Command Palette
Search for a command to run...
MedQA-Datensatz Zur Beantwortung Medizinischer Textfragen
Datum
Größe
Organisation
Veröffentlichungs-URL
Paper-URL
Tags
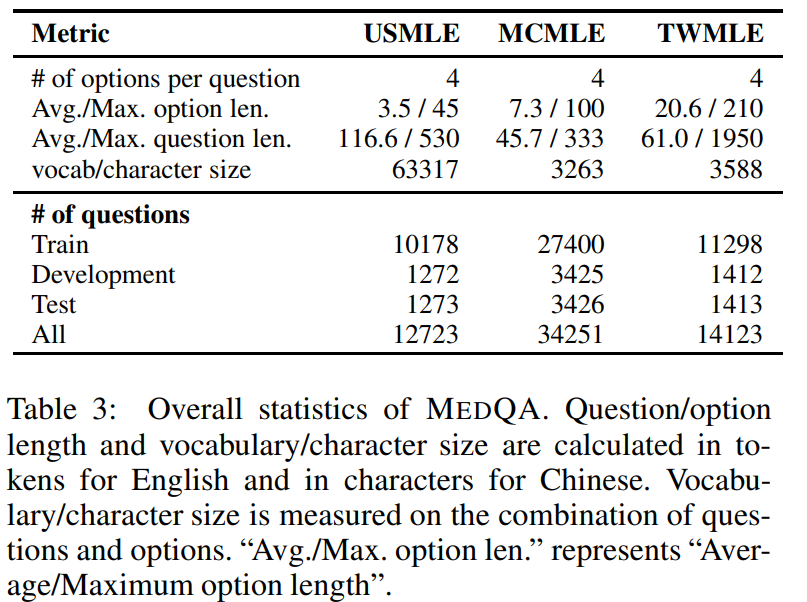
Der MedQA-Datensatz ist ein Frage-Antwort-Datensatz für den medizinischen Bereich, der den Stil der United States Medical Licensing Examination (USMLE) simuliert. Es wurde 2020 von einem Forschungsteam des MIT und der Huazhong University of Science and Technology veröffentlicht. Die zugehörigen Ergebnisse der Studie lauten:Welche Krankheit hat dieser Patient? Ein umfangreicher Open-Domain-Fragen-Antwort-Datensatz aus medizinischen Prüfungen". Der Datensatz wurde aus professionellen medizinischen Untersuchungen gesammelt und umfasst Englisch, vereinfachtes Chinesisch und traditionelles Chinesisch. Er enthält 12.723, 34.251 bzw. 14.123 Fragen und zielt darauf ab, die Fähigkeit des Modells zu bewerten, medizinisches Wissen zu verstehen und anzuwenden. . Die Erstellung des MedQA-Datensatzes basiert auf professionellen ärztlichen Zulassungsprüfungen, wodurch die hohe Qualität und Professionalität der Fragen sichergestellt wird. Ergänzend zu den Fragedaten wurde ein umfangreiches Korpus an medizinischen Lehrbüchern erhoben und veröffentlicht, aus dem sich das Leseverständnismodell das notwendige Wissen zur Beantwortung der Fragen aneignen kann. Der Datensatz ist in Trainingssatz, Entwicklungssatz und Testsatz unterteilt, die jeweils zum Trainieren, Verifizieren und Testen des Modells verwendet werden.
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.