Command Palette
Search for a command to run...
CC-OCR-Texterkennungsdatensatz
Datum
Größe
Organisation
Veröffentlichungs-URL
Paper-URL
Tags
Der CC-OCR-Datensatz wurde 2024 gemeinsam von der Alibaba Group, der Huazhong University of Science and Technology und der South China University of Technology entwickelt, um einen umfassenden und anspruchsvollen Benchmark für die Bewertung der Leistung großer multimodaler Modelle bei Texterkennungsaufgaben (OCR) bereitzustellen.CC-OCR: Ein umfassender und anspruchsvoller OCR-Benchmark zur Bewertung großer multimodaler Modelle im Bereich der Alphabetisierung".
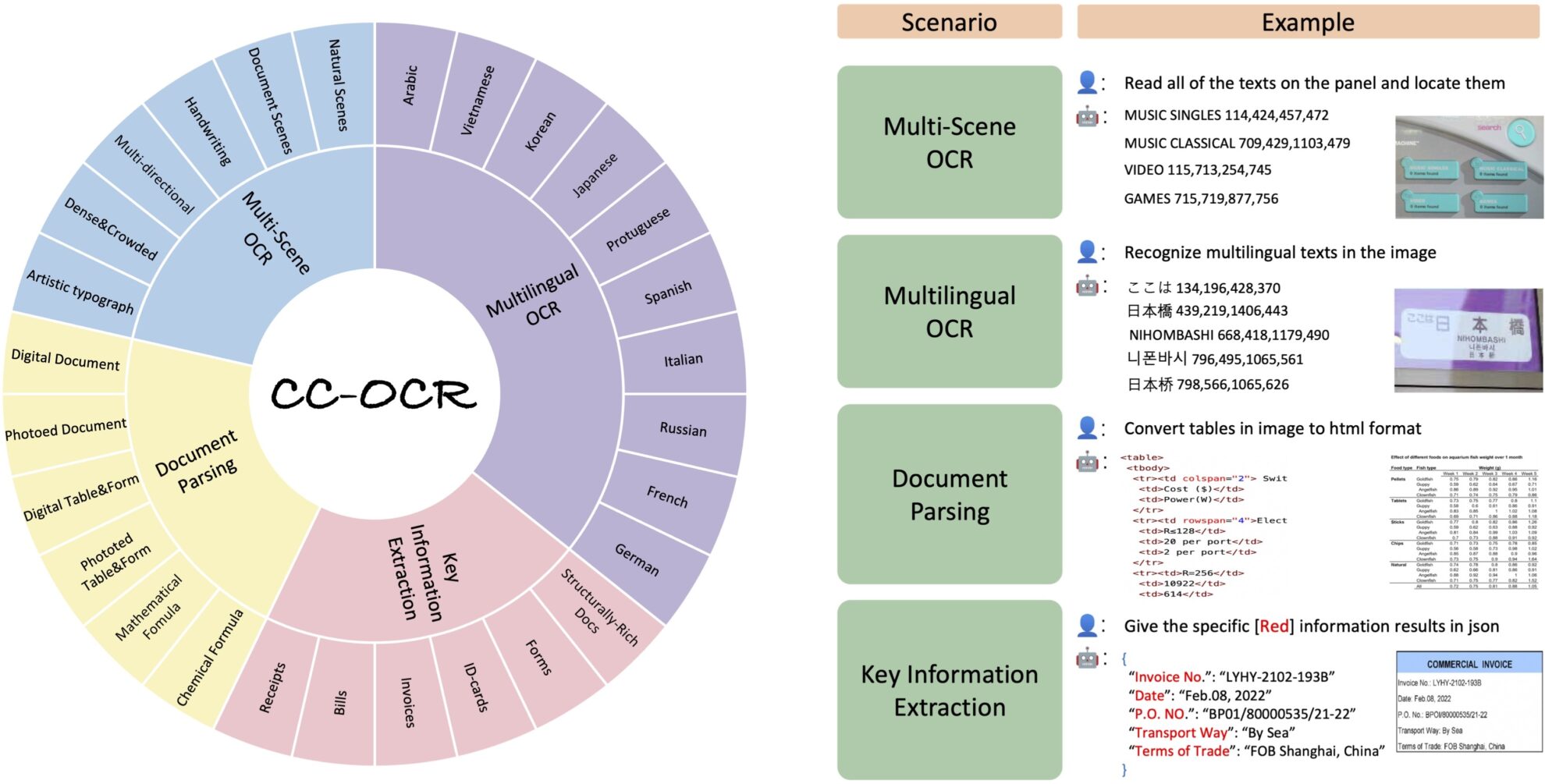
Der Datensatz deckt vier Kernaufgaben ab: Lesen von Texten in mehreren Szenen, Lesen von Texten in mehreren Sprachen, Dokumentanalyse und Extraktion wichtiger Informationen und enthält 39 Teilmengen und 7.058 vollständig annotierte Bilder. Die Einführung von CC-OCR schließt die Lücke bei der Bewertung aktueller multimodaler Modelle in komplexen Strukturen und feinkörnigen visuellen Herausforderungen und ist von großer Bedeutung für die Förderung des Fortschritts multimodaler Modelle in praktischen Anwendungen.
Zitat
@misc{yang2024ccocr,
title={CC-OCR: A Comprehensive and Challenging OCR Benchmark for Evaluating Large Multimodal Models in Literacy},
author={Zhibo Yang and Jun Tang and Zhaohai Li and Pengfei Wang and Jianqiang Wan and Humen Zhong and Xuejing Liu and Mingkun Yang and Peng Wang and Shuai Bai and LianWen Jin and Junyang Lin},
year={2024},
eprint={2412.02210},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2412.02210},
}
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.