HyperAI
Command Palette
Search for a command to run...
MiMo-Audio-7B-Instruct:小米开源的端到端语音模型
一、教程简介

MiMo-Audio 是小米公司于 2025 年 9 月发布的端到端语音模型。其预训练数据已扩展至超过一亿小时,研究人员观察到它在多种音频任务上展现出了少样本学习能力。团队对这些能力进行了系统评估,发现 MiMo-Audio-7B-Base 在开源模型的语音智能与音频理解基准测试中均达到了当前最优水平(SOTA)。除标准指标外,该模型还能泛化到训练数据中未涵盖的任务,如语音转换、风格迁移和语音编辑。此外,MiMo-Audio-7B-Base 具备强大的语音续写能力,可生成高度逼真的脱口秀、朗诵、直播和辩论内容。在后训练阶段,研究者整理了一套多样化的指令微调语料,并在音频理解与生成中引入了思维机制。由此得到的 MiMo-Audio-7B-Instruct 在音频理解基准、口语对话基准和指令式语音合成(instruct-TTS)评测中均达到开源领域最先进水平,并在部分场景下接近或超越闭源模型。相关论文成果为 MiMo-Audio-Technical-Report 。
该教程算力资源采用单卡 RTX 5090 。
二、效果示例
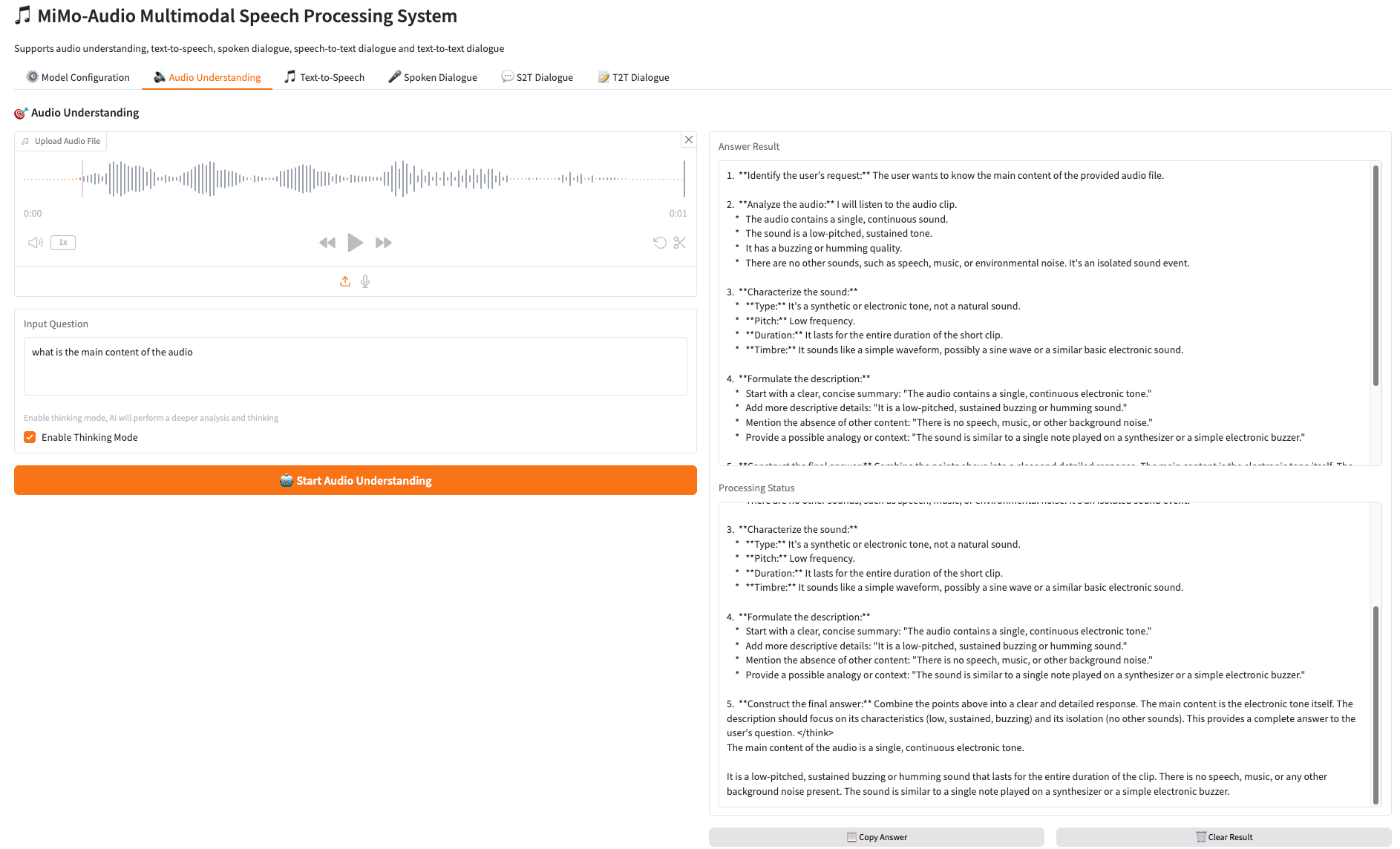
1. 🔊 音频理解 Audio Understanding
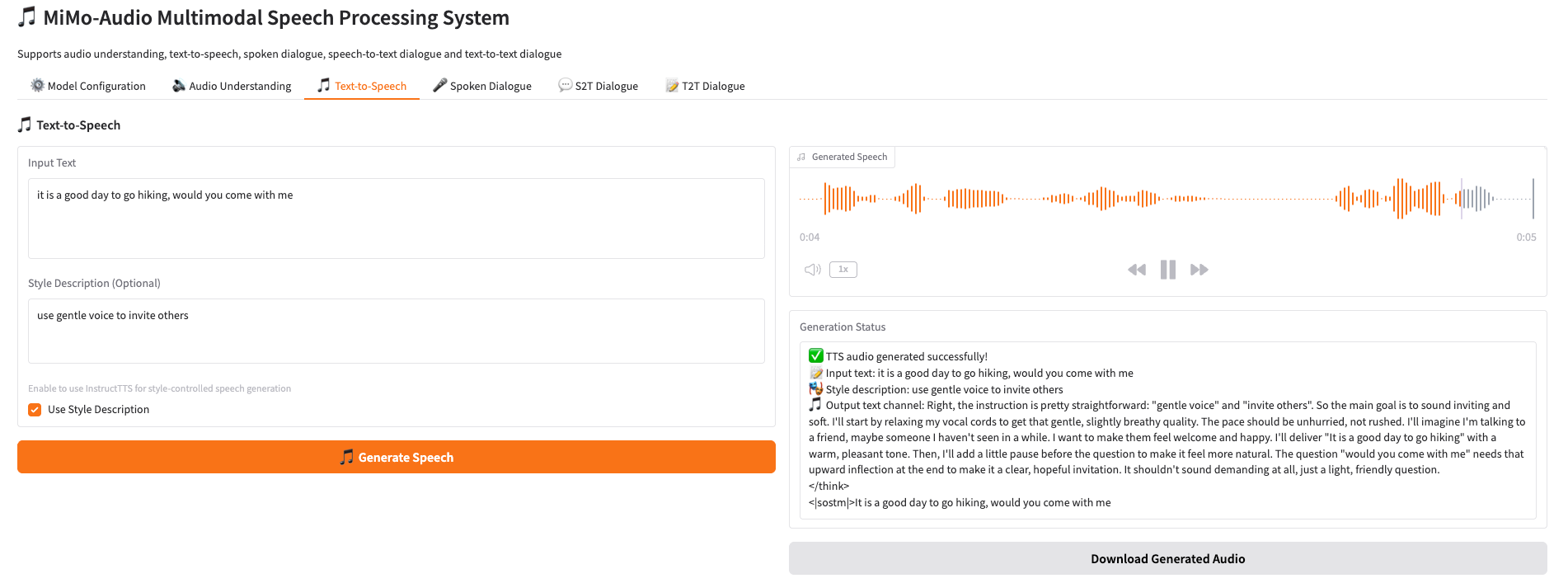
2. 🎵 音频生成 Text-to-Speech
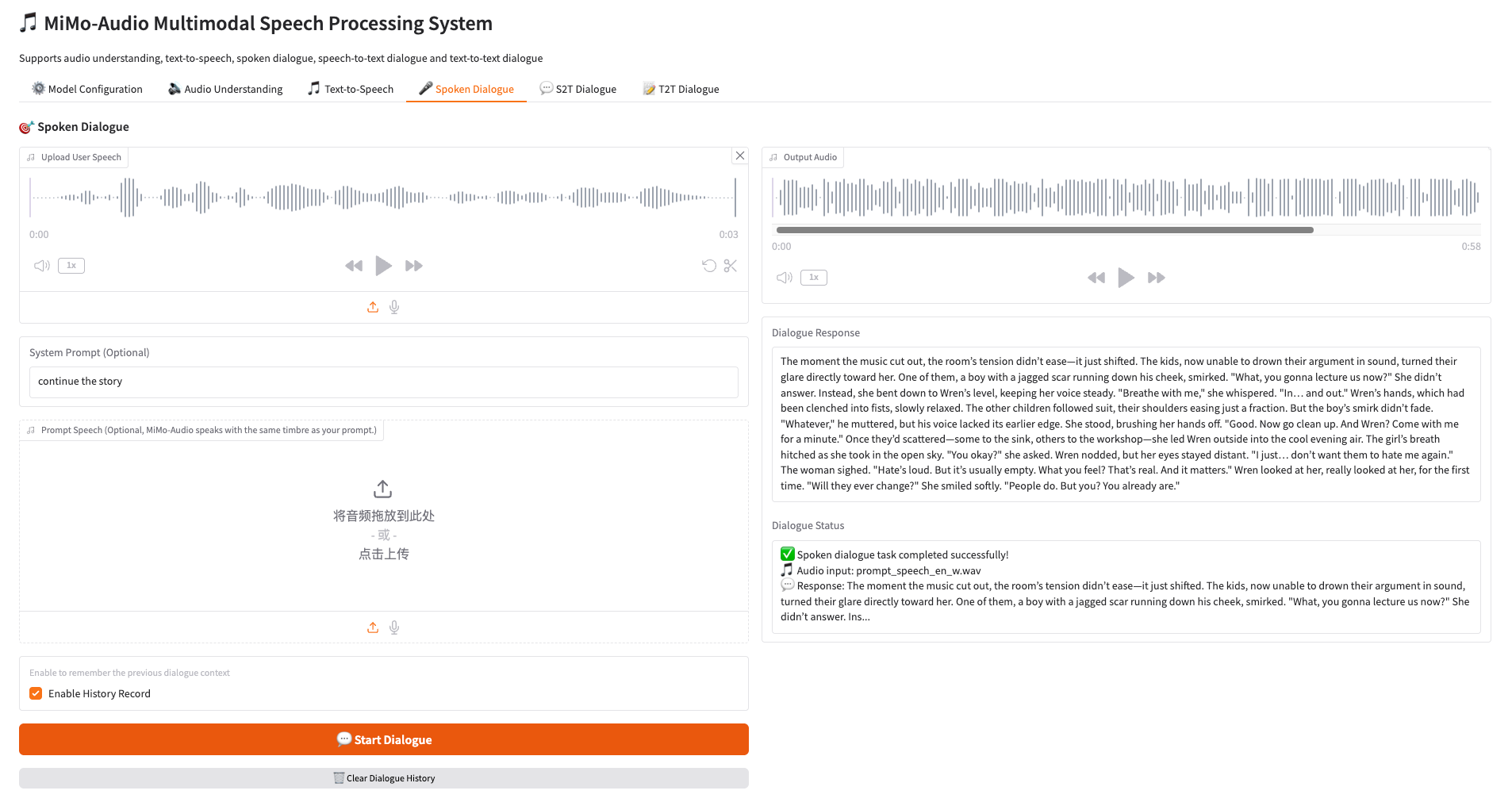
3. 🎤 语音对话 Spoken Dialogue
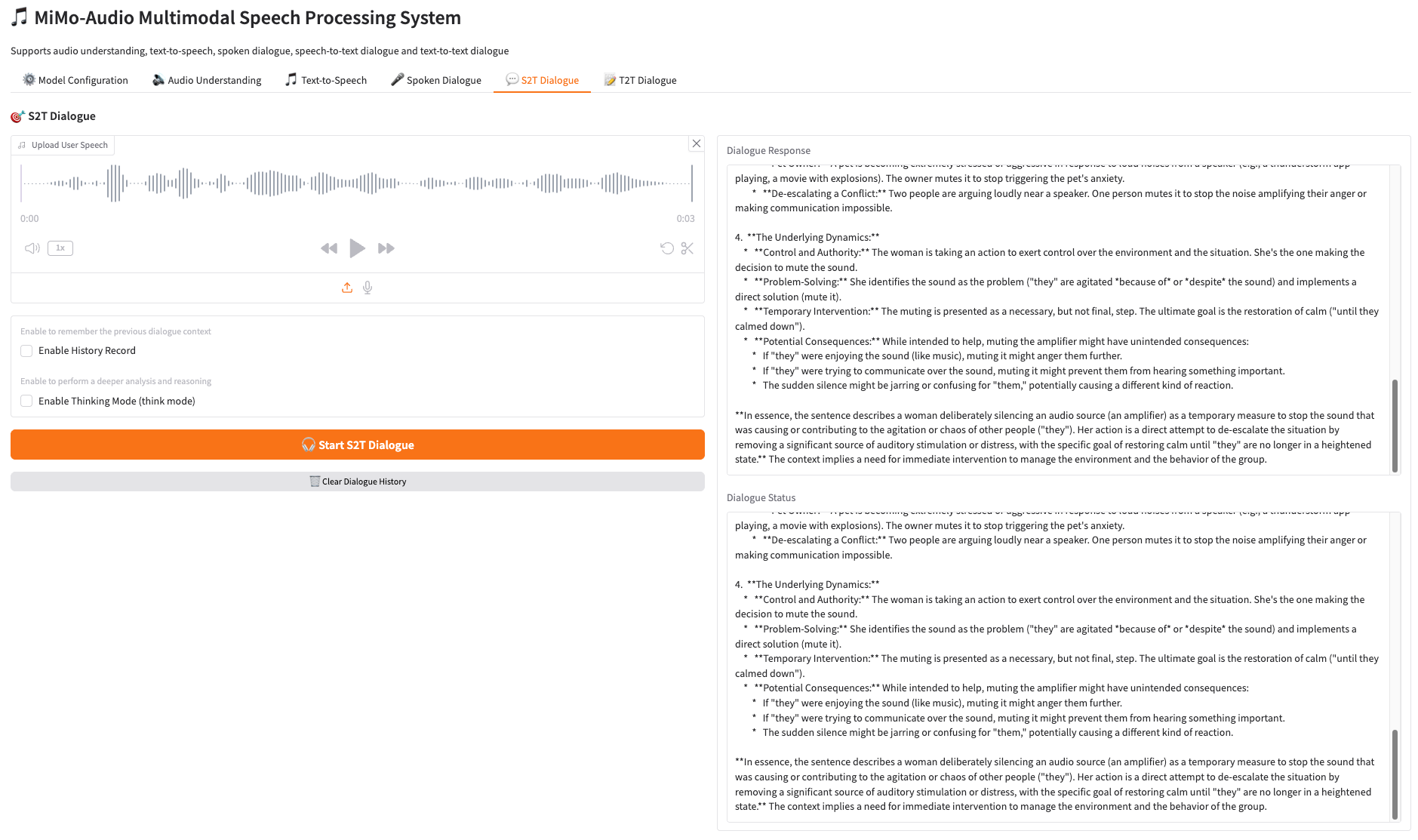
4. 💬 语音-文字对话 S2T Dialogue
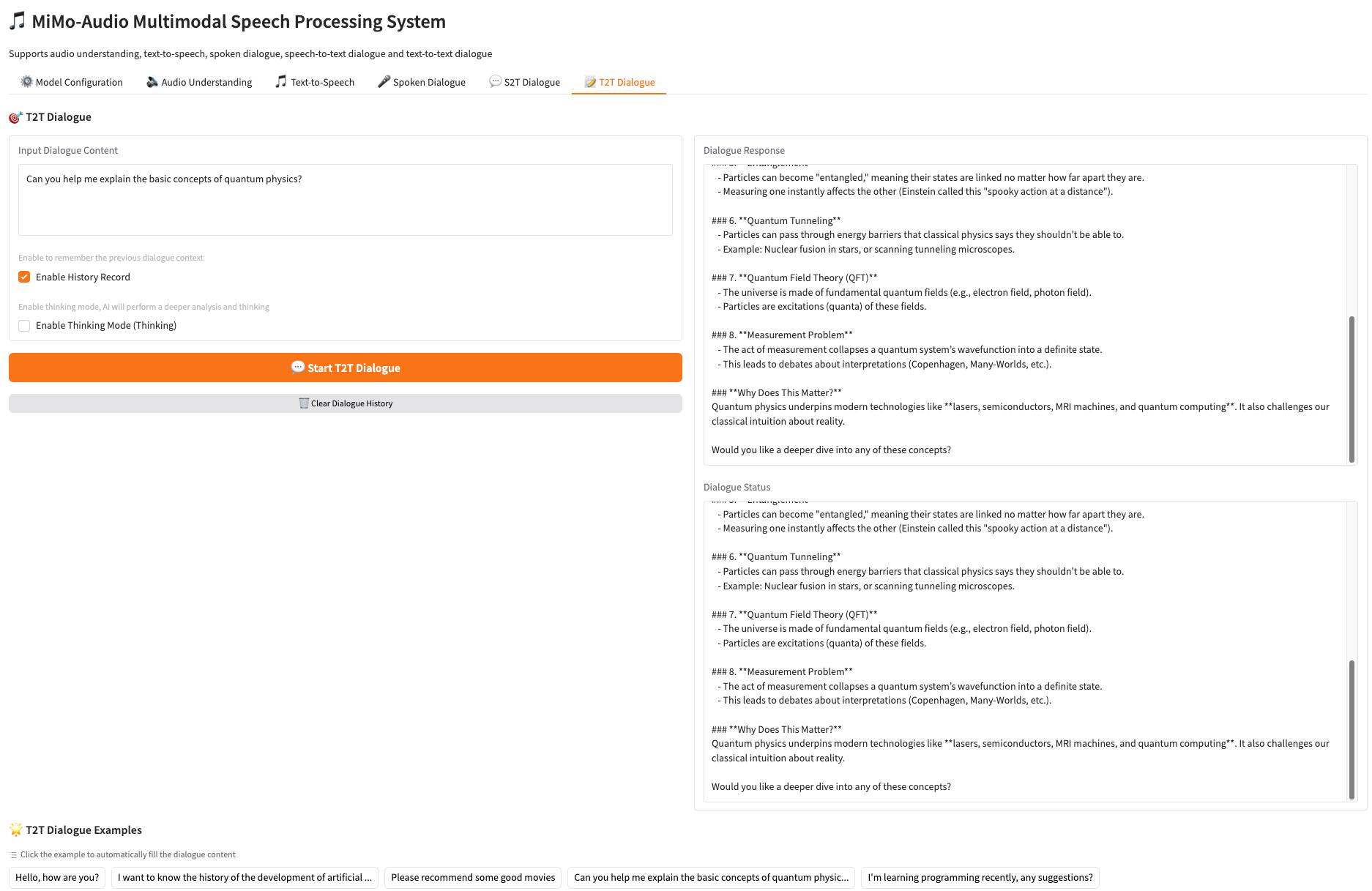
5. 📝 文字-文字对话 T2T Dialogue
三、运行步骤
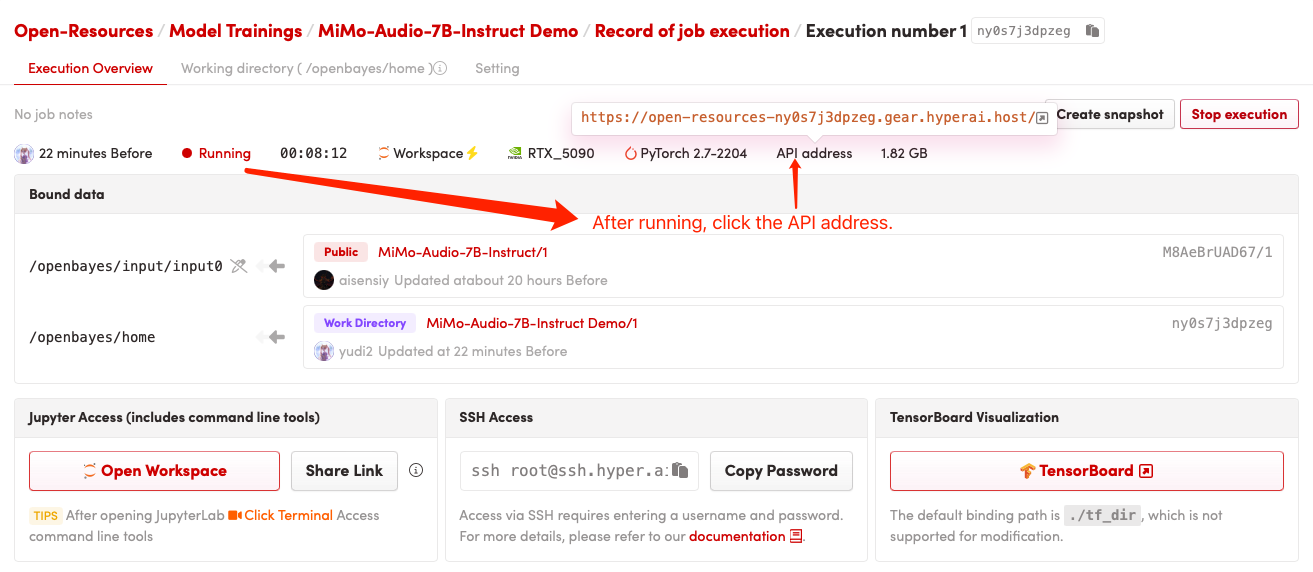
1. 启动容器
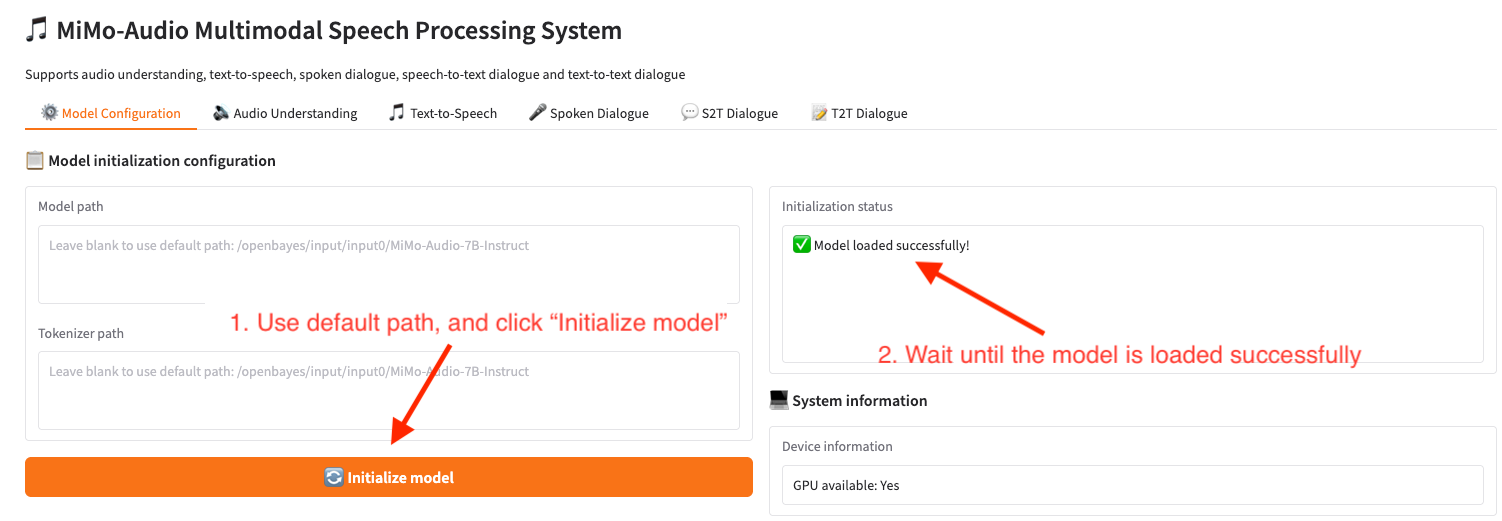
2. 初始化权重参数
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 2-3 分钟后刷新页面。
使用 Safari 浏览器时,音频可能无法直接播放,需要下载后进行播放。
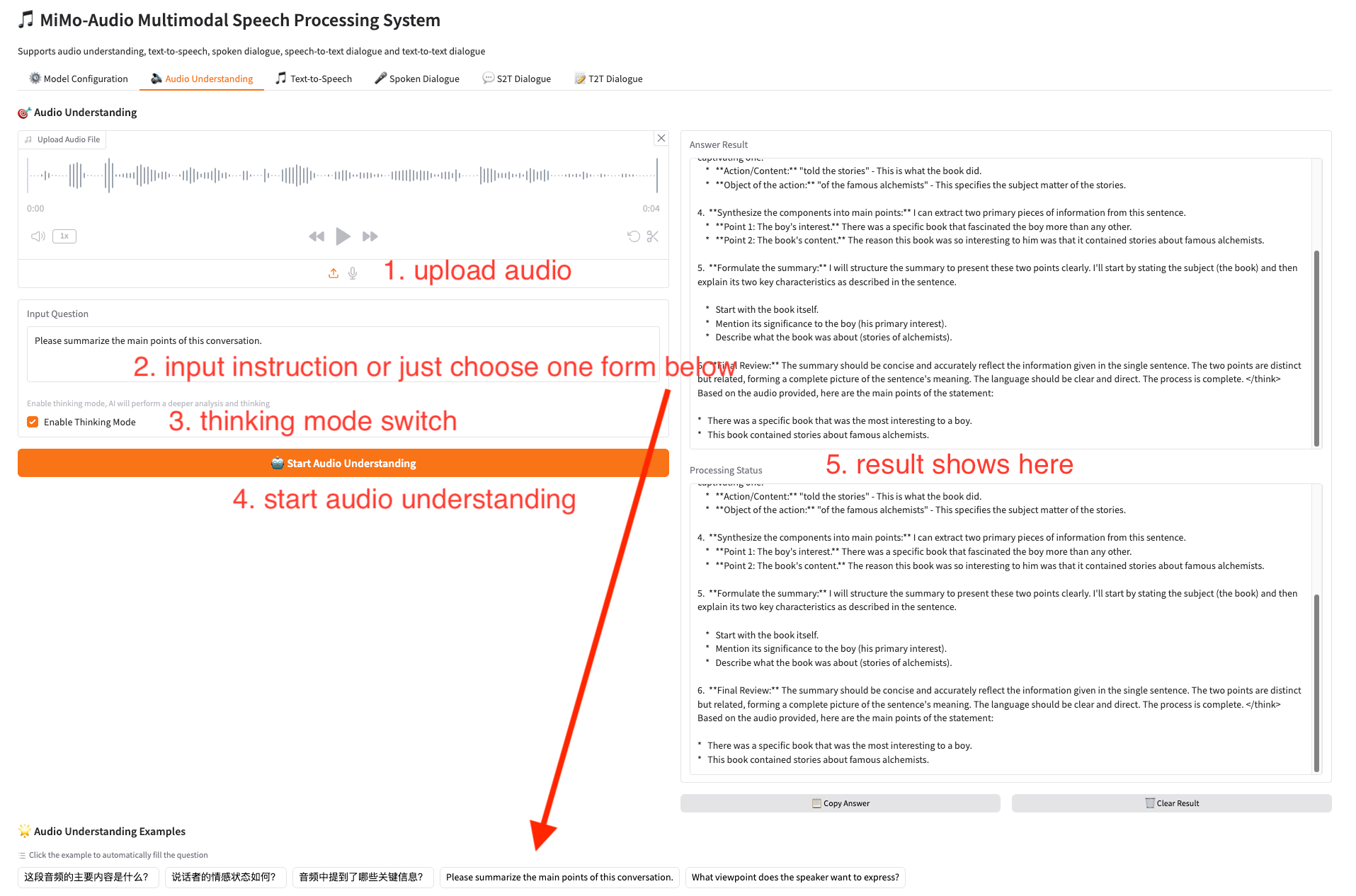
3. 音频理解
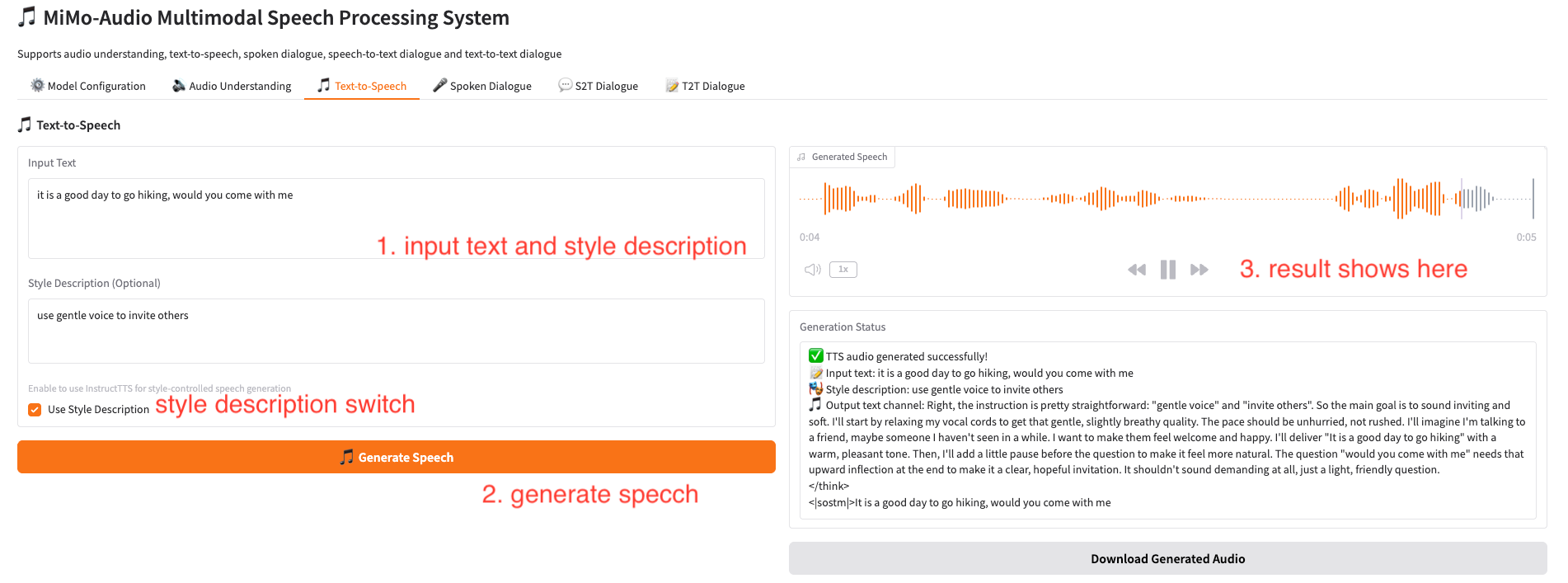
4. 音频生成
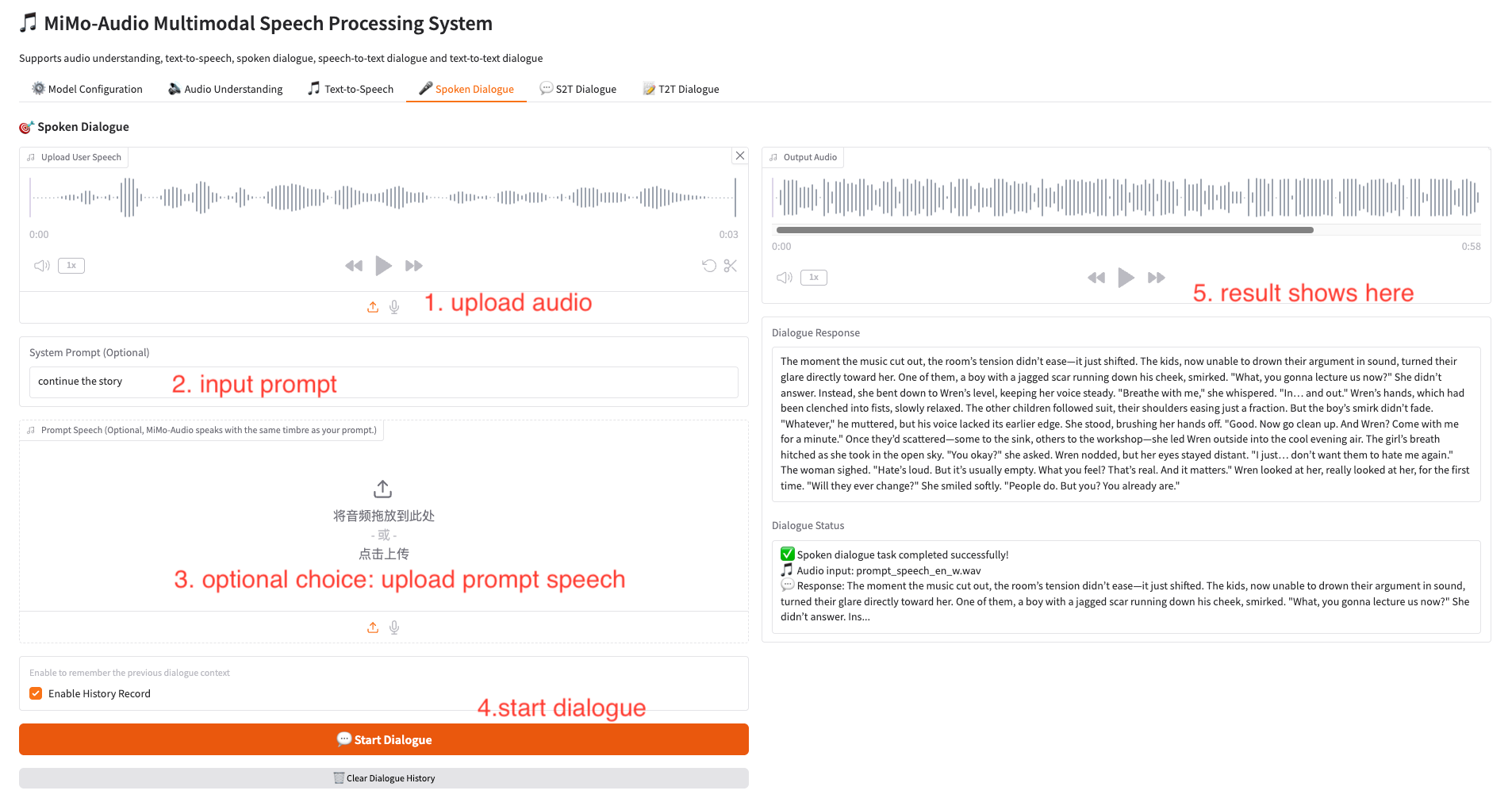
5. 语音对话
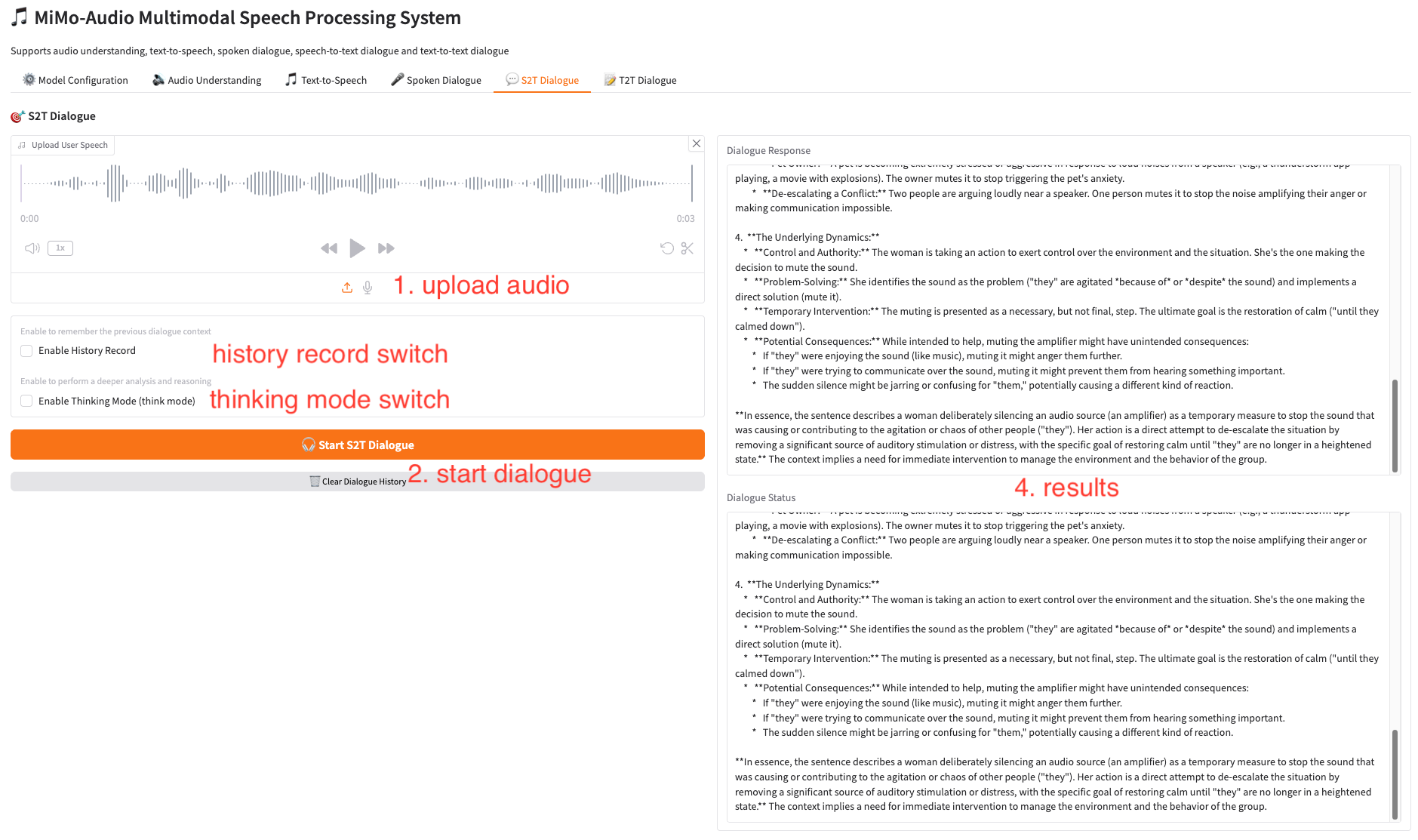
6. 语音-文字对话
7. 文字-文字对话

引用信息
@misc{coreteam2025mimoaudio,
title={MiMo-Audio: Audio Language Models are Few-Shot Learners},
author={LLM-Core-Team Xiaomi},
year={2025},
url={https://github.com/XiaomiMiMo/MiMo-Audio},
}该教程由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 [email protected] 以便及时审查和下架。