Command Palette
Search for a command to run...
MathNet:一个用于数学推理与检索的全球多模态基准测试
MathNet:一个用于数学推理与检索的全球多模态基准测试
Shaden Alshammari Kevin Wen Abrar Zainal Mark Hamilton Navid Safaei Sultan Albarakati William T. Freeman Antonio Torralba
摘要
数学问题求解仍然是对大语言模型(Large Language Models)及多模态模型推理能力的一项艰巨挑战,然而现有的 benchmark 在规模、语言覆盖范围以及任务多样性方面均存在局限。我们推出了 MATHNET,这是一个高质量、大规模、多模态且多语言的奥数级数学问题数据集,并配套设计了一个 benchmark,用于评估生成式模型中的数学推理能力,以及基于 embedding 的系统中的数学检索能力。MATHNET 涵盖了 47 个国家、17 种语言以及过去二十年的竞赛内容,包含 30,676 个由专家编写的、跨越不同领域的数学问题及其解答。除了核心数据集外,我们还构建了一个检索 benchmark,其中包含由人类专家策划的数学等价且结构相似的问题对。MATHNET 支持三项任务:(i) 问题求解 (Problem Solving),(ii) 数学感知检索 (Math-Aware Retrieval),以及 (iii) 检索增强的问题求解 (Retrieval-Augmented Problem Solving)。实验结果表明,即使是目前最先进的推理模型(Gemini-3.1-Pro 为 78.4%,GPT-5 为 69.3%)仍面临挑战,而 embedding 模型在检索等价问题时表现欠佳。我们进一步证明,RAG 的性能对检索质量高度敏感;例如,DeepSeek-V3.2-Speciale 的性能提升高达 12%,并在该 benchmark 上取得了最高分。
一句话总结
研究人员推出了 MathNet,这是一个大规模多模态且多语言的基准测试,包含 30,676 个由专家编写的、涵盖 17 种语言的奥林匹克级别数学问题,用于评估生成式模型中的数学推理、基于 embedding 的系统中的数学感知检索,以及检索增强的问题解决能力。
核心贡献
- 本论文引入了 MATHNET,这是一个大规模、多模态且多语言的数据集,包含 30,676 个由专家编写的、涵盖 47 个国家和 17 种语言的奥林匹克级别数学问题及解答。
- 该工作建立了一个专门的检索基准,由人类专家策划的数学等价且结构相似的问题对组成,用于评估基于 embedding 的系统。
- 实验结果证明了该基准在三项任务中的实用性,表明即使是顶尖的推理模型在面对此类难度时也表现挣扎,且 RAG 的性能对检索质量高度敏感。
引言
数学问题解决是评估人工智能推理能力的基础基准。虽然现有数据集涵盖了多个领域,但往往存在规模有限、缺乏多语言和多模态内容,或缺乏针对高难度奥林匹克级别问题的专家验证解答等问题。此外,先前的检索系统经常难以弥合符号等价性与语义相似性之间的差距。通过引入 MathNet,一个具有专家验证问题对的大规模多语言和多模态数据集,填补了这些空白。通过结合细粒度的数学相似性分类法,研究人员能够在不同语言和模态下,对类比推理、检索质量以及检索增强生成进行更严谨的研究。
数据集
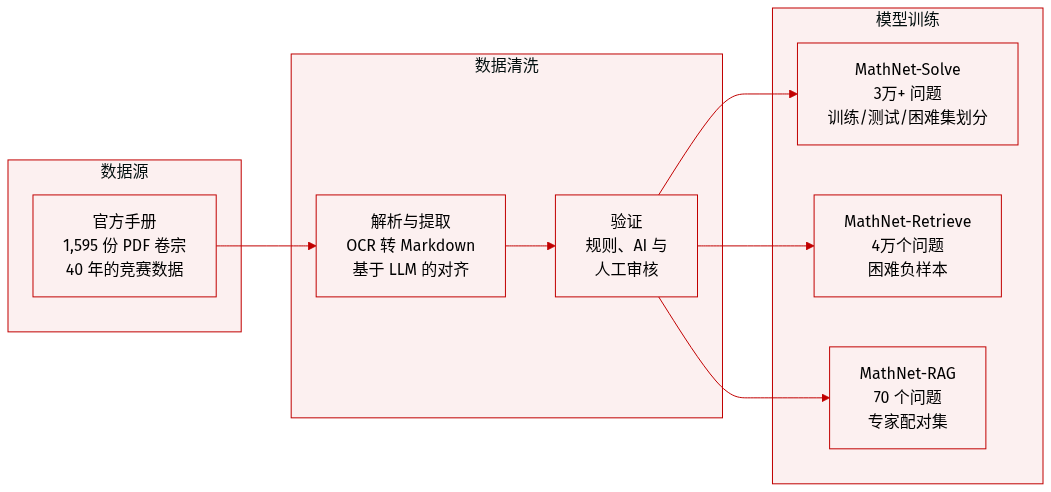
数据集概览:MathNet
MathNet 是一个旨在评估数学推理和检索的大规模多模态及多语言数据集。与依赖社区平台的现有基准不同,MathNet 完全构建自跨越 40 年(1985 年至 2025 年)的官方国家竞赛手册。
数据集组成与子集
语料库分为三个专门的数据集:
- MathNet-Solve: 核心集合,包含 30,676 个专家编写的奥林匹克问题及解答。涵盖 47 个国家和 17 种语言的 143 场竞赛。该子集分为三个部分:
- MathNet-Solve-train: 23,776 个样本。
- MathNet-Solve-test: 6,400 个样本。
- MathNet-Solve-test-hard: 500 个样本。
- MathNet-Retrieve: 一个由 40,000 个问题组成的检索评估数据集。通过从 MathNet-Solve 中提取 10,000 个锚点问题,并为每个问题生成一个数学等价的正样本变体和三个对抗性的“硬负样本”变体来构建。
- MathNet-RAG: 一个用于检索增强生成的非合成评估集。总共包含 70 个问题:35 个锚点问题与从 MathNet-Solve 中提取的 35 个专家策划的真实问题配对。
处理与提取流程
为了将异构的 PDF 卷转换为统一格式,采用了复杂的多阶段流程:
- 文档解析: 使用 dots-ocr 框架将 1,595 卷 PDF(超过 25,000 页)转换为 Markdown,能够处理数字排版和扫描文档。
- 问题-解答对齐: 为了处理编号不一致和交错布局,采用了基于 LLM 的三阶段流程。使用 Gemini-2.5-Flash 进行文档分段,使用 GPT-4.1 将问题和解答提取为对 LaTeX 友好的格式。
- 验证: 提取的问题对经过严格的三层验证过程,包括基于规则的分析检查器、GPT-4.1 对源截图的视觉检查,以及人工审核。只有当所有三种机制达成一致时,该问题对才会被保留。
- 元数据构建: 流程记录了每个条目的详细来源,包括国家、竞赛名称、年份和作者注释。
使用与评估任务
利用该数据在三个不同的数学任务上对模型进行基准测试:
- 问题解决: 通过将生成式模型生成的解答与 MathNet-Solve 中的专家参考解答进行比较来评估模型。
- 数学感知检索: 测试基于 embedding 的系统在 MathNet-Retrieve 中识别数学等价问题的能力,超越简单的词汇重叠。
- 检索增强问题解决 (RAG): 使用 MathNet-RAG 中的专家配对问题,评估检索质量如何影响推理性能。
方法
提出了一种全面的流程,旨在将原始数学文档转换为适合训练和评估大语言模型的高质量、结构化数据集。整体工作流始于对多样化源材料的摄取,其中包括跨越 40 多个国家和 40 年数学历史的 30,000 多个奥林匹克级别问题。
如下图所示:
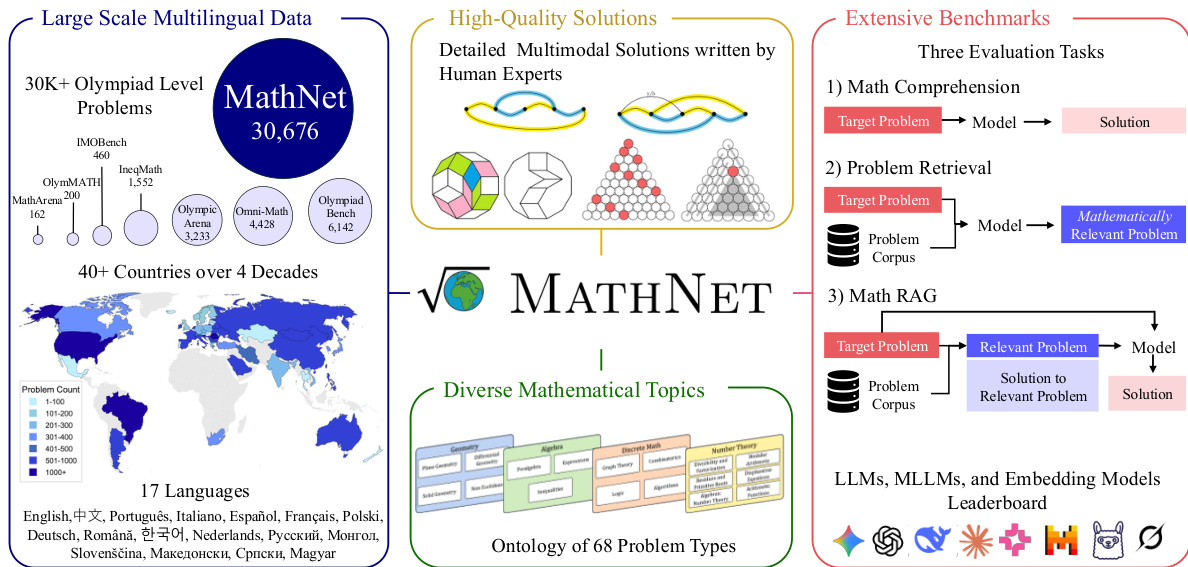
系统通过多阶段提取和分段流程处理输入的竞赛手册。首先,使用 DotsOCR 对 PDF 文件进行文本提取,同时捕获页面截图以保留视觉信息。随后,这些组件被转换为 Markdown 格式。处理引擎的核心涉及文档分段,将文本划分为离散的问题块和解答块。该分段由专门的模块支持,执行结构化解析、边界检测和问题-解答对齐,以确保每个数学挑战都能与其对应的严谨证明或答案正确配对。
分段完成后,系统使用 GPT-4.1 进行格式归一化,确保提取的内容符合一致的结构。随后是语义元数据提取阶段,按主题、难度和类型对问题进行分类。为了保持最高的数据完整性,流程中加入了人工验证步骤。最后阶段包括基于规则的源一致性检查以及交叉验证和去重过程,最终形成一个经过人工验证的高质量数学问题-解答对数据集。
生成的数据集支持三个主要的评估任务:数学理解、问题检索和 Math RAG(检索增强生成)。这种结构化方法允许针对复杂的数学推理任务,对 LLMs、MLLMs 和 embedding 模型进行严谨的基准测试。
实验
MATHNET 评估通过三个不同的任务来衡量模型能力:直接问题解决、等价问题的数学感知检索,以及检索增强问题解决。虽然前沿推理模型在解决复杂数学问题方面表现出令人印象深刻的性能,但目前的 embedding 模型由于依赖表层的词汇重叠而非深层的结构理解,在数学感知检索方面表现挣扎。因此,只有当检索到的上下文在数学和结构上与目标问题对齐时,检索增强生成才能提供持续的改进。
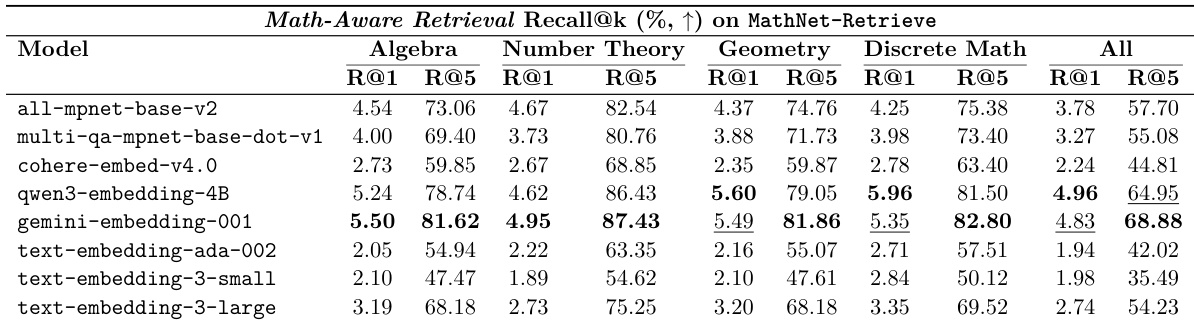
在 MathNet-Retrieve 基准上评估了各种 embedding 模型,以衡量其在不同数学领域执行数学感知检索的能力。结果显示,虽然在 top-1 级别的检索准确度普遍较低,但随着检索候选数量的增加,性能显著提升。Gemini-embedding-001 在所有领域中对于 Recall@1 和 Recall@5 都实现了最高的整体性能。在所有测试的模型和学科中,Recall@5 级别的检索准确度始终高于 Recall@1 级别。与较新的专门模型或更大的 embedding 模型相比,传统的文本 embedding 模型通常表现出较低的检索性能。
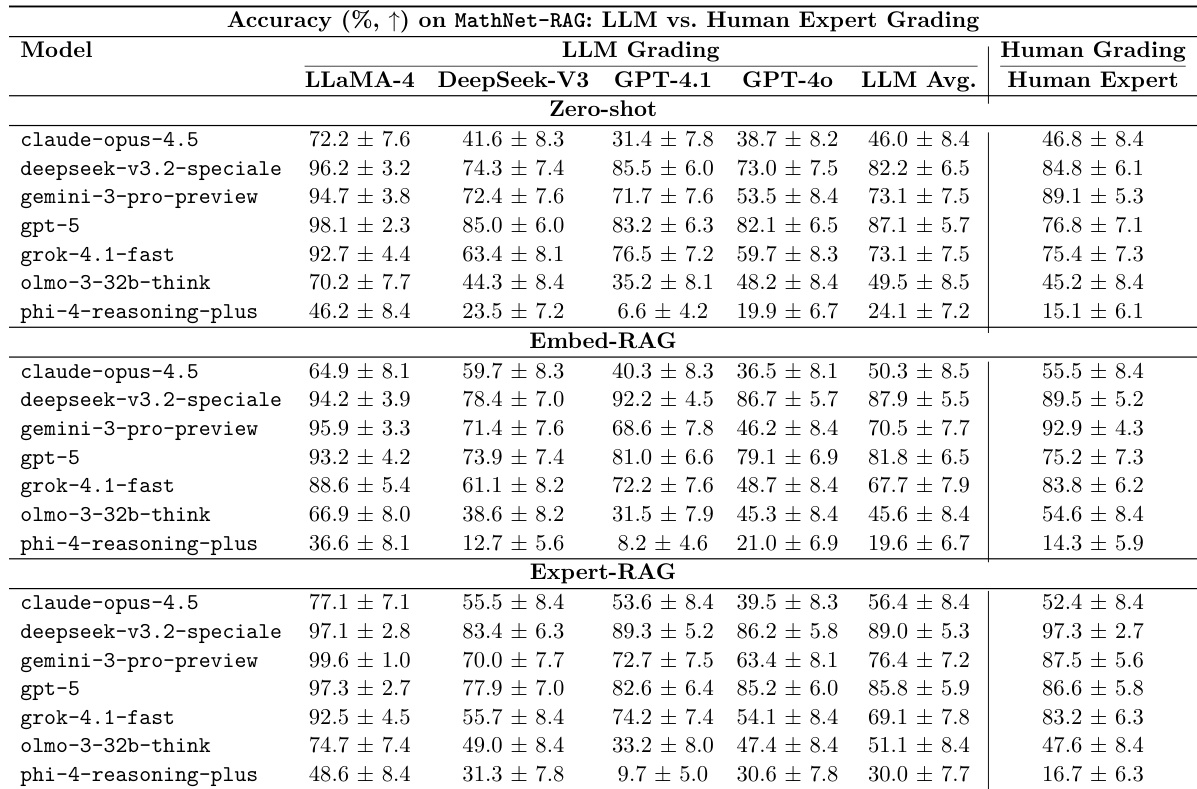
通过人类评分和 LLM 评分评估了检索增强生成对数学问题解决的影响。结果显示,与 zero-shot 设置相比,提供专家策划的、结构相似的问题作为上下文通常可以提高性能。在大多数评估的模型中,Expert-RAG 在人类评分下始终产生最高的准确度。与 zero-shot 基准相比,基于检索的增强为中层模型提供了显著的性能提升。LLM 评分结果在模型性能趋势方面与人类专家的评估基本一致。
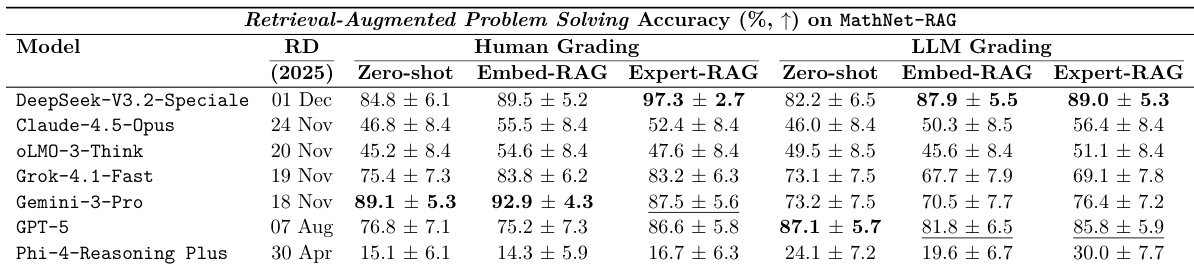
通过人类和 LLM 评分评估了检索增强生成对数学问题解决的影响。结果显示,通过 Expert-RAG 提供与 ground-truth 相关的题目,与 zero-shot 设置相比能持续提高性能。Expert-RAG 在大多数模型中提供了最显著且最一致的性能提升。基于 embedding 的检索结果显示出高方差,有时甚至会导致性能下降。检索带来的性能提升对于低层和中层求解器尤为显著。
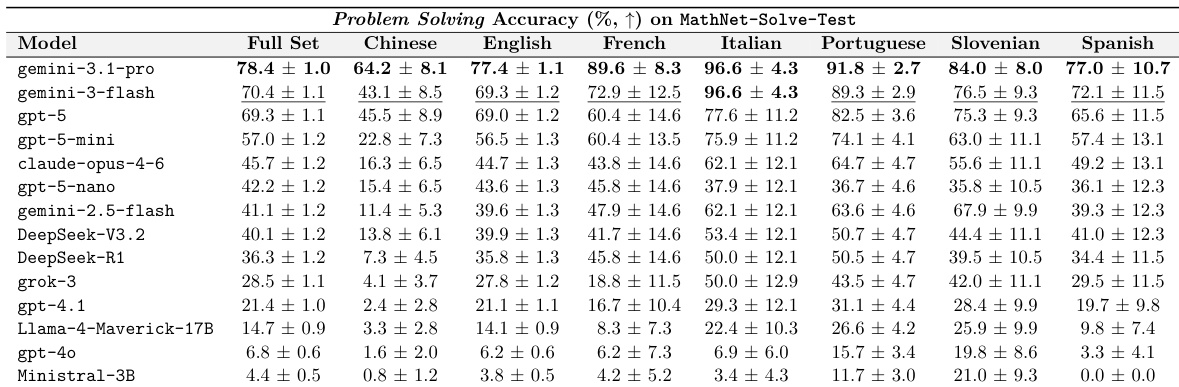
在 MathNet-Solve-Test 数据集上评估了各种模型在多种语言下的问题解决准确度。结果显示,前沿推理模型实现了最高的整体性能,而性能因所使用的特定语言而异。与其它测试系统相比,gemini-3.1-pro 等前沿模型表现出最高的整体准确度。在某些语言(如意大利语和葡萄牙语)上的模型性能明显高于其他语言(如中文)。最先进的推理模型与较小或早期代际模型之间存在巨大的性能差距。
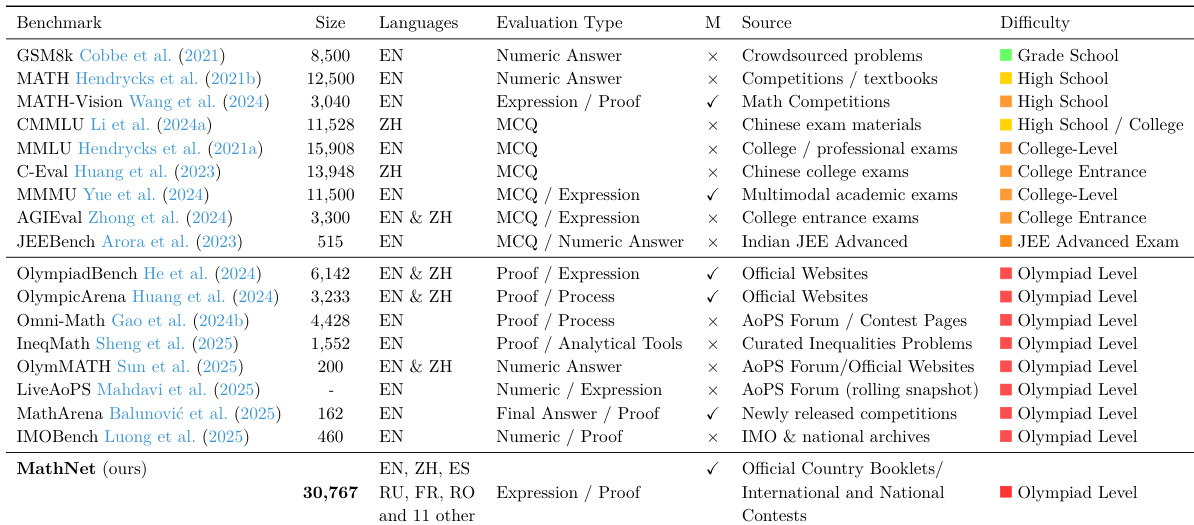
通过在规模、语言覆盖范围和难度等多个维度将 MathNet 与现有的几个数学推理基准进行比较。与调查的数据集相比,MathNet 通过提供更大的规模和更广泛的多语言支持脱颖而出。与现有基准相比,MathNet 提供了显著更大的规模和更广泛的语言支持。虽然大多数现有基准侧重于小学或高中水平,但 MathNet 专注于奥林匹克级别的难度。MathNet 利用基于表达式和证明的评估类型来评估数学推理。
通过评估 embedding 模型的检索能力、检索增强生成 (RAG) 对问题解决准确性的有效性,以及各种推理模型在多种语言下的性能,对 MathNet 基准进行了评估。结果表明,专门的 embedding 模型和专家策划的 RAG 显著增强了数学推理能力,特别是对于中层模型,而前沿推理模型在不同的语言语境下保持了实质性的性能领先。最终,MathNet 通过提供更大的规模、更广泛的多语言支持以及专注于奥林匹克级别数学推理的高难度水平,使其区别于现有的基准。