HyperAI
Command Palette
Search for a command to run...
POINTS-Reader:无蒸馏端到端的轻量级文档视觉语言模型
一、教程简介

POINTS-Reader 是由腾讯、上海交通大学与清华大学于 2025 年 8 月联合推出的一款专为文档图像转文本设计的轻量级视觉-语言模型(VLM)。 POINTS-Reader 不追求参数规模,也不依赖教师模型「蒸馏」,而是通过一套两阶段自进化框架,在保持结构极简的同时,实现对中英文复杂文档(含表格、公式、多栏排版)的高精度端到端识别。相关论文成果为 POINTS-Reader: Distillation-Free Adaptation of Vision-Language Models for Document Conversion 。 已被 EMNLP 2025 接受,将在主会议中进行展示。
该教程算力资源采用单卡 RTX 4090 。
二、效果展示
Single Column with Latex Formula

Single Column with Table
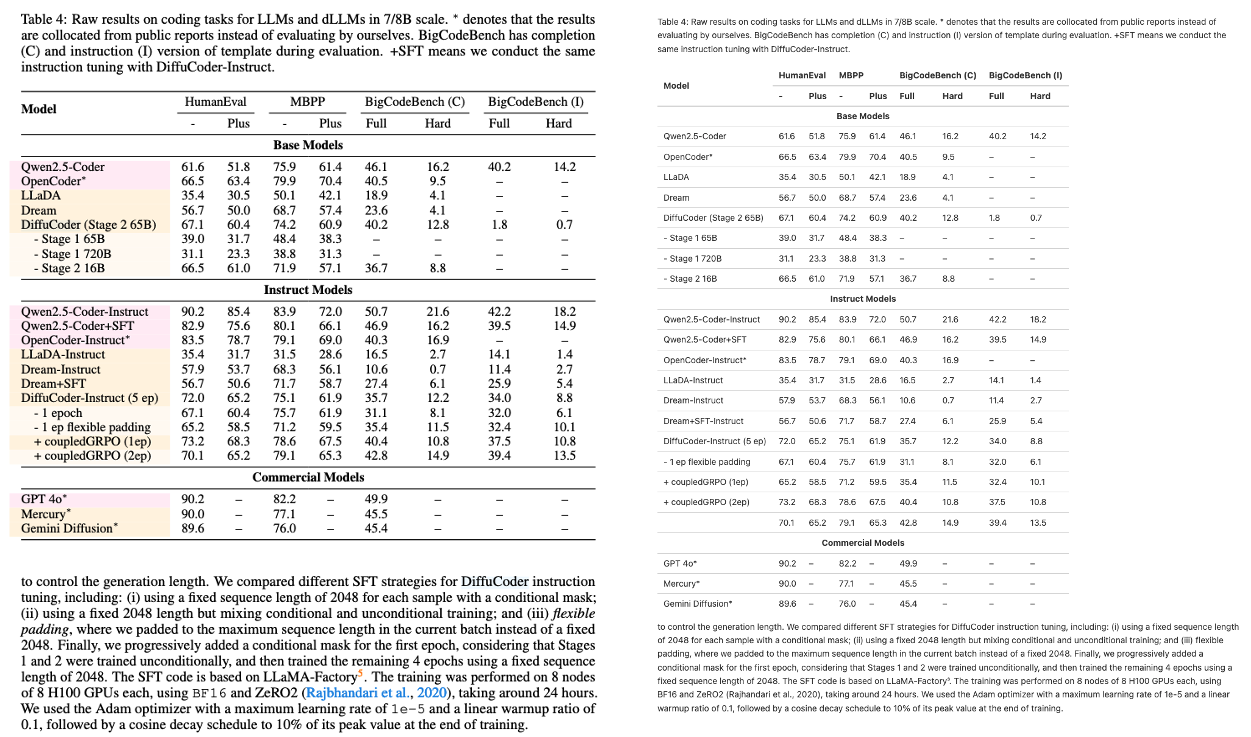
Multi-column with Latex Formula

Multi-column with Table
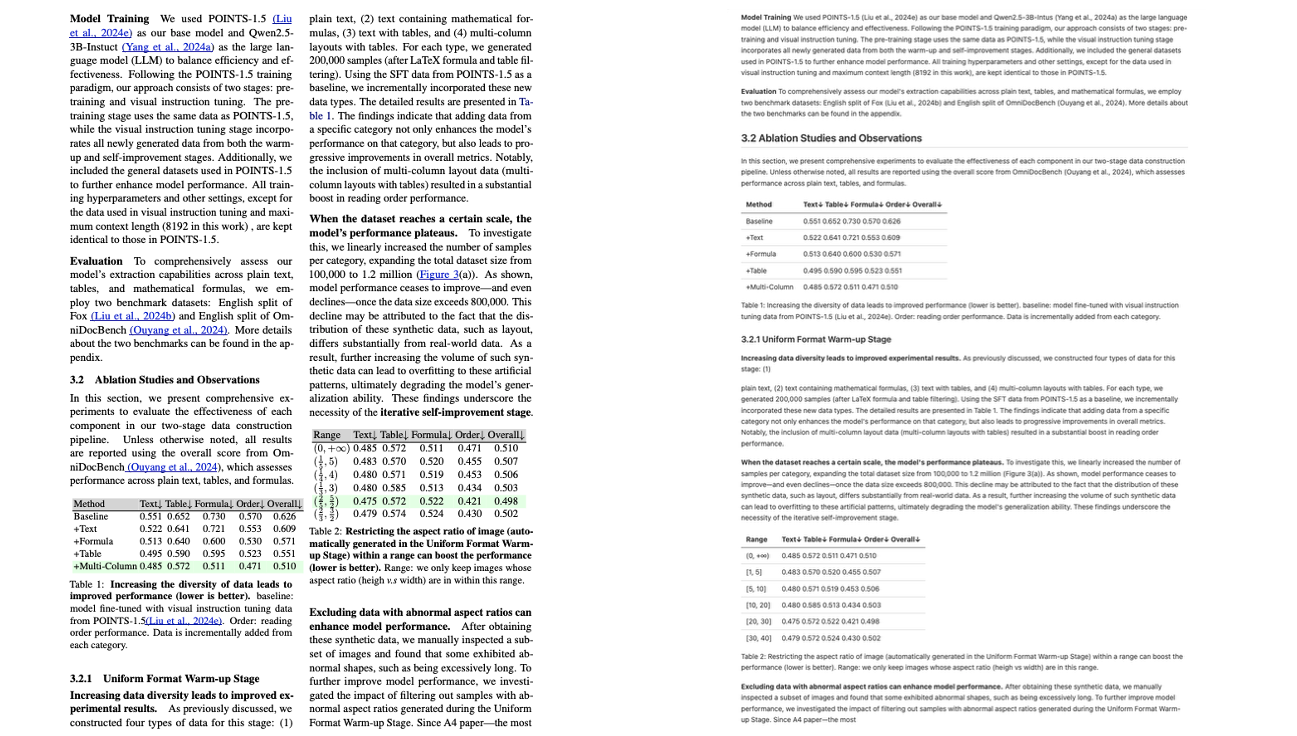
三、运行步骤
1. 启动容器
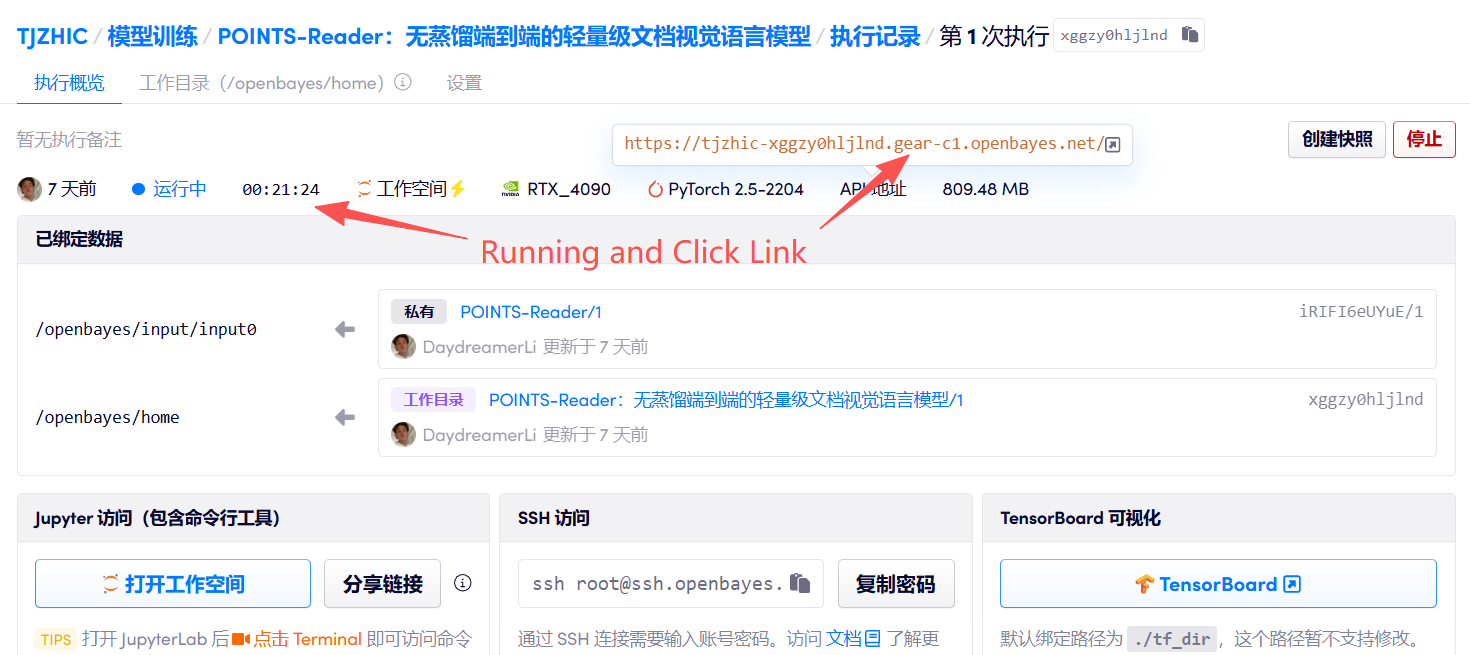
2. 使用步骤
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 2-3 分钟后刷新页面。
1. Extracted Content
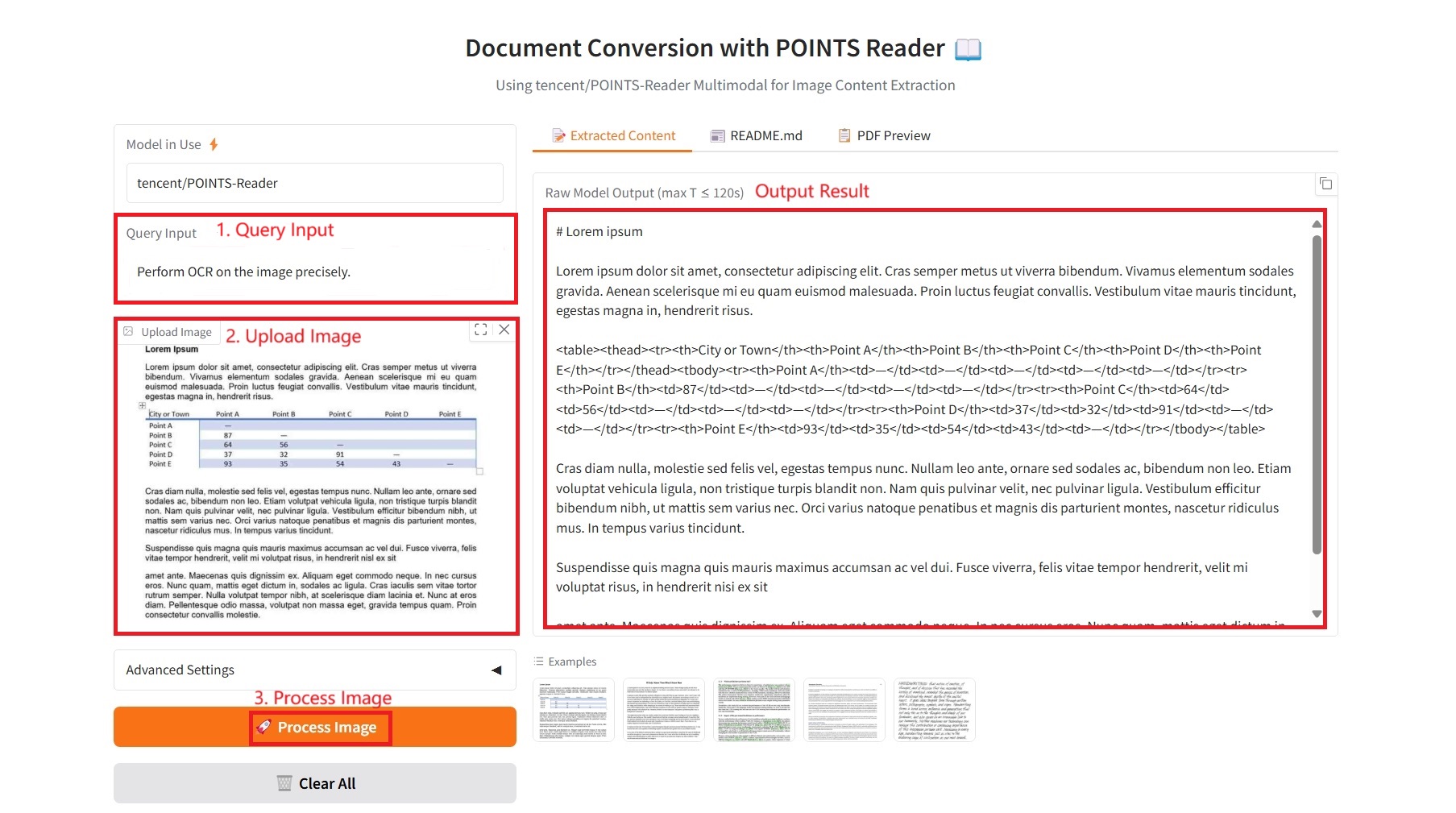
具体参数:
- Query Input:输入文本文字要求。
- Image Upscale Factor:在处理前增加图像大小。可以改进小文本的 OCR 。默认值:1.0(无变化)。
- Max New Tokens:生成文本的最大长度限制,控制输出内容的字数上限。
- Top-p(nucleus sampling):核采样参数,选择累积概率达到 p 的最小词集合进行采样,控制输出多样性。
- Top-k:从概率最高的 k 个候选词中进行采样,数值越大输出越随机,越小越确定。
- Temperature:控制生成文本的随机性,数值越高输出越随机多样,越低越确定和保守。
- Repetition penalty:重复惩罚参数,数值大于 1.0 时会减少重复内容的生成,数值越大惩罚越强。
- PDF Export Settings:
- Font Size:PDF 中文字的字体大小,控制导出文档的可读性。
- Line Spacing:PDF 中段落的行间距,影响文档的美观度和可读性。
- Text Alignment:PDF 中文本的对齐方式,包括左对齐、居中、右对齐或两端对齐。
- Image Size in PDF:PDF 中嵌入图像的尺寸大小,包括小、中、大三个选项。
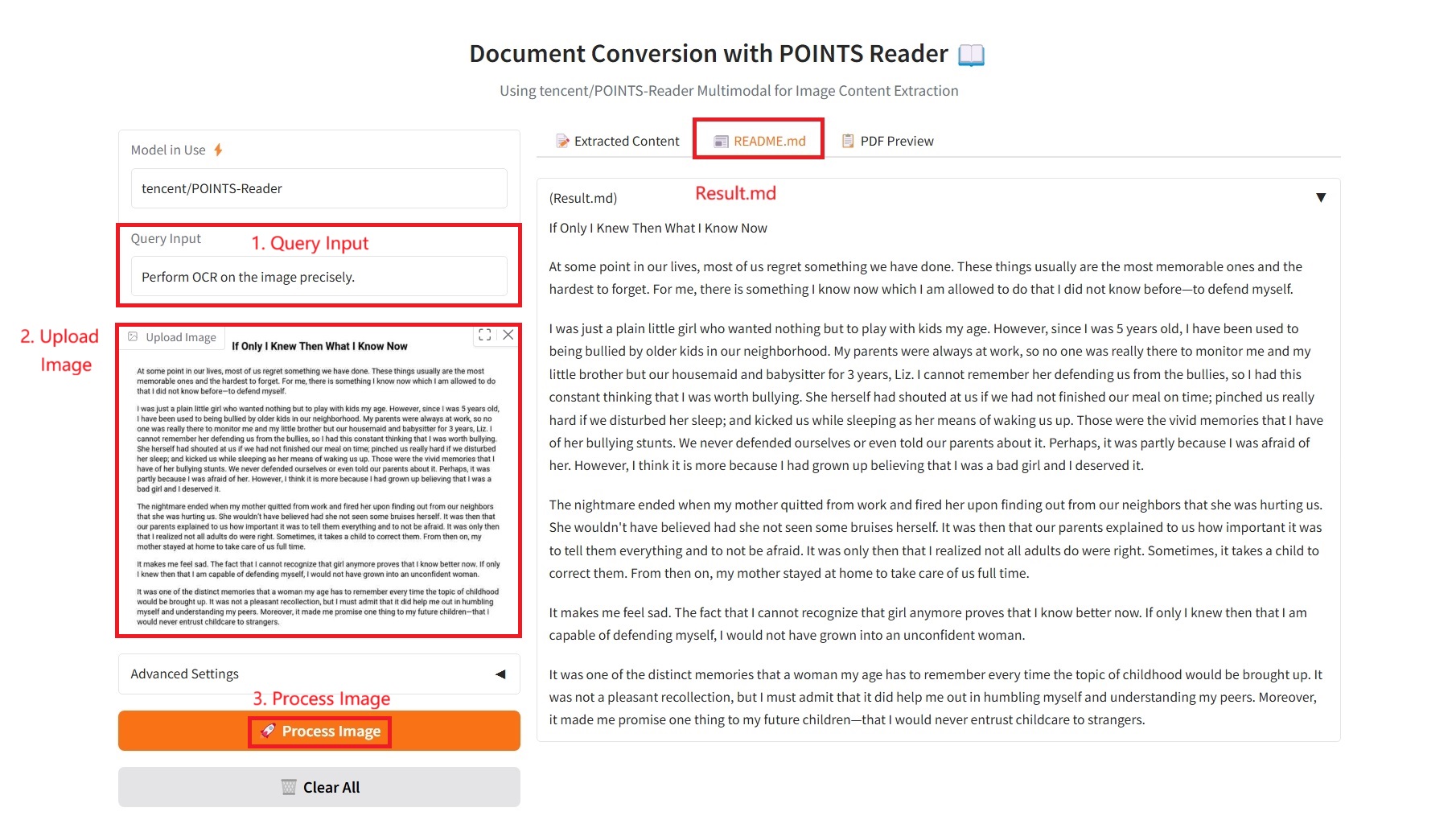
2. README.md
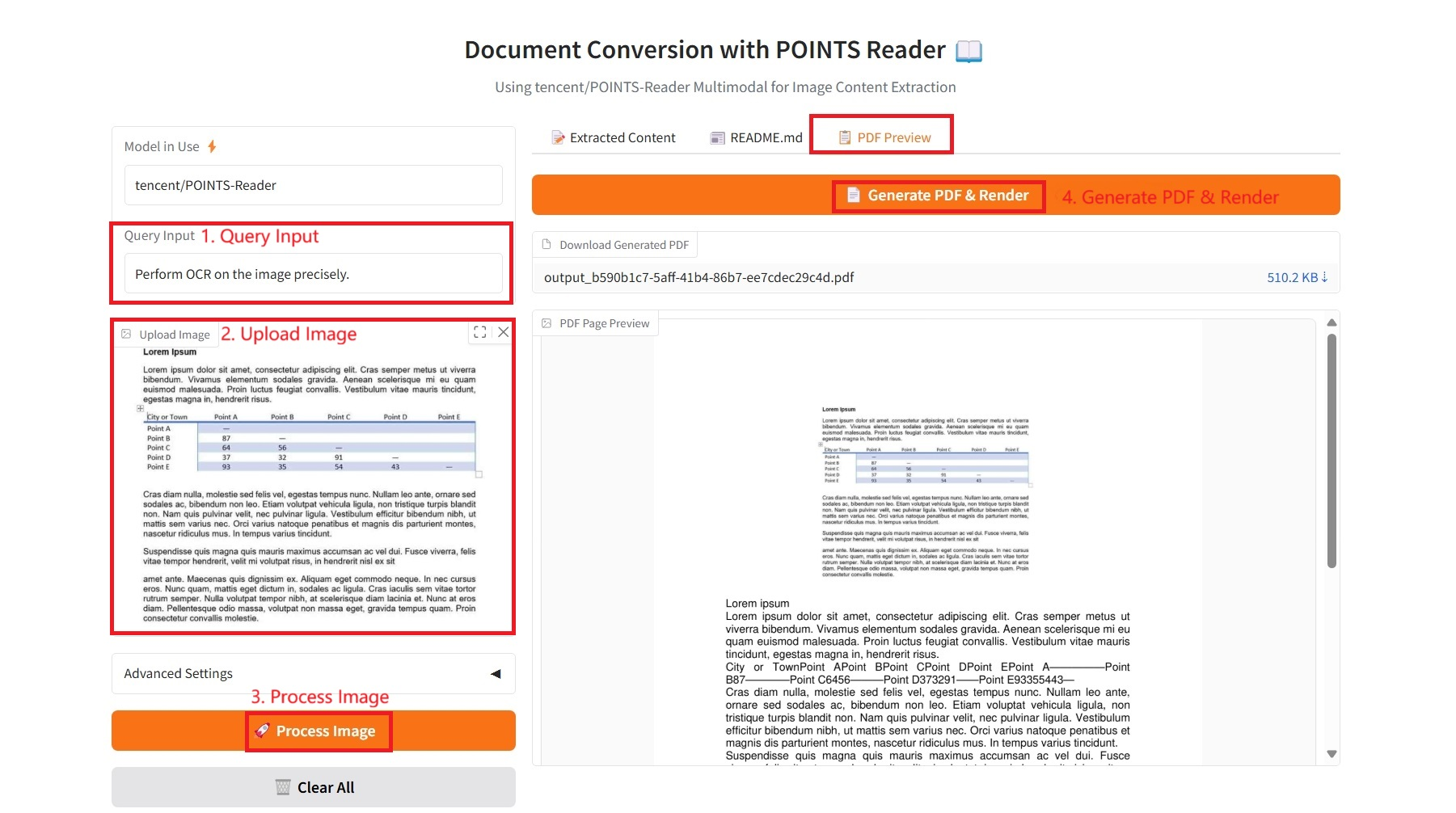
3. PDF Preview
四、交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

引用信息
本项目引用信息如下:
@article{points-reader, title={POINTS-Reader: Distillation-Free Adaptation of Vision-Language Models for Document Conversion}, author={Liu, Yuan and Zhongyin Zhao and Tian, Le and Haicheng Wang and Xubing Ye and Yangxiu You and Zilin Yu and Chuhan Wu and Zhou, Xiao and Yu, Yang and Zhou, Jie}, journal={EMNLP2025}, year={2025} } @article{liu2024points1,
title={POINTS1. 5: Building a Vision-Language Model towards Real World Applications},
author={Liu, Yuan and Tian, Le and Zhou, Xiao and Gao, Xinyu and Yu, Kavio and Yu, Yang and Zhou, Jie},
journal={arXiv preprint arXiv:2412.08443},
year={2024}
} @article{liu2024points,
title={POINTS: Improving Your Vision-language Model with Affordable Strategies},
author={Liu, Yuan and Zhao, Zhongyin and Zhuang, Ziyuan and Tian, Le and Zhou, Xiao and Zhou, Jie},
journal={arXiv preprint arXiv:2409.04828},
year={2024}
}@article{liu2024rethinking,
title={Rethinking Overlooked Aspects in Vision-Language Models},
author={Liu, Yuan and Tian, Le and Zhou, Xiao and Zhou, Jie},
journal={arXiv preprint arXiv:2405.11850},
year={2024}
}
该教程由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 [email protected] 以便及时审查和下架。