HyperAI
Command Palette
Search for a command to run...
Flow-GRPO 流匹配文生图模型 Demo
一、教程简介

Flow-GRPO 是由香港中文大学多媒体实验室、清华大学以及快手可灵团队于 2025 年 5 月 13 日推出的流匹配模型。该模型开创性融合在线强化学习框架与流匹配理论,在 GenEval 2025 基准测试中取得突破性进展:SD 3.5 Medium 模型组合式生成准确率由基准值 63% 跃升至 95%,生成质量评估指标首次超越 GPT-4o 。相关论文成果为 Flow-GRPO: Training Flow Matching Models via Online RL 。
本教程采用资源为单卡 RTX 4090,图像生成提示词仅支持英文。
二、项目示例
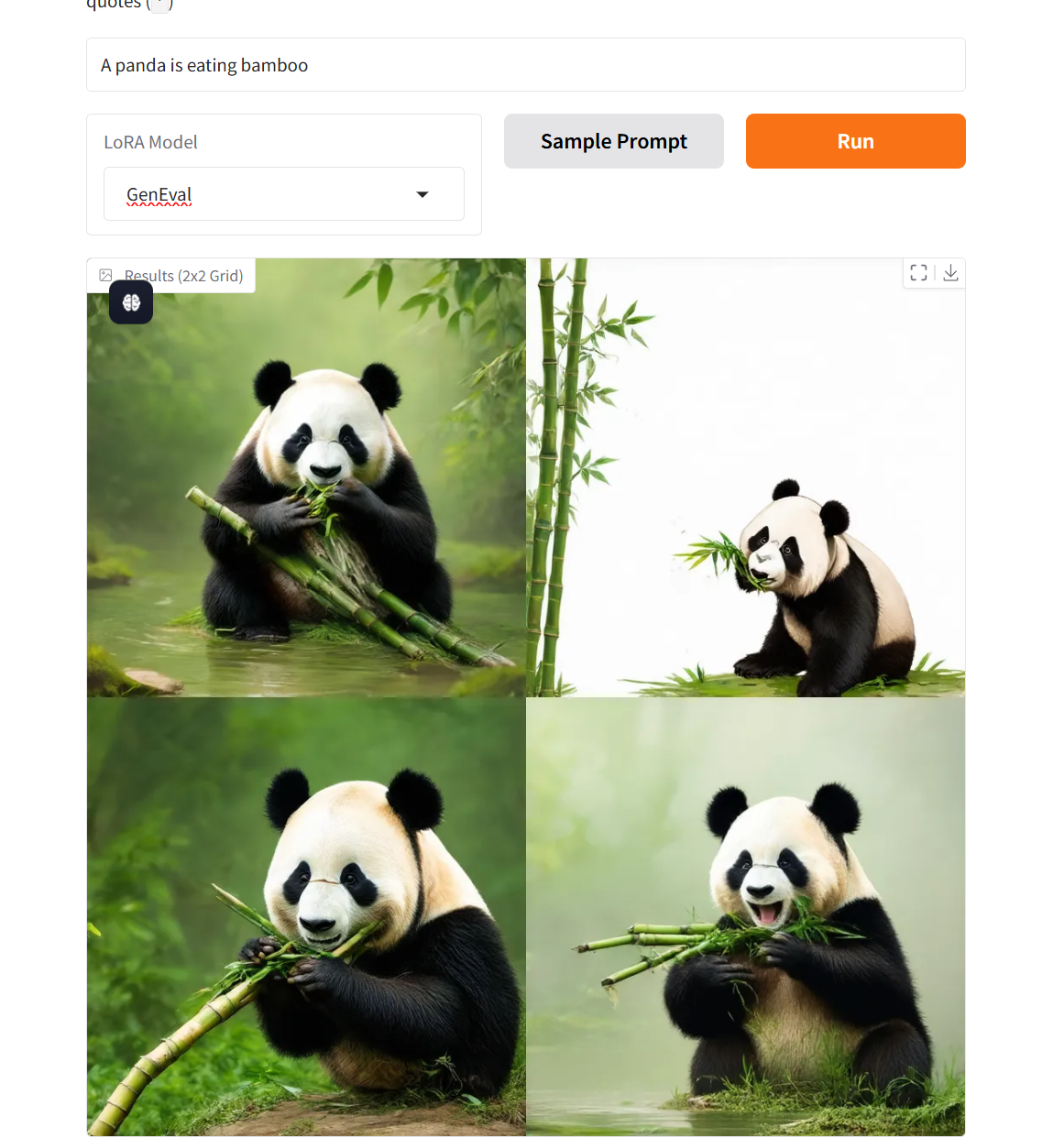
三、运行步骤
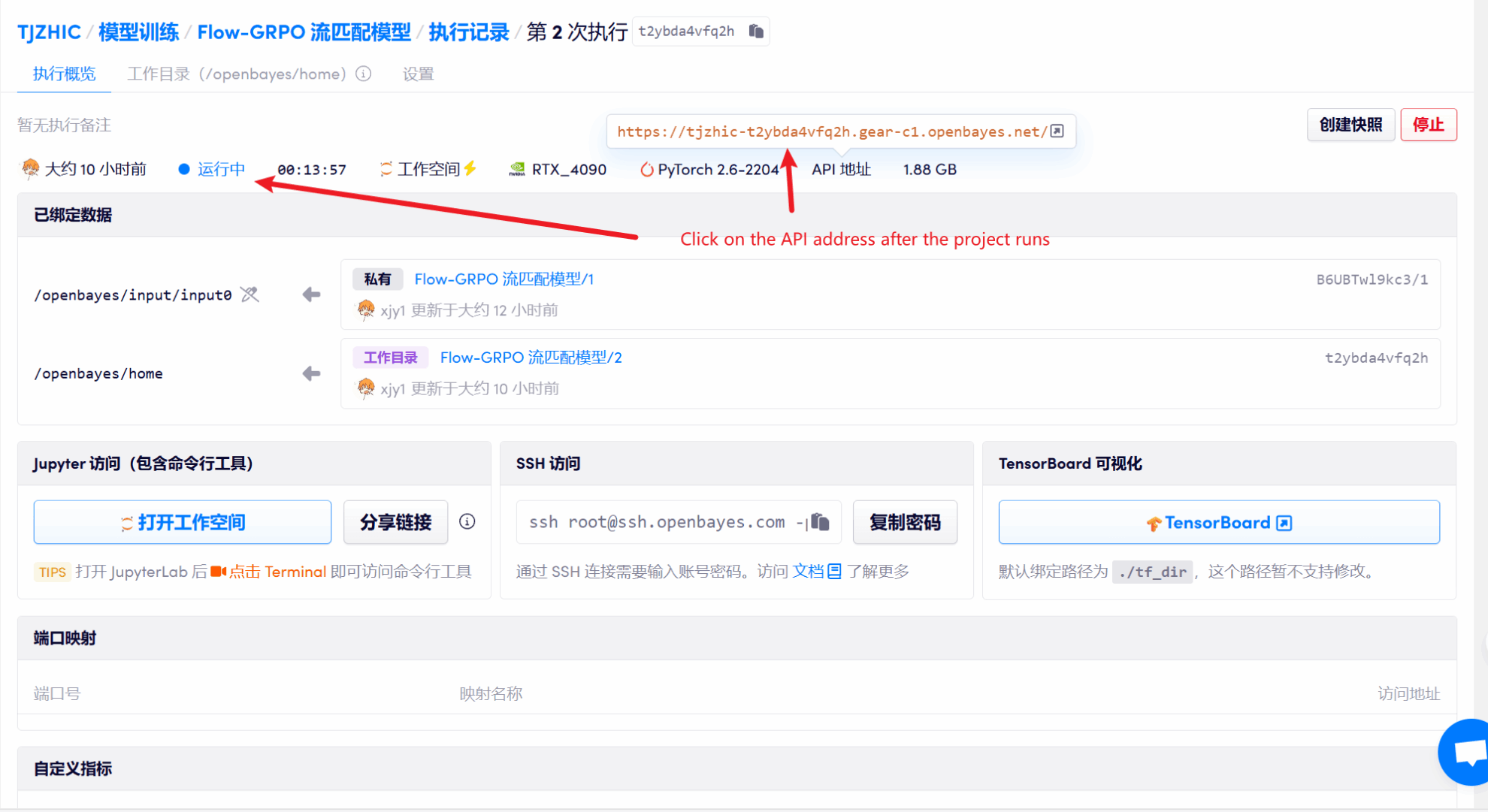
1. 启动容器后点击 API 地址即可进入 Web 界面
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 1-2 分钟后刷新页面。
2. 进入网页后,即可与模型展开对话
使用步骤
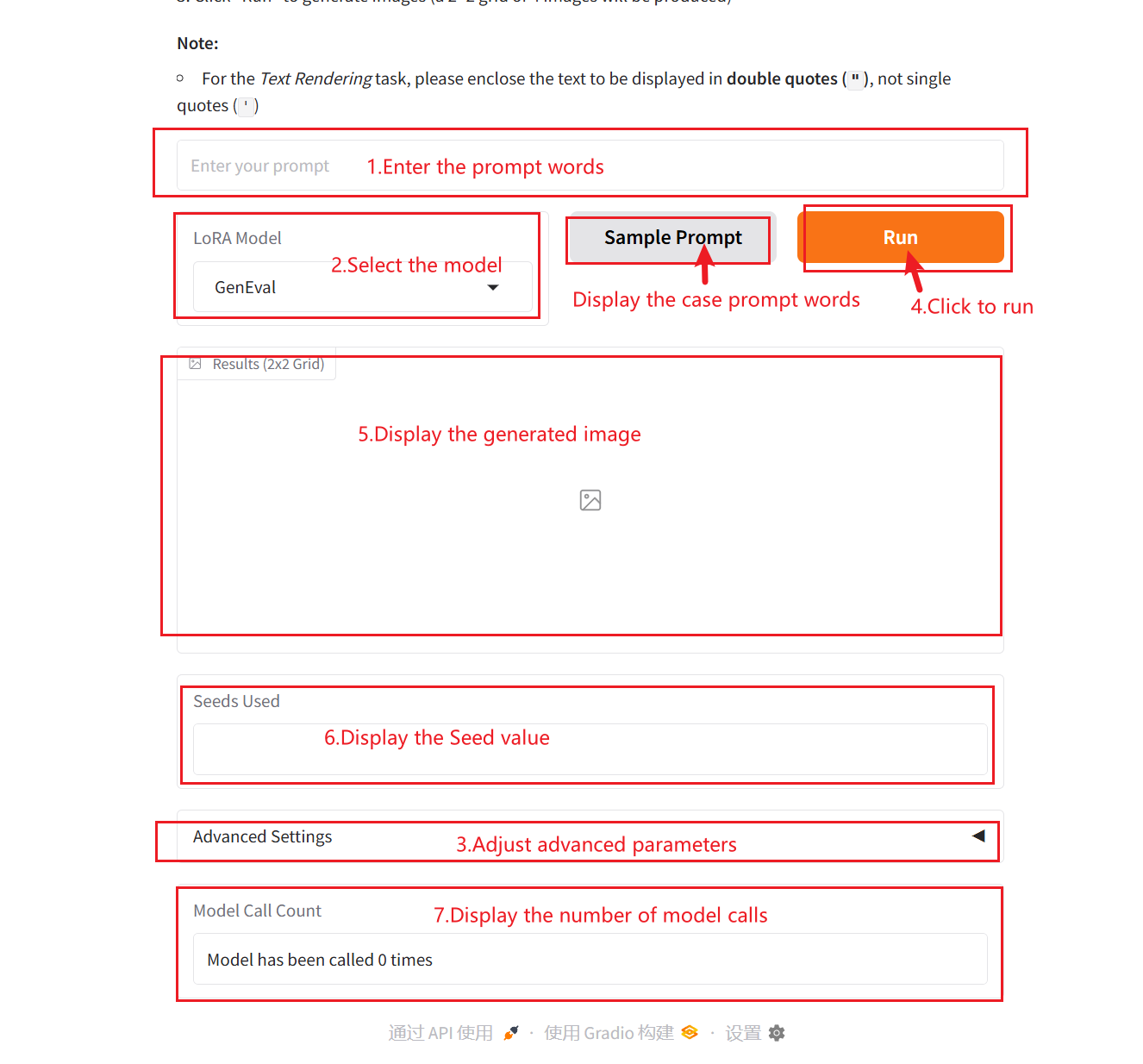
参数说明:
- LoRA Model:
- None: 基础模型原生调用,未引入优化策略。
- GenEval: 六维评估体系构建,支持复杂场景生成验证。
- Text Rendering: 精准文本视觉化,实现图文内容精确映射。
- Human Preference Alignment: 审美偏好量化对齐,集成 PickScore 评估框架
- Starting Seed: 随机数种子,用于控制生成过程中的随机性。相同的 Seed 值可以生成相同的结果(前提是其他参数相同),这在结果复现中非常重要。
- Width: 用于控制生成图片的宽。
- Height: 用于控制生成图片的高。
- Guidance scale: 它用于控制生成模型中条件输入(如文本或图像)对生成结果的影响程度。较高的指导值会让生成结果更加贴近输入条件,而较低的值会保留更多随机性。
- Number of inference Steps: 表示模型的迭代次数或推理过程中的步数, 代表模型用于生成结果的优化步数。更高的步数通常会生成更精细的结果,但可能增加计算时间。
四、交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

引用信息
感谢 Github 用户 xxxjjjyyy1 对本教程的部署。本项目引用信息如下:
@misc{liu2025flowgrpo,
title={Flow-GRPO: Training Flow Matching Models via Online RL},
author={Jie Liu and Gongye Liu and Jiajun Liang and Yangguang Li and Jiaheng Liu and Xintao Wang and Pengfei Wan and Di Zhang and Wanli Ouyang},
year={2025},
eprint={2505.05470},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2505.05470},
}该教程由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 [email protected] 以便及时审查和下架。