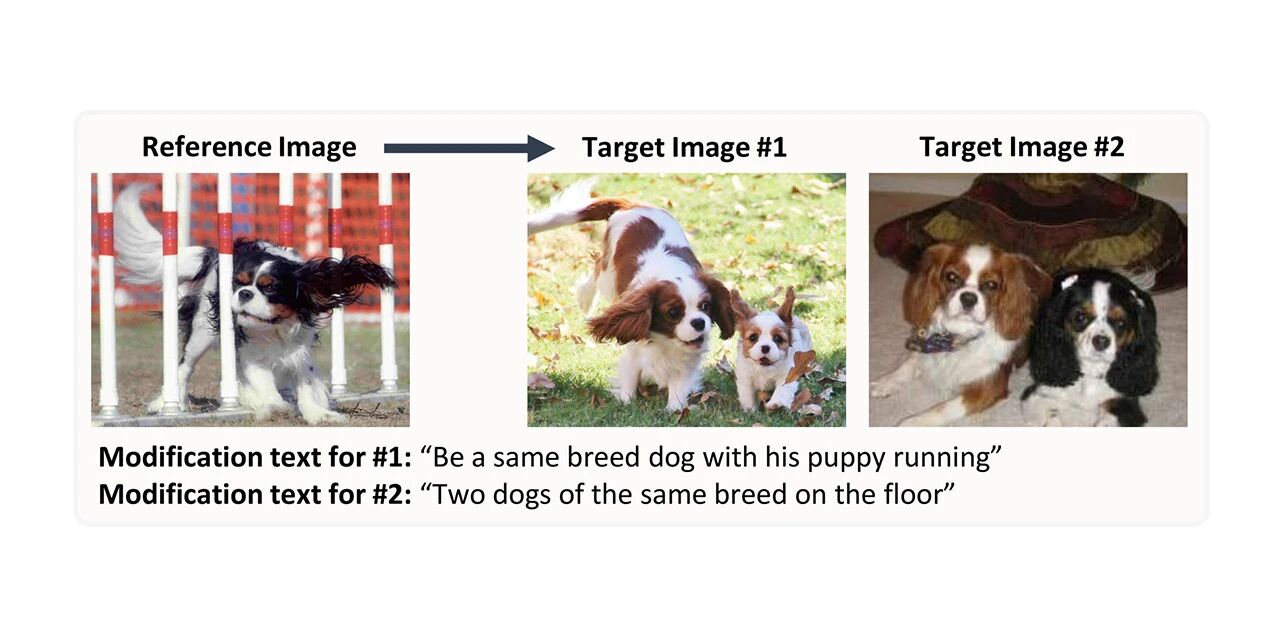
CIRR-Datensatz zur Bildsynthese und -abfrage
* Online nutzen:
CIRR steht für Compose Image Retrieval on Real-life images und enthält mehr als 36.000 Paare von Crowdsourcing-Bildern aus Open Domains und manuell generiertem, geändertem Text. Dieser Datensatz soll die zukünftige Forschung zum subtilen Denken über visuelle linguistische Konzepte und zum iterativen Abrufen mit Dialogen erleichtern. Dabei werden die Mängel vorhandener Datensätze behoben, indem ein größerer Schwerpunkt auf die Unterscheidung visuell ähnlicher Bilder in offenen Domänen gelegt wird.