HyperAI
Command Palette
Search for a command to run...
LoveDA: Ein Fernerkundungs-Landbedeckungsdatensatz Für Domänenadaptive Semantische Segmentierung
Datum
vor 2 Jahren
Größe
8.92 GB
Organisation
Veröffentlichungs-URL
Paper-URL
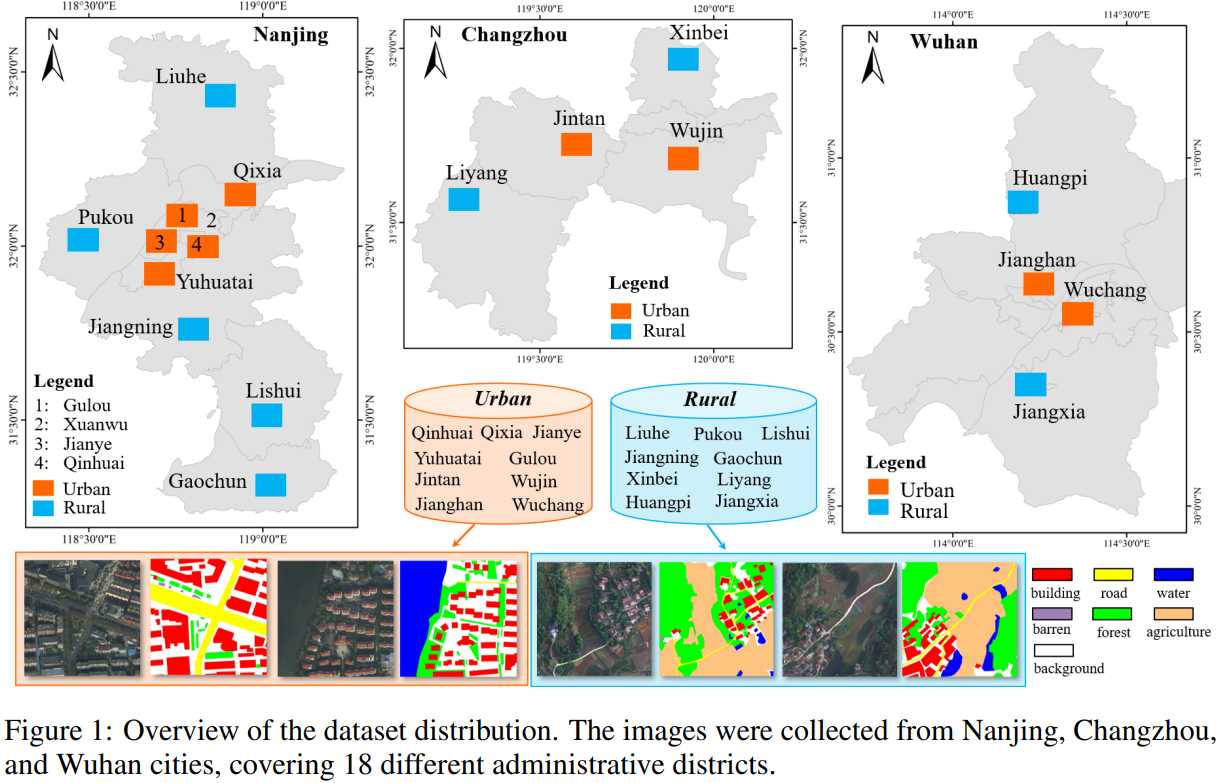
Der LoveDA-Datensatz ist ein Landbedeckungsdatensatz für die Fernerkundung, der speziell für die domänenadaptive semantische Segmentierung entwickelt wurde. Es wurde vom RSIDEA-Team des State Key Laboratory of Surveying, Mapping and Remote Sensing Information Engineering an der Wuhan University entwickelt und zielt darauf ab, die Forschung zur semantischen Segmentierung und zum Transferlernen im Bereich der Fernerkundung zu fördern. Hier sind einige Hauptmerkmale des LoveDA-Datensatzes:
- Mehrskalige Objekte: Die Bilder mit hoher räumlicher Auflösung (HSR) im Datensatz wurden aus 18 komplexen städtischen und ländlichen Szenen in drei verschiedenen Städten in China gesammelt. Objekte derselben Kategorie in diesen Szenen weisen in unterschiedlichen geografischen Landschaften völlig unterschiedliche Maßstabsänderungen auf.
- Komplexe Hintergrundproben: Der LoveDA-Datensatz enthält umfangreiche Details und größere Variationen innerhalb der Klasse, insbesondere Hintergrundproben, was die Komplexität der Klassifizierungsaufgabe erhöht.
- Inkonsistente Kategorieverteilung: Es gibt Unterschiede in der Kategorieverteilung zwischen städtischen und ländlichen Szenen. Städtische Szenen enthalten mehr von Menschenhand geschaffene Objekte wie Gebäude und Straßen, während ländliche Szenen mehr natürliche Elemente wie Gewässer und Wälder enthalten.
- Anwendbarkeit:Dieser Datensatz eignet sich sowohl für die semantische Segmentierungsaufgabe der Landbedeckung als auch für die Aufgabe der unüberwachten Domänenanpassung (UDA) und bietet Forschern neue Herausforderungen und Forschungsrichtungen.
- Großflächige Annotation: Der LoveDA-Datensatz enthält 5.987 hochauflösende Bilder und 166.768 annotierte semantische Objekte und ist damit einer der größten Datensätze seiner Art.
- Datenquelle: Die Bilder im Datensatz stammen von der Google Earth-Plattform und wurden in Nanjing, Changzhou und Wuhan gesammelt. Sie decken eine Gesamtfläche von 536,15 Quadratkilometern ab.
- Open Source: Der LoveDA-Datensatz ist kostenlos und Open Source. Der relevante Code und die Daten sind auf GitHub zu finden, was die Forschung und Zusammenarbeit innerhalb der Community fördert.
- Soziale Auswirkungen: Dieser Datensatz wurde entwickelt, um die Technologie zur Landbedeckungskartierung im Bereich der Fernerkundung voranzutreiben und könnte positive Auswirkungen auf die Gesellschaft haben, beispielsweise durch die Reduzierung des für die Feldkartierung erforderlichen Personal- und Materialaufwands. Die Veröffentlichung des LoveDA-Datensatzes bietet Forschern im Bereich der Fernerkundung eine anspruchsvolle Datenressource, um praktische Probleme zu lösen und die Entwicklung verwandter Technologien zu fördern.
LoveDA.torrent
Seeding 1Wird heruntergeladen 0Abgeschlossen 329Gesamtdownloads 690
Dieser Datensatz wurde von Community-Nutzern beigesteuert und dient ausschließlich Bildungs- und Informationszwecken. Falls Inhalte eine Urheberrechtsverletzung darstellen, kontaktieren Sie uns bitte unter [email protected] zur umgehenden Prüfung und Entfernung.
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.
KI-gestütztes kollaboratives Programmieren
Sofort einsatzbereite GPUs
Die besten Preise
HyperAI Newsletters
Abonnieren Sie unsere neuesten Updates
Wir werden die neuesten Updates der Woche in Ihren Posteingang liefern um neun Uhr jeden Montagmorgen
Unterstützt von MailChimp