Command Palette
Search for a command to run...
LoongBench-Benchmark-Datensatz Für Multi-Domain-Reasoning
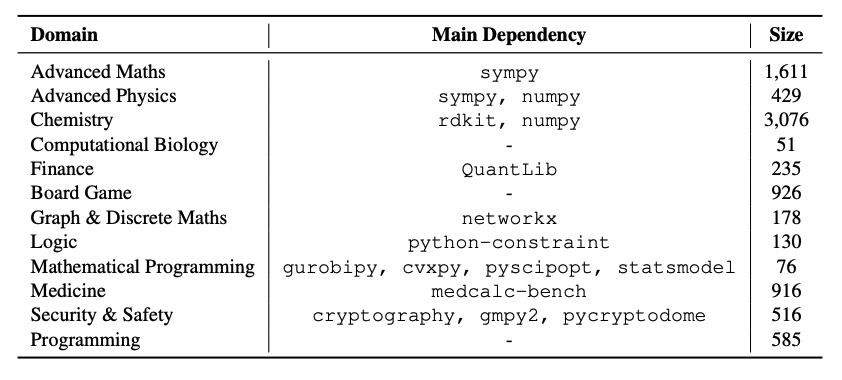
LoongBench ist ein Datensatz zur Bewertung des Schlussfolgerungsverhaltens in mehreren Domänen, der 2025 vom CAMEL-AI-Team veröffentlicht wurde. Die zugehörigen Ergebnisse des Papiers sind „Loong: Synthetisieren Sie lange Gedankenketten im großen Maßstab durch Verifizierer“, dessen Ziel es ist, LLM mit multidisziplinären, überprüfbaren Schulungs- und Bewertungsressourcen auszustatten. Der Datensatz enthält 8.729 Fragen in natürlicher Sprache aus zwölf schlussfolgerungsintensiven Bereichen wie höherer Mathematik, Physik, Chemie, Bioinformatik und Programmierung. Jede Probe enthält nicht nur ausführbaren Code und verifizierte Antworten, sondern auch die Problemstellung, einen detaillierten Denkprozess, die endgültige Lösung sowie Metadaten (Fragen-ID und Domäneninformationen) und Domänenbezeichnungen. Er eignet sich zum Trainieren und Benchmarking domänenübergreifender Denkfähigkeiten.
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.