HyperAI
Command Palette
Search for a command to run...
VGGT:通用 3D 视觉模型
一、教程简介

VGGT 是由 Meta AI 团队与牛津大学视觉几何组(VGG)于 2025 年 3 月 28 日发布的前馈神经网络,可在几秒钟内从一个、几个或数百个视图中直接推断场景的所有关键 3D 属性,包括外部和内部摄像机参数、点图、深度图和 3D 点轨迹。它还兼具简单性和高效性,可在一秒内完成重建,甚至超越了需要借助视觉几何优化技术进行后处理的替代方法。相关论文成果为 VGGT: Visual Geometry Grounded Transformer,已被 CVPR 2025 接受并获得 CVPR 2025 最佳论文奖。
本教程采用资源为单卡 RTX 4090 。
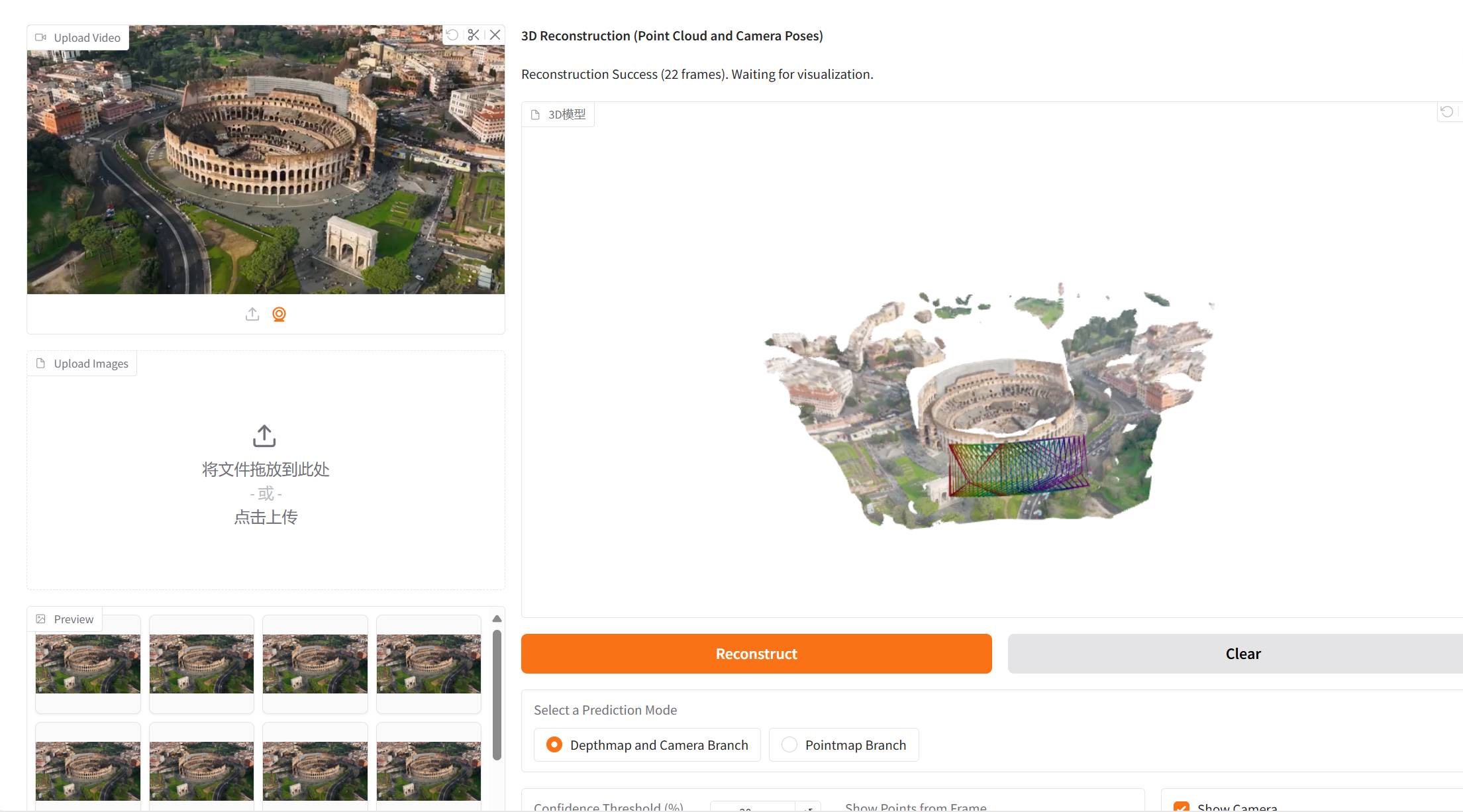
二、项目示例
三、运行步骤
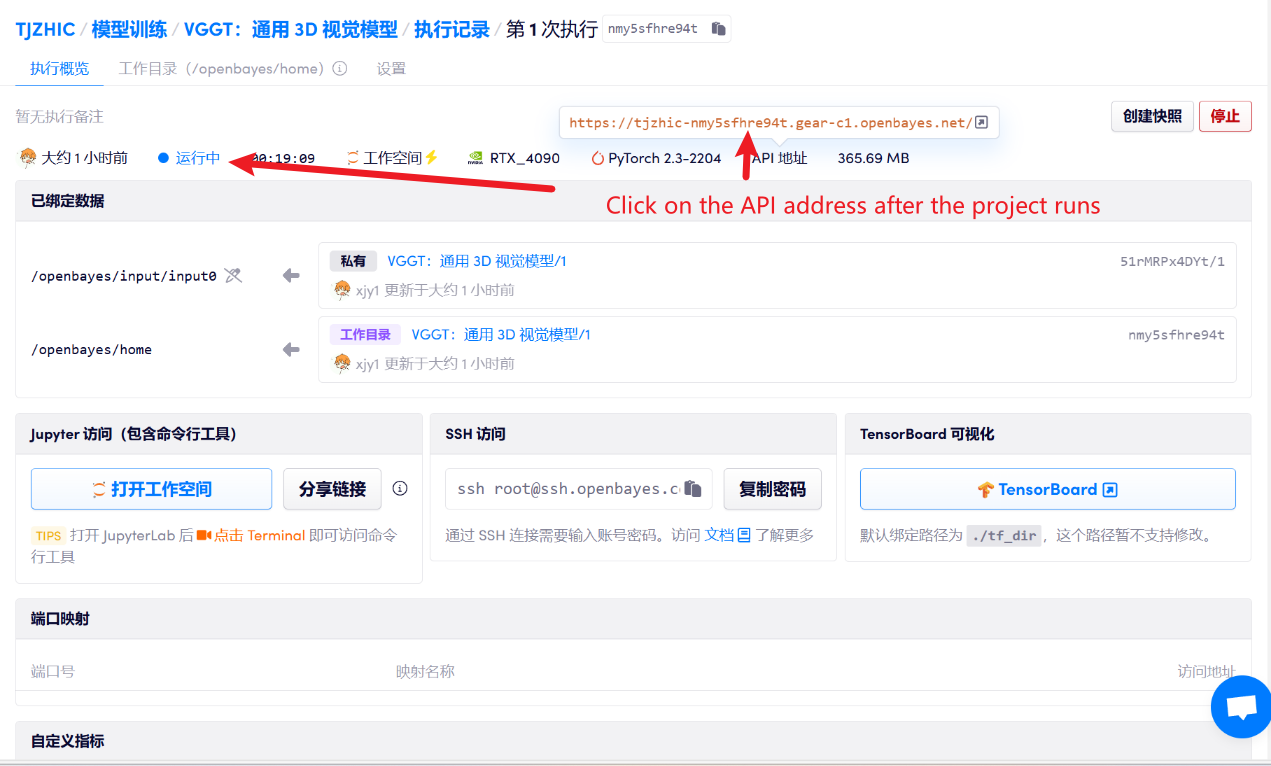
1. 启动容器后点击 API 地址即可进入 Web 界面
2. 进入网页后,即可使用模型
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 2-3 分钟后刷新页面。
使用步骤
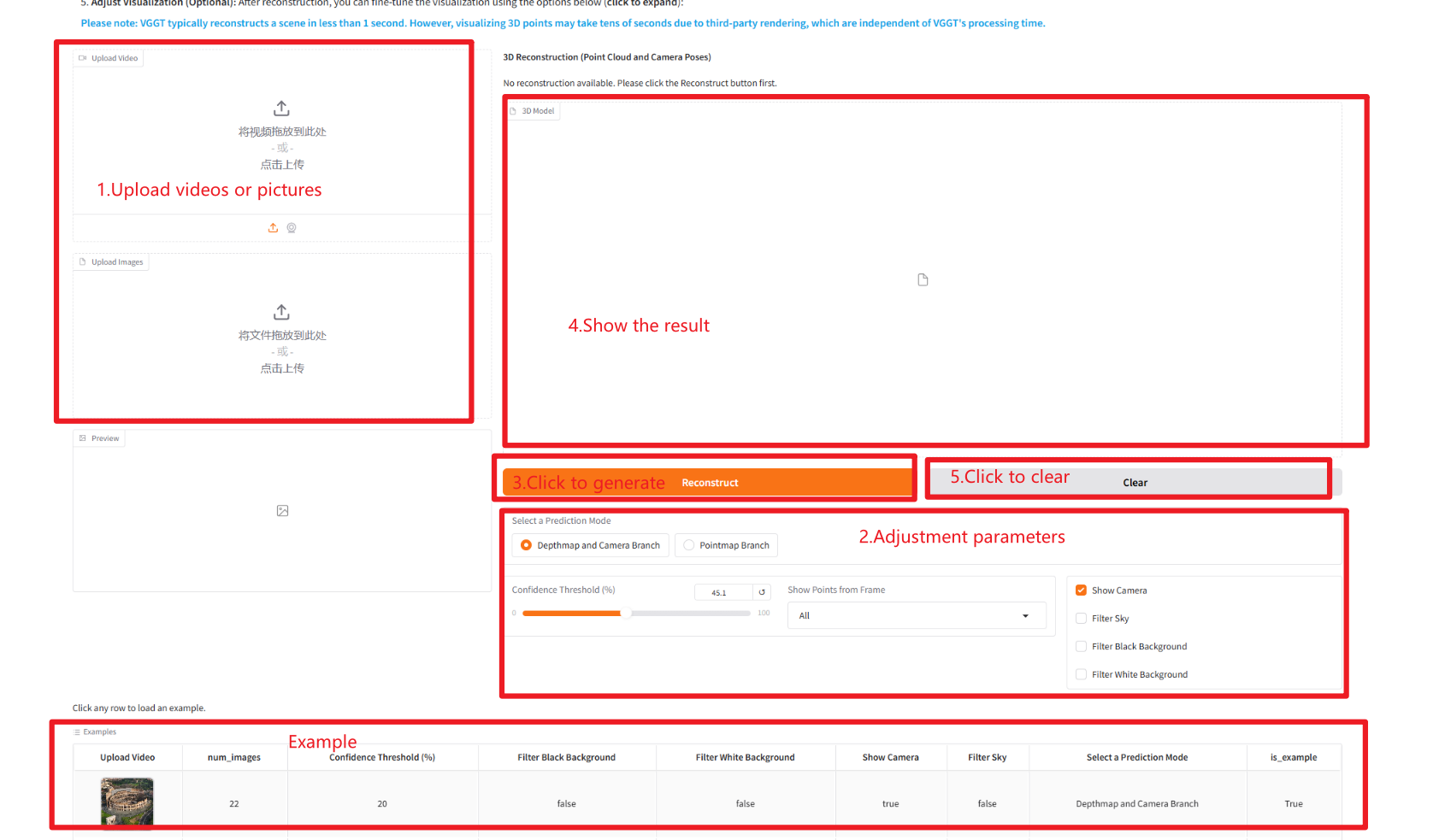
参数说明:
- Select a Prediction Mode:
- Depthmap and Camera Branch:使用深度图和相机位姿分支进行重建。
- Pointmap Branch:直接使用点云分支进行重建。
- Confidence Threshold:置信度阈值,用于筛选模型输出中的置信度较高的结果。
- Show Points from Frame:是否显示从所选帧提取的点。
- Show Camera:是否显示相机位姿。
- Filter Sky:是否过滤天空点。
- Filter Black Background:是否过滤背景为黑色的点。
- Filter White Background:是否过滤背景为白色的点。
四、交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

引用信息
本项目引用信息如下:
@inproceedings{wang2025vggt,
title={VGGT: Visual Geometry Grounded Transformer},
author={Wang, Jianyuan and Chen, Minghao and Karaev, Nikita and Vedaldi, Andrea and Rupprecht, Christian and Novotny, David},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2025}
}该教程由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 [email protected] 以便及时审查和下架。