Command Palette
Search for a command to run...
Chinesisch-LiPS-Datensatz Zur Multimodalen Spracherkennung
Chinese-LiPS ist ein multimodaler Spracherkennungsdatensatz, der 2025 vom Zhiyuan Research Institute und der Nankai University veröffentlicht wurde. Das zugehörige Ergebnis der Studie lautet: „Chinese-LiPS: Ein chinesischer audiovisueller Spracherkennungsdatensatz mit Lippenlese- und Präsentationsfolien“. Als erster chinesischer multimodaler Spracherkennungsdatensatz, der „Lippenleseinformationen + semantische Folieninformationen“ kombiniert, ist Chinese-LiPS auf komplexe Kontexte wie chinesische Erklärungen, Populärwissenschaften, Lehre und Wissensverbreitung ausgerichtet und fördert die Entwicklung der chinesischen multimodalen Spracherkennungstechnologie.
Datensatzfunktionen:
- Große Datenmenge:Chinese-LiPS hat eine Gesamtlänge von etwa 100 Stunden und enthält 36.208 hochwertige Sprachclips, die von 207 professionellen Sprechern mit guter Repräsentativität und Vielfalt aufgenommen wurden.
- Ein breites Themenspektrum abdecken: Der Inhalt deckt 9 beliebte Bereiche ab, darunter Wissenschaft und Technologie, Gesundheit und Wellness, Kultur und Geschichte, Tourismus und Erkundung, Automobilindustrie, Sportveranstaltungen usw. Die Themen sind gleichmäßig verteilt und spiegeln die Ausdrucksmerkmale und die Terminologiedichte im Kontext des tatsächlichen Unterrichts und der Erklärung vollständig wider.
- Hochwertige Diashow-Produktion:Fachexperten gestalten den Inhalt und beteiligen sich an der Kommentierung, um die Genauigkeit und Professionalität der Folientexte und Bildinformationen sicherzustellen. Der PPT-Inhalt ist klar strukturiert und ansprechend gestaltet und enthält umfangreiche Bilder und visuell semantische Informationen anstelle von bloßem Text.
- Hochwertige Videoaufzeichnung:Das Video wird von einem professionellen Sprecher in einer ruhigen Umgebung mit hochauflösenden Bildern aufgezeichnet und umfasst zwei Modi: Lippenlesevideo (720P) und Diavideo (1080P). Dadurch wird eine präzise Ausrichtung der Sprech- und Lippenbewegungen sowie eine konsistente und zuverlässige Datenqualität gewährleistet.
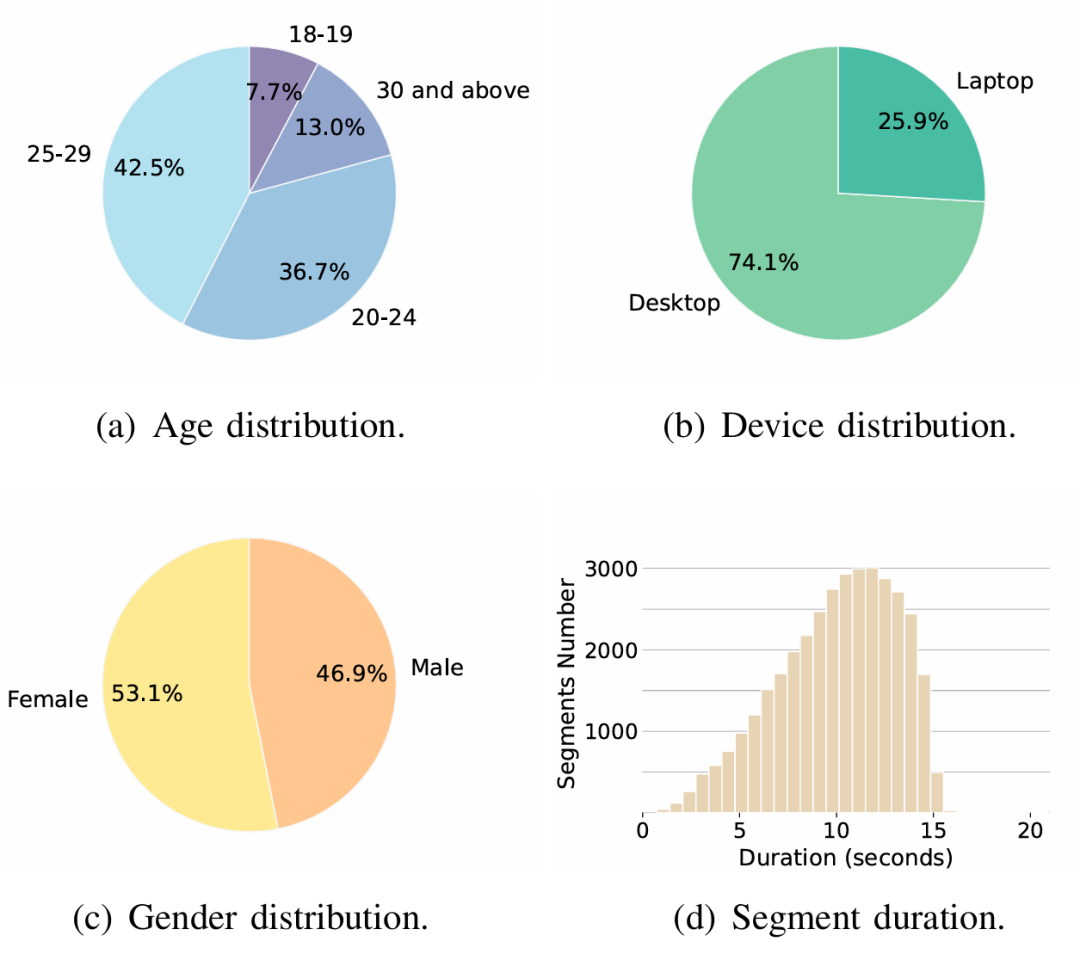
Datenverteilung
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.