HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
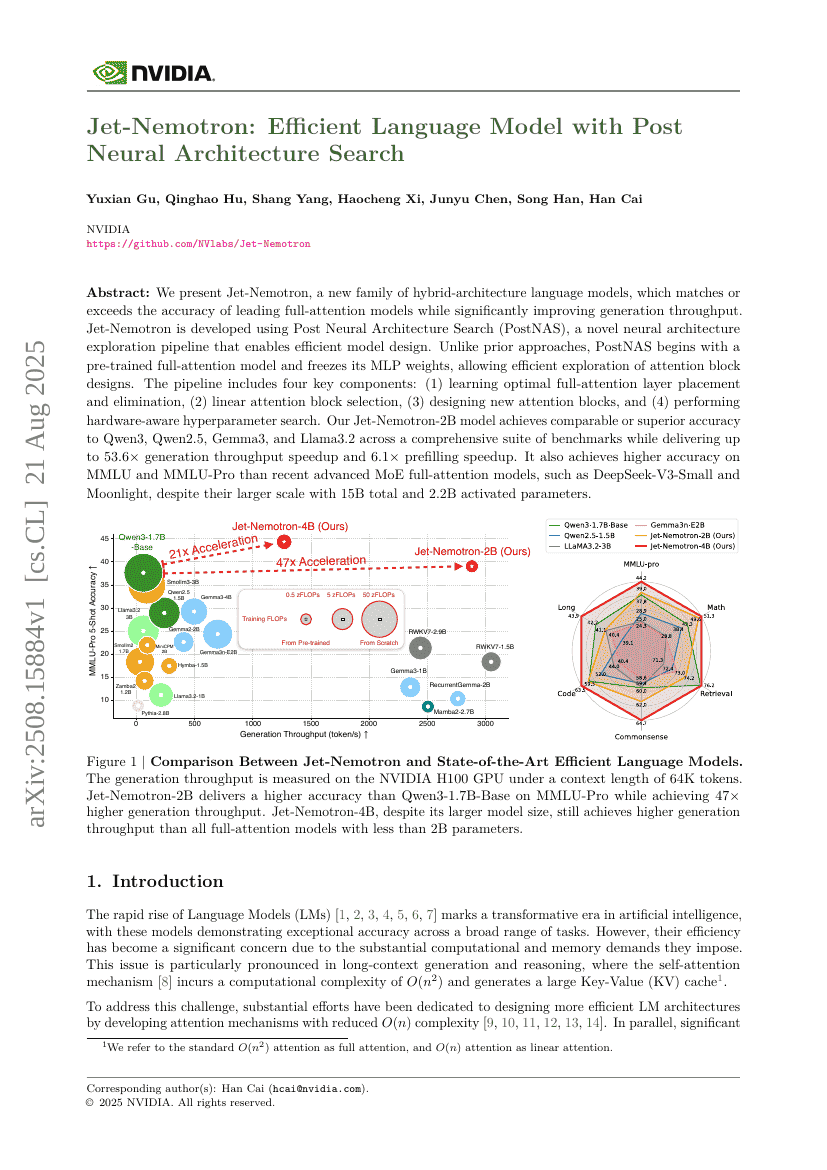
Jet-Nemotron:基于后神经架构搜索的高效语言模型

CRISP:通过稀疏自编码器实现的持久概念遗忘
























Jet-Nemotron:基于后神经架构搜索的高效语言模型
CRISP:通过稀疏自编码器实现的持久概念遗忘
弱监督可操作性定位中的选择性对比学习
EgoTwin:第一人称视角下的身体与视图梦境
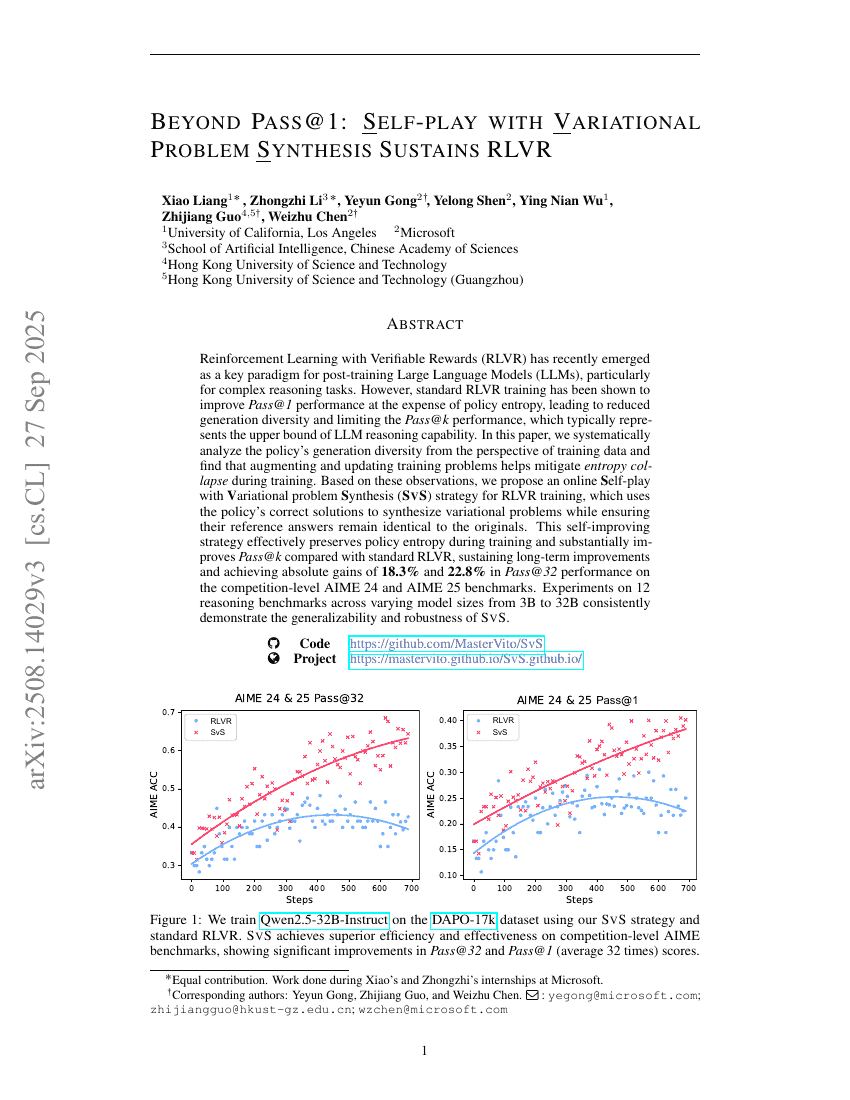
超越Pass@1:基于变分问题生成的自对弈持续提升RLVR
ODYSSEY:面向长时程任务的开放世界四足动物探索与操作
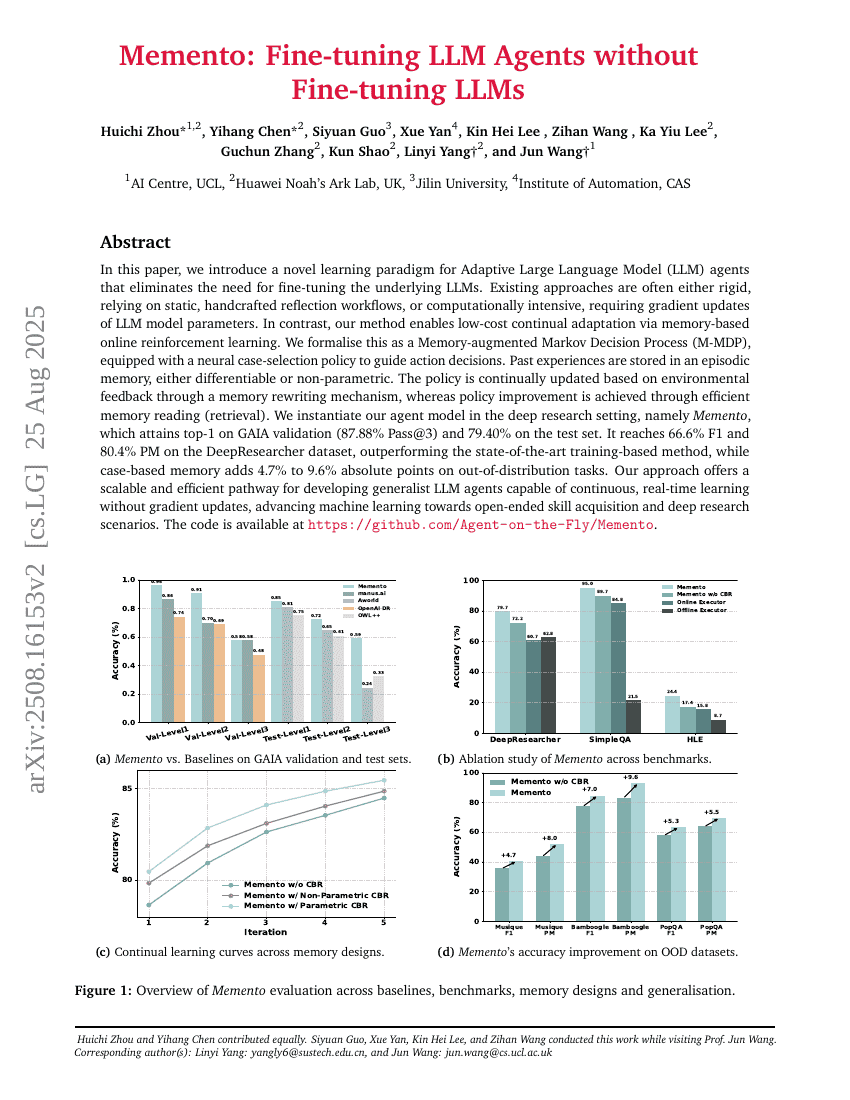
AgentFly:在不微调LLM的情况下微调LLM Agent
约束引导的扩散推理器用于神经符号学习
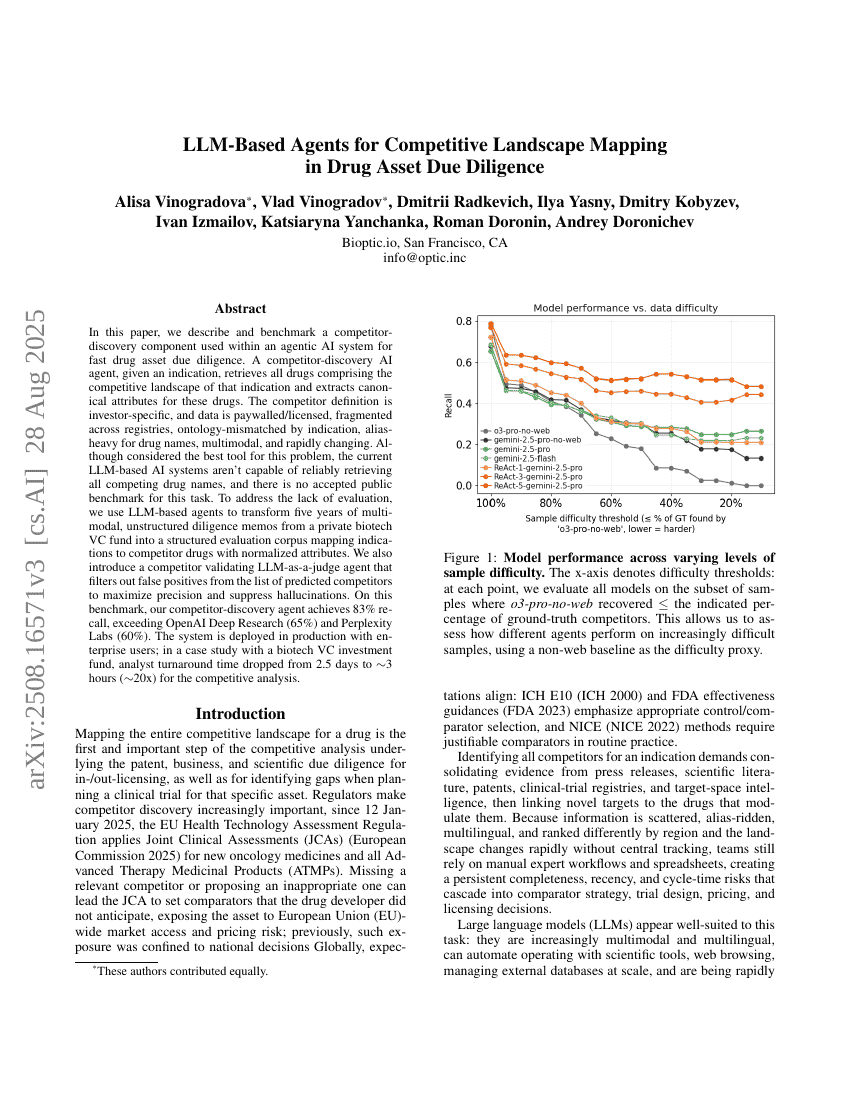
基于LLM的智能体在药物资产尽职调查中的竞争格局映射
SceneGen:单图像3D场景生成的一次前向传播
大语言模型基准测试综述
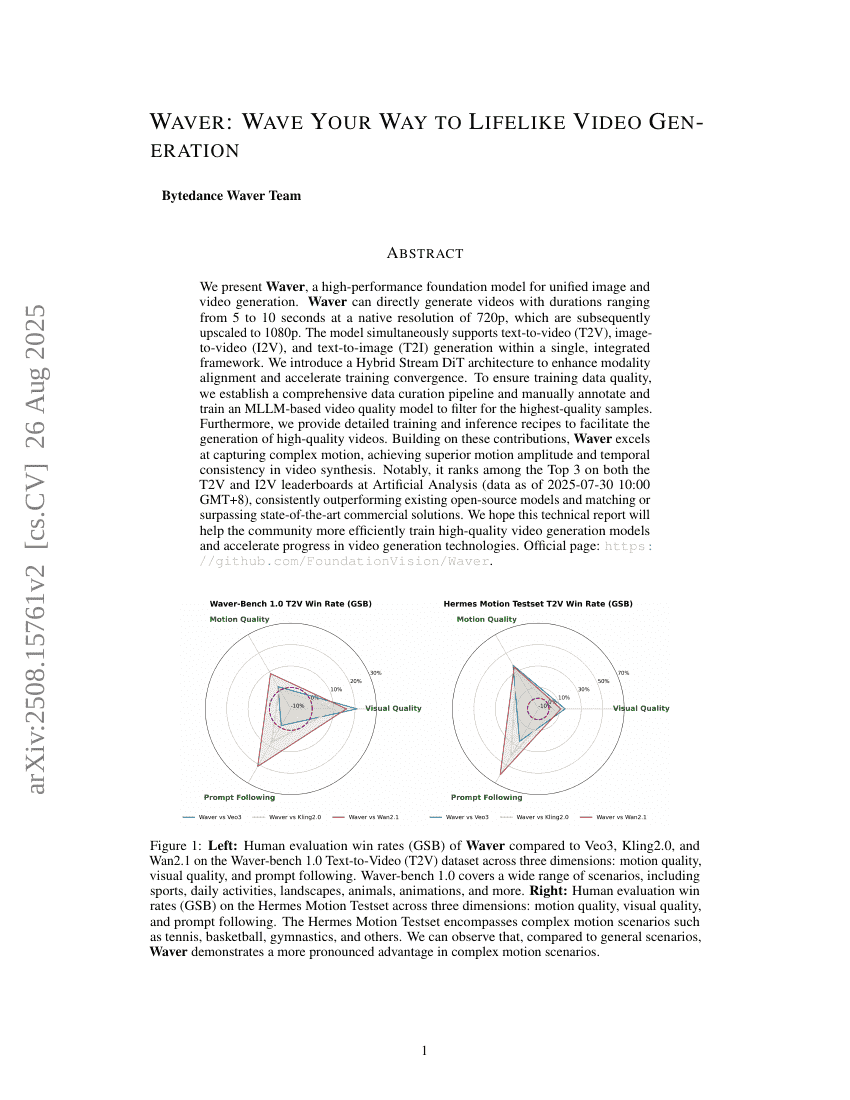
Waver:以波形之姿实现逼真视频生成
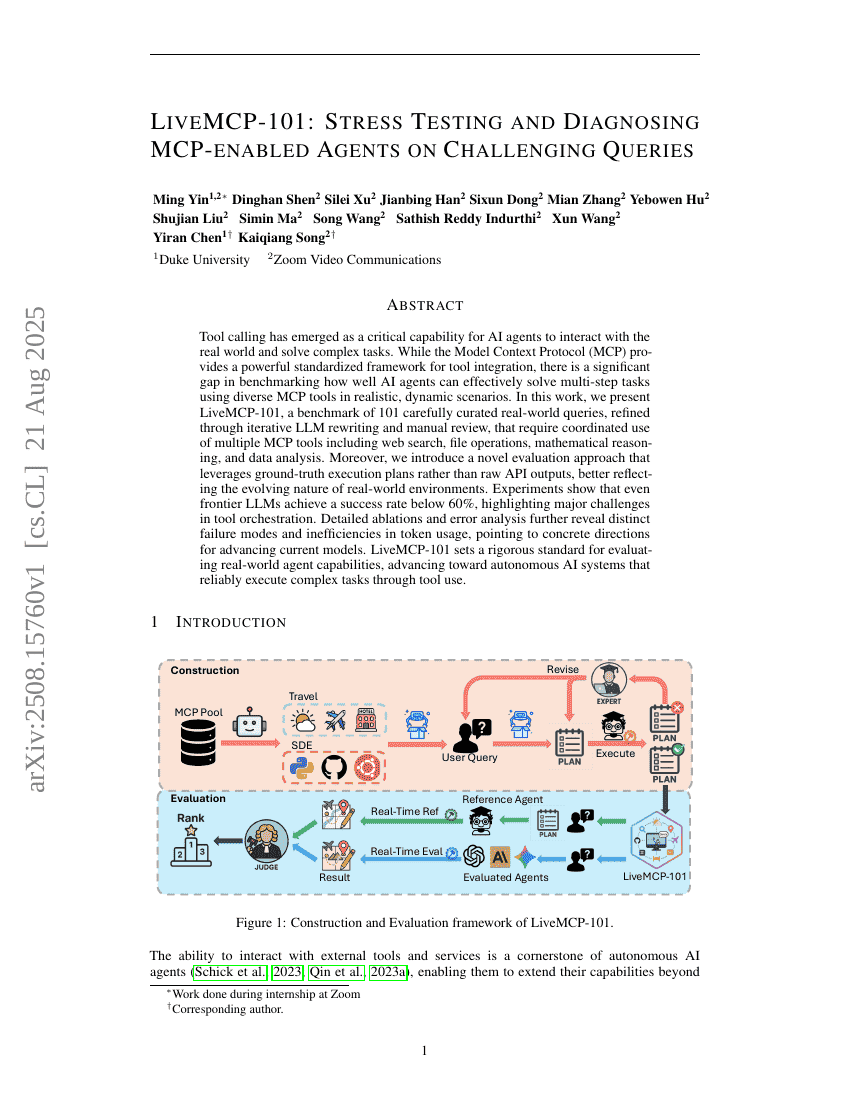
LiveMCP-101:在复杂查询上对MCP增强型Agent进行压力测试与诊断
自信地深度思考
Mobile-Agent-v3:GUI自动化的基础智能体
Intern-S1:一种科学多模态基础模型
语言引导微调:利用文本反馈增强数值优化
NiceWebRL:一个用于强化学习环境的人类被试实验的Python库
从科学的人工智能到代理科学:自主科学发现综述
MeshCoder:基于LLM的点云结构化网格代码生成
Tinker:扩散模型馈赠3D——无需场景级优化的稀疏输入多视角一致性编辑
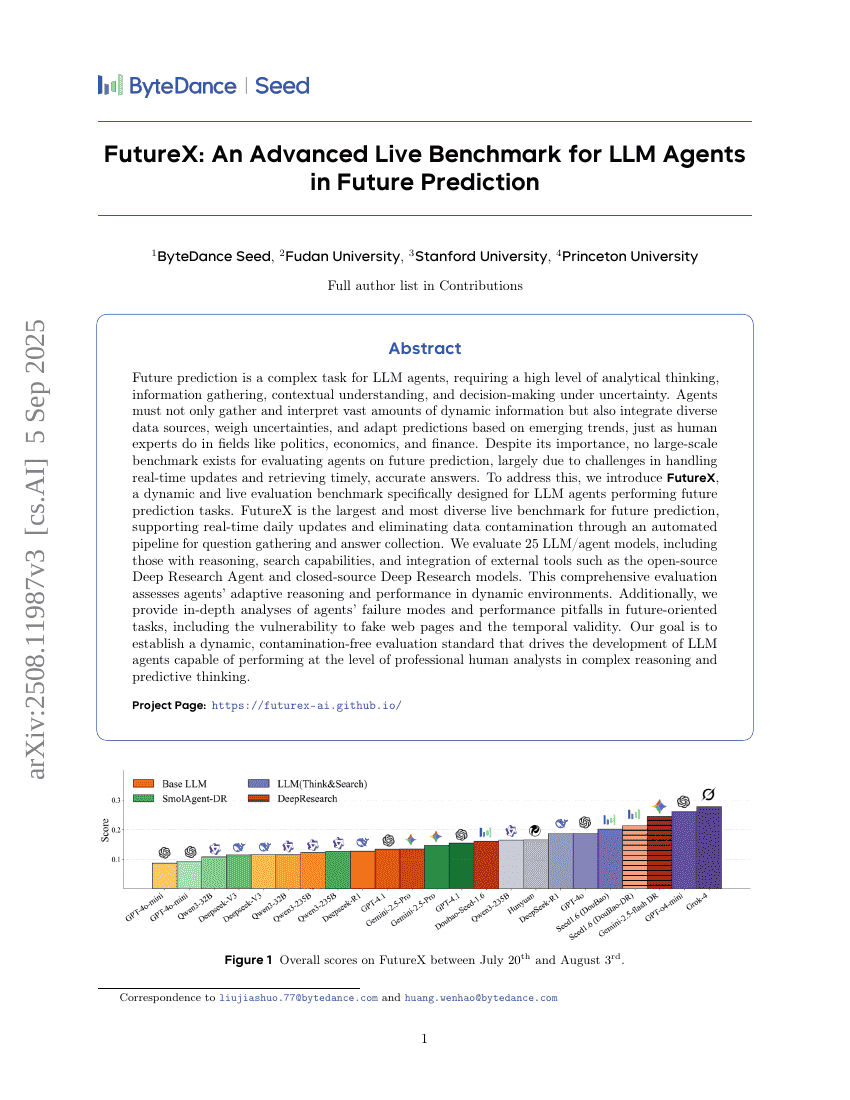
FutureX:面向未来预测任务的LLM Agent高级实时基准
DuPO:通过双偏好优化实现可靠的LLM自我验证
从分数到能力:一种用于评估金融领域大语言模型的认知诊断框架
Granary:25种欧洲语言的语音识别与翻译数据集
TransLLM:通过可学习提示实现城市交通的统一多任务基础框架
量化与dLLMs的结合:面向扩散LLM的后训练量化系统性研究
无需训练的文本引导多模态扩散Transformer颜色编辑
基于用户画像感知的LLM-as-a-Judge的播客推荐评估
MultiRef:基于多个视觉参考的可控图像生成
提示编排标记语言
LongSplat:适用于随意长视频的鲁棒非对齐3D高斯点阵
弱监督可操作性定位中的选择性对比学习
EgoTwin:第一人称视角下的身体与视图梦境
超越Pass@1:基于变分问题生成的自对弈持续提升RLVR
ODYSSEY:面向长时程任务的开放世界四足动物探索与操作
AgentFly:在不微调LLM的情况下微调LLM Agent
约束引导的扩散推理器用于神经符号学习
基于LLM的智能体在药物资产尽职调查中的竞争格局映射
SceneGen:单图像3D场景生成的一次前向传播
大语言模型基准测试综述
Waver:以波形之姿实现逼真视频生成
LiveMCP-101:在复杂查询上对MCP增强型Agent进行压力测试与诊断
自信地深度思考
Mobile-Agent-v3:GUI自动化的基础智能体
Intern-S1:一种科学多模态基础模型
语言引导微调:利用文本反馈增强数值优化
NiceWebRL:一个用于强化学习环境的人类被试实验的Python库
从科学的人工智能到代理科学:自主科学发现综述
MeshCoder:基于LLM的点云结构化网格代码生成
Tinker:扩散模型馈赠3D——无需场景级优化的稀疏输入多视角一致性编辑
FutureX:面向未来预测任务的LLM Agent高级实时基准
DuPO:通过双偏好优化实现可靠的LLM自我验证
从分数到能力:一种用于评估金融领域大语言模型的认知诊断框架
Granary:25种欧洲语言的语音识别与翻译数据集
TransLLM:通过可学习提示实现城市交通的统一多任务基础框架
量化与dLLMs的结合:面向扩散LLM的后训练量化系统性研究
无需训练的文本引导多模态扩散Transformer颜色编辑
基于用户画像感知的LLM-as-a-Judge的播客推荐评估
MultiRef:基于多个视觉参考的可控图像生成
提示编排标记语言
LongSplat:适用于随意长视频的鲁棒非对齐3D高斯点阵