HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

MMBench-GUI:面向GUI代理的分层多平台评估框架

深度研究者与测试时扩散




























MMBench-GUI:面向GUI代理的分层多平台评估框架
深度研究者与测试时扩散
LLM量化几何:GPTQ作为Babai的最近平面算法
MedIQA:一种可扩展的基于提示的医学图像质量评估基础模型
OS-MAP: 计算机使用代理在广度和深度上能走多远?
分层预算策略优化用于自适应推理
《电影导演:面向短片生成》
LAPO:通过长度自适应策略优化内化推理效率
MUR:基于动量不确定性的大语言模型推理
NABLA:邻域自适应块级注意力
组序列策略优化
olmOCR:利用视觉语言模型解锁PDF中的数万亿个Token
SafeWork-R1: 在AI-45法则下的安全与智能协同进化
解耦大语言模型中的知识与推理:基于认知双系统理论的探索
Re:Form -- 在LLMs中使用强化学习减少人类先验知识的可扩展形式化软件验证:关于Dafny的初步研究
RAVine:现实对齐的代理搜索评估
“一个领域能否帮助其他领域?”基于数据的多领域强化学习推理研究
DesignLab:通过迭代检测与修正设计幻灯片
Yume:一个交互式世界生成模型
像素、模式,但无诗意:像人类一样看世界
构建用于定位诊断协作的眼科多模态LLM通过临床认知链推理
HySafe-AI:AI系统混合安全架构分析框架:案例研究
斑马-CoT:一种交叉视觉语言推理数据集
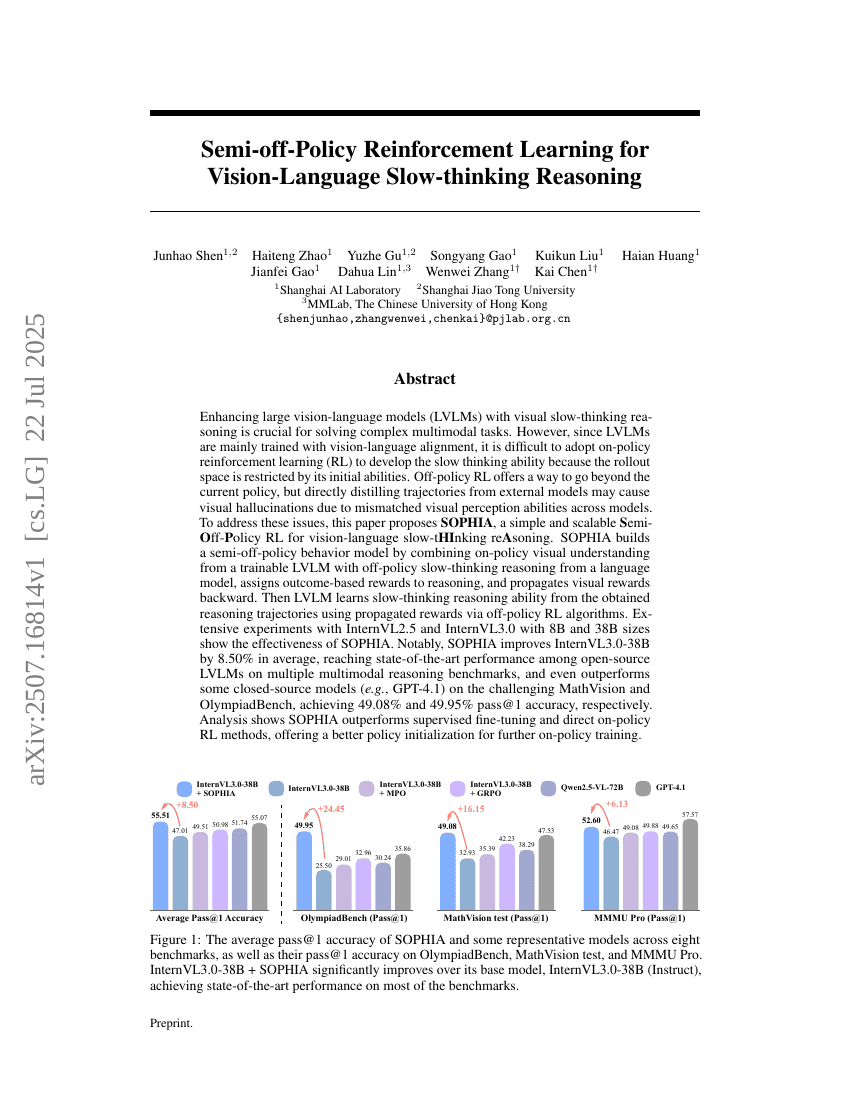
基于视觉-语言慢思考的半离策略强化学习
上采样关键区域:面向加速扩散变换器的区域自适应潜在采样
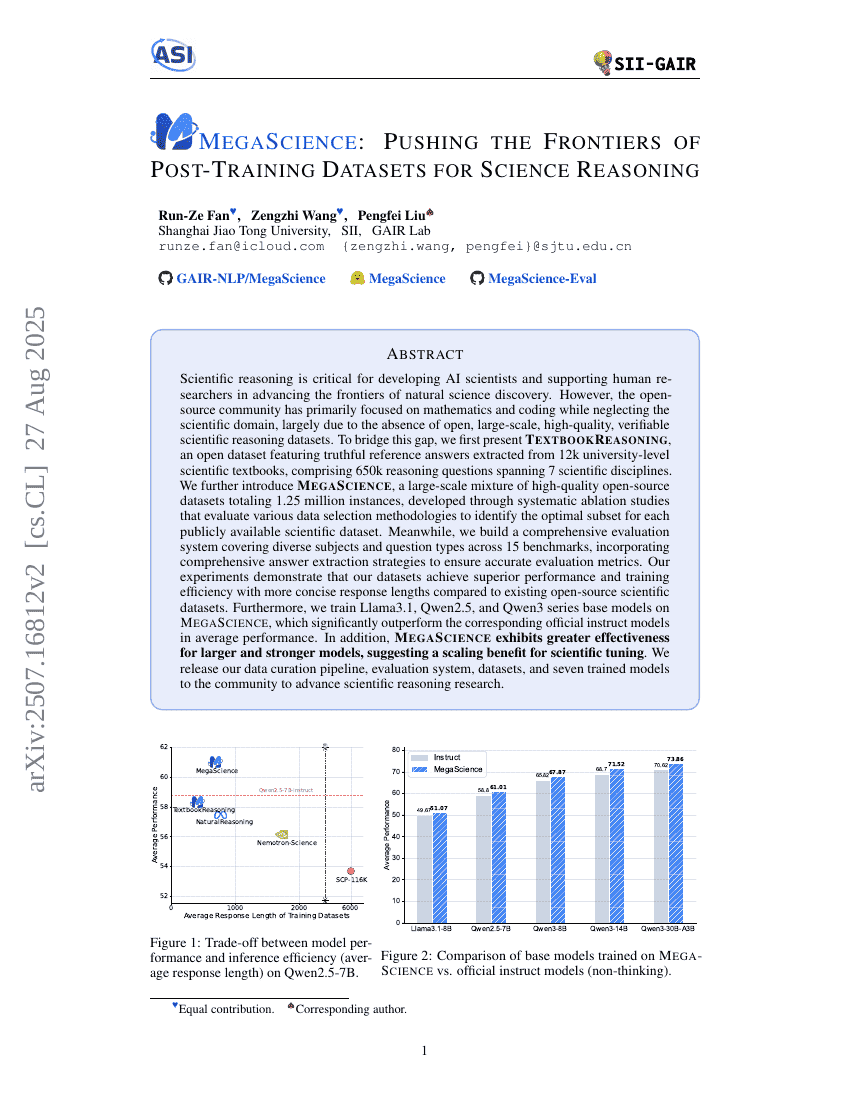
《MegaScience:推动科学推理的训练后数据集前沿》
Step-Audio 2 技术报告
超越上下文限制:用于长时程推理的潜意识线索
前沿人工智能风险管理框架实践:风险分析技术报告
具有不确定性感知的知识转换器在多智能体强化学习中的对等能源交易研究
无需人类参与:自主高质量图像编辑三元组挖掘
基于正则化分数蒸馏采样的 3D 高斯点云中鲁棒的 3D 掩码部分级编辑
LLM量化几何:GPTQ作为Babai的最近平面算法
MedIQA:一种可扩展的基于提示的医学图像质量评估基础模型
OS-MAP: 计算机使用代理在广度和深度上能走多远?
分层预算策略优化用于自适应推理
《电影导演:面向短片生成》
LAPO:通过长度自适应策略优化内化推理效率
MUR:基于动量不确定性的大语言模型推理
NABLA:邻域自适应块级注意力
组序列策略优化
olmOCR:利用视觉语言模型解锁PDF中的数万亿个Token
SafeWork-R1: 在AI-45法则下的安全与智能协同进化
解耦大语言模型中的知识与推理:基于认知双系统理论的探索
Re:Form -- 在LLMs中使用强化学习减少人类先验知识的可扩展形式化软件验证:关于Dafny的初步研究
RAVine:现实对齐的代理搜索评估
“一个领域能否帮助其他领域?”基于数据的多领域强化学习推理研究
DesignLab:通过迭代检测与修正设计幻灯片
Yume:一个交互式世界生成模型
像素、模式,但无诗意:像人类一样看世界
构建用于定位诊断协作的眼科多模态LLM通过临床认知链推理
HySafe-AI:AI系统混合安全架构分析框架:案例研究
斑马-CoT:一种交叉视觉语言推理数据集
基于视觉-语言慢思考的半离策略强化学习
上采样关键区域:面向加速扩散变换器的区域自适应潜在采样
《MegaScience:推动科学推理的训练后数据集前沿》
Step-Audio 2 技术报告
超越上下文限制:用于长时程推理的潜意识线索
前沿人工智能风险管理框架实践:风险分析技术报告
具有不确定性感知的知识转换器在多智能体强化学习中的对等能源交易研究
无需人类参与:自主高质量图像编辑三元组挖掘
基于正则化分数蒸馏采样的 3D 高斯点云中鲁棒的 3D 掩码部分级编辑