Command Palette
Search for a command to run...
Nemotron 3 Ultra:用于智能体推理的开放、高效混合专家混合 Mamba-Transformer 模型
Nemotron 3 Ultra:用于智能体推理的开放、高效混合专家混合 Mamba-Transformer 模型
摘要
我们推出了 Nemotron 3 Ultra,这是一种拥有 5500 亿总参数和 550 亿激活参数的混合 Mamba-Attention 专家混合(Mixture-of-Experts, MoE)语言模型。Nemotron 3 Ultra 首先基于 20 万亿个文本 token 进行预训练,随后将上下文长度扩展至 100 万 token,并通过监督微调(Supervised Fine-Tuning, SFT)、强化学习(Reinforcement Learning, RL)和多教师在线策略蒸馏(Multi-teacher On-Policy Distillation, MOPD)进行后训练。Nemotron 3 Ultra 是我们迄今为止最强大的模型,它采用了多项关键技术,包括 LatentMoE、多 token 预测(Multi-Token Prediction, MTP)、NVFP4 预训练、多环境 RLVR(Reinforcement Learning with Verifiable Rewards)、MOPD 以及推理预算控制。与目前最先进的公开 LLM 相比,Nemotron 3 Ultra 的推理吞吐量最高提升约 6 倍,同时保持了相当的准确率。凭借最先进的准确率、极高的推理吞吐量以及 100 万 token 的上下文长度,Nemotron 3 Ultra 成为运行长期自主 Agentic 任务的理想选择。我们已在 HuggingFace 上开源了基础模型、后训练模型及量化后的 Checkpoint,并公布了训练数据和训练配方(recipe)。
一句话总结
作者介绍了 Nemotron 3 Ultra,这是一个 5500 亿总参数和 550 亿活跃参数的 Mixture-of-Experts Hybrid Mamba-Transformer 模型,在 20 万亿 tokens 上预训练,具有 100 万 token 上下文,采用 LatentMoE、Supervised Fine Tuning、Reinforcement Learning 和 Multi-teacher On-Policy Distillation,实现了比最先进的公开可用 LLMs 高达六倍的推理吞吐量,同时保持相当的准确性,并开源了基础、后训练和量化检查点,以及用于自主 Agent 推理任务的训练数据和方案。
核心贡献
- 本文介绍了 Nemotron 3 Ultra,这是一个 5500 亿总参数和 550 亿活跃参数的 Mixture-of-Experts Hybrid Mamba-Attention 语言模型。该架构采用了包括 LatentMoE、Multi Token Prediction 和 NVFP4 预训练在内的关键技术以优化性能。
- 训练流程在 20 万亿 text tokens 上预训练,并使用 Supervised Fine Tuning、Reinforcement Learning 和 Multi-teacher On-Policy Distillation 将上下文长度扩展到 100 万 tokens。此外还结合了 multi-environment RLVR 和 reasoning budget control 等技术,以支持复杂的推理和长期运行的自主 Agent 任务。
- 实验表明,与最先进的公开可用 LLMs 相比,推理吞吐量高达约 6 倍,同时达到相当的准确性。基础、后训练和量化检查点在 HuggingFace 上开源,同时包括训练数据和方案。
引言
随着大语言模型应用从简单的聊天机器人演变为能够进行复杂推理和编码的自主 agents,对快速高效推理的需求显著增长。现有模型通常因标准 attention 机制的计算开销和大的 key-value cache 占用而难以在准确性和推理吞吐量之间取得平衡。作者展示了 Nemotron 3 Ultra,它利用 Mixture-of-Experts hybrid Mamba-Attention 架构来降低 attention 成本,同时保持性能。这种方法在 long-context 任务上比竞争模型提供了高达 5.9 倍的推理吞吐量,同时在 agentic 和推理基准上实现了相当的准确性。
数据集
数据集组成与来源
- 作者将数据组织为预训练和后训练阶段,并在 HuggingFace 上发布了新数据集。
- 预训练语料涵盖 19 个高级类别,包括网络爬取数据、数学、代码、Wikipedia、学术文本、法律数据和 11 种语言的 multilingual content。
- 后训练数据旨在通过 SFT 和 RL 阶段提高 agentic、推理和通用模型能力。
- 来源包括公共数据集、合成生成流程以及来自 OpenResearcher 和 GitHub 等存储库的商业许可子集。
每个子集的关键细节
- 预训练代码: 包括截至 2025 年 9 月 30 日来自 GitHub 的 1730 亿 tokens 新鲜代码数据。
- 预训练法律: 包含精选的 HTML 文件(例如加州法规)、LLM 清理的摘要(来自 Caselaw 的 540 万条)以及用于分类和 QA 的合成数据集。消融研究显示 LegalBench 准确性从 64.6 提高到 74.7。
- 预训练专业领域: 包含涵盖 STEM、数学、代码和推理领域的合成问答数据,格式为 Multiple-Choice 和 Generative。未使用保留测试集进行数据生成以保持评估完整性。
- 预训练事实查询: 分两个阶段从 Finewiki 陈述生成,以提高事实回忆。
- 后训练安全: 最终混合包含约 13.5 万 samples,包括 4.5 万英文和 6 种翻译语言各 1.5 万。反向翻译期间语义相似度低于 0.8 的示例被过滤,每种语言移除约 10% 到 15% 的示例。
- 后训练搜索: 包括来自 OpenResearcher 商业许可子集的 2.17 万 trajectories 和需要 50 到 100 次搜索的挑战性 samples。
- 后训练终端使用: 包含约 37 万 multi-turn conversations,涵盖软件工程和数据处理,使用 DeepSeek-V3.2 作为 agent 生成。
- 后训练代码: 产生来自竞争性编程平台的 120 万 Python 和 100 万 C++ reasoning traces,以及 130 万 Python tool-calling traces。
- 后训练数学: 来源包括 180 万 tool-calling samples 和 190 万 non-tool samples,以及来自 Nemotron-Math-Proofs-v1 的 AOPS 分区的 proof data。
- 后训练 CUDA: 一个约 10 万 samples 的合成数据集,用于 kernel generation、repair 和 optimization,在内部评估环境中验证。
- 后训练 RTL: 包含来自 ACE-RTL 的约 120 万 samples,涵盖 specification-to-RTL generation、code editing 和 debugging。
数据使用与混合
- 预训练数据遵循两阶段课程,第一阶段偏向数据集多样性,第二阶段偏向数据集质量。
- 阶段之间的转换发生在约 15 万亿 tokens 之后,对应于预训练的大约 75%。
- 质量过滤的网络爬取数据是最大的组成部分,占第一阶段 tokens 的约 49% 和第二阶段 tokens 的 38%。
- 后训练数据用于训练模型的 long-context 能力、效率、控制和安全行为。
- 对于软件问题解决,trajectories 通过启发式分析器过滤,以确保提交完整性并移除不允许的 git 操作或 edit-test 循环。
- 任务分布在至少两种不同的 harnesses 下训练,例如 Stirrup、OpenHands 或 Terminus,以确保泛化。
处理与打包策略
- 作者采用长度感知的最佳适配打包策略,以轮询方式读取和交错源文件,以最小化 padding 开销。
- conversations 既不被截断也不被分割,保留完整上下文并减少幻觉。
- 包内去重约束防止相同的 prompts 在同一 sequence 中共同出现。
- 多语言后训练数据使用端到端翻译流程,处理完整的 JSON objects 而不是逐行翻译以提高质量。
- 对于 chat data,responses 由 Nemotron-GenRM 选择,multi-turn conversations 通过受控 prompting 模拟,以建立对不完美前序 turns 的鲁棒性。
方法
Nemotron 3 Ultra 模型采用 hybrid Mamba-Attention Mixture-of-Experts (MoE) 架构。它具有 5500 亿总参数,每个 token 550 亿活跃参数。该设计集成了 LatentMoE 以实现高效稀疏性,以及原生 Multi-Token Prediction (MTP) 以加速推理。具体的层模式和配置如下图所示。

主干由包含 Mamba-2 layers、Attention layers 和 Latent MoE layers 的重复块组成。这种 hybrid 设计结合了 Mamba 的次二次序列长度扩展和 Attention 的全局上下文建模能力。预训练使用 NVFP4 方案在 20 万亿 text tokens 上进行,模型通过预训练末尾的专用 long-context 阶段扩展以支持 100 万 token 上下文长度。
后训练流程经过大幅重新设计,以增强 agentic 能力和推理。它从通用的 Supervised Fine-tuning (SFT) 阶段开始,随后是统一的 Reinforcement Learning with Verifiable Reward (RLVR) 阶段。然后流程过渡到 Multi-teacher On-Policy Distillation (MOPD) 和 MTP Boosting。整体工作流程如下图所示。
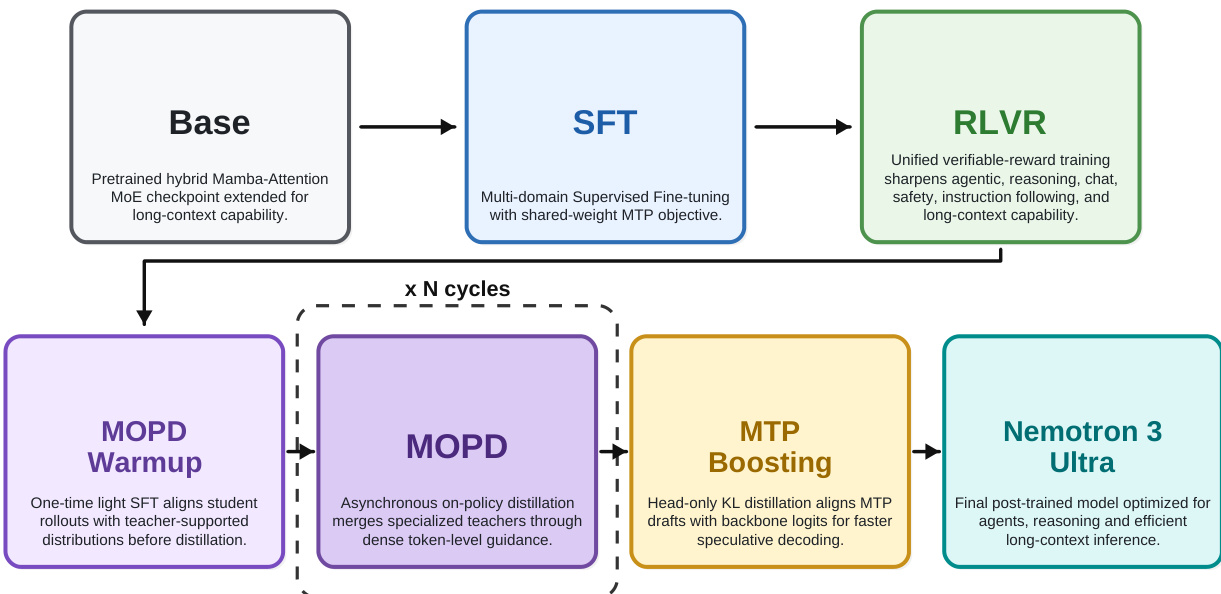
该流程从 Base 模型经过 SFT 和 RLVR,然后进入迭代 MOPD 循环,最后进行 MTP Boosting 以生成 Nemotron 3 Ultra 模型。为了解决混合环境 RLVR 中学习信号的稀释,作者采用 Multi-teacher On-Policy Distillation (MOPD)。此过程涉及训练十多个专用 teacher models,每个针对特定领域进行优化,例如软件工程、办公任务、搜索和 STEM。student model 在这些领域生成 rollouts,并从相应的 teachers 接收密集 reward signals。MOPD 异步执行以最大化效率,rollout generation、teacher scoring 和 student optimization 完全流水线化。该过程在多个迭代循环中发生,允许持续的能力改进。学生在两次迭代中与专用 teachers 的详细交互如下所示。
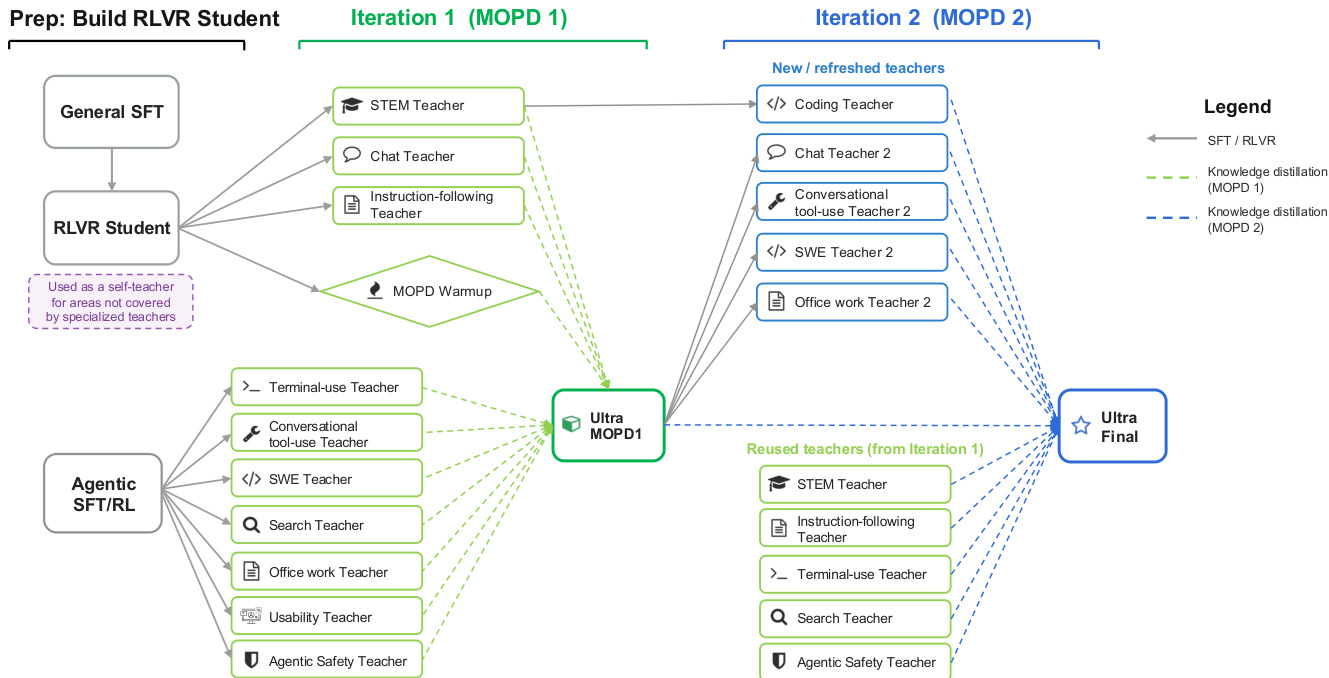
在第一次迭代中,来自通用和 agentic teachers 的信号被蒸馏到 intermediate model 中。在第二次迭代中,新 teachers 从此 intermediate model 初始化,改进被合并以创建最终的 Ultra 模型。MOPD 的目标函数训练 student 以匹配由 student 自身诱导的状态上的 teacher 分布,公式化为最大化负 reverse-KL 目标:
IMOPD(θ)=∑i=1NλiEq∼Di, y∼πθ(⋅∣q)[∑t=1HlogπTi(yt∣st)−logπθ(yt∣st)],
其中 λi 控制 domain i 的采样权重。
最后,模型经过 MTP Boosting,以使 Multi-Token Prediction head 与推理条件下的 backbone 分布对齐。此阶段解决了 train-inference 不匹配,其中 MTP head 基于由先前 MTP 步骤生成的 noisy hidden states 进行条件判断。boosting 目标使用针对 backbone logits 的温度缩放 forward-KL 损失,以确保 drafting head 能够优雅地处理更长的 draft lengths。损失函数定义为:
LMTP(θ)=Nmtp∣A∣T2∑k=1Nmtp∑t∈ADKL(σ(zt+k/T)σ(zt+kmtpk/T)).
这产生了一个能够进行原生 speculative decoding 的模型,具有显著改进的 acceptance lengths。
实验
评估设置利用了全面的基准套件,涵盖 agentic 任务、推理和 long-context 理解,包括 held-out gates 以验证开发指标之外的泛化。训练稳定性实验通过精度调整和学习率退火解决了发散问题,而后训练蒸馏表明,当减轻 teacher-student 分布不匹配时,MOPD 能有效提高 agentic 性能。量化和基础设施研究证实,具有混合精度层的 NVFP4 精度保持了 long-context 能力,且 Multi-Token Prediction 加速了 rollout generation,从而在优化的推理效率下实现了具有竞争力的 agentic 和推理性能。
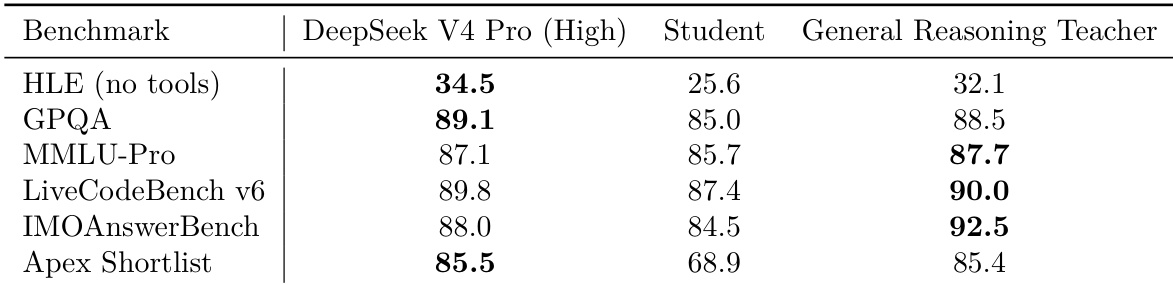
该表比较了 Student 模型、General Reasoning Teacher 和 DeepSeek V4 Pro (High) 模型在各种推理和知识基准上的性能。Student 模型与其他两个模型相比表现持续较差,特别是在复杂推理任务中。General Reasoning Teacher 在特定领域如数学推理和编码方面表现出与 DeepSeek V4 Pro 基线相当或更优的性能。General Reasoning Teacher 在数学推理和编码基准上取得了最高分数,包括 IMOAnswerBench 和 LiveCodeBench v6。DeepSeek V4 Pro (High) 在通用知识和复杂推理评估中领先,例如 HLE 和 GPQA。Student 模型在所有基准上持续记录最低性能,在 Apex Shortlist 和 HLE 类别中显示出巨大差距。
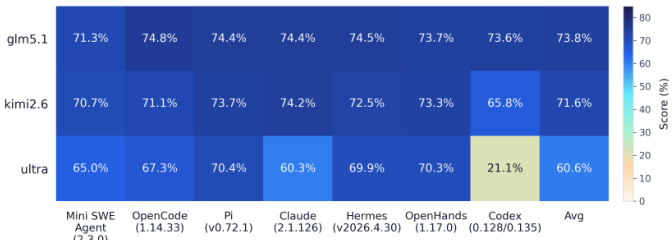
该表展示了 glm5.1、kimi2.6 和 Ultra 在各种基准上的代码评估结果比较。glm5.1 表现出最强的整体性能,平均分最高,而 kimi2.6 紧随其后,结果具有竞争力。Ultra 模型记录了最低的平均性能,并且在 Codex 基准上相对于其他模型表现出显著下降。glm5.1 在评估的代码任务中取得了最高平均分,kimi2.6 在大多数基准上表现强劲,但在 Codex 上下降,Ultra 在整体有效性上落后,并在 Codex 基准上显示出显著的性能差距。
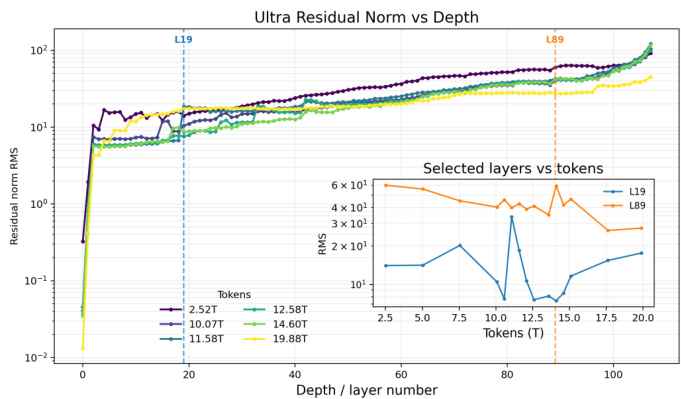
作者分析 residual activation norms 以诊断 Ultra 模型中的训练不稳定性。数据显示,虽然 norms 通常随层深度增加,但早期层在预训练中期表现出激活幅度的显著尖峰,表明信号传播不佳。Residual norms 在整个模型深度中一致增长,跨越多个数量级。早期层在约 11 万亿 token 标记处经历剧烈的 norm 尖峰,与观察到的训练发散一致。后期层保持较高的 residual norms,但与波动的早期层相比显示出不同的稳定性模式。
作者比较了 HuggingFace transformers 和 Megatron-LM 在模型准备工作流程中的效率。结果表明,尽管使用了更大的计算集群,Megatron-LM 实现了显著更快的总周转时间。最显著的性能提升出现在模型加载和校准阶段。Megatron-LM 将总工作流程时间减少到 HuggingFace transformers 所需时间的一小部分。与基线框架相比,Megatron-LM 的模型加载速度大幅更快。校准时间看到最大的相对改进,在 Megatron-LM 中降至最小持续时间。

作者评估了不同量化精度对编码、推理和 long-context 任务上模型性能的影响。结果表明,虽然大多数能力在测试范围内保持稳定,但 long-context 推理在特定的中间精度设置下显著提高,随后达到平台期。此分析支持选择平衡的工作点,在不增加更高精度配置开销的情况下恢复 long-context 性能。大多数基准分数在测试的量化精度范围内保持一致。long-context 推理在特定的精度阈值处显示出明显的性能改进。在选定点之后增加精度在评估的任务上没有产生可测量的增益。
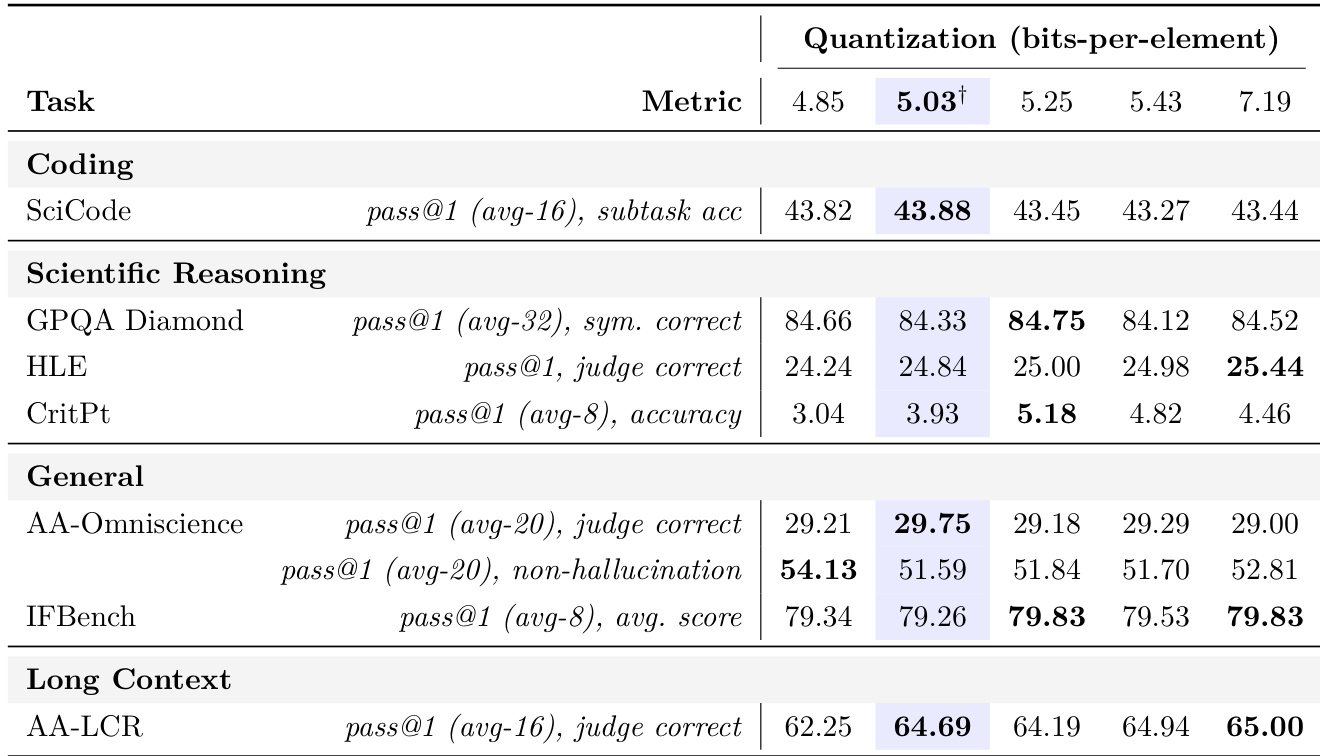
基准比较显示,General Reasoning Teacher 在数学推理和编码方面相对于 DeepSeek V4 Pro 取得了更优的性能,而 Student 和 Ultra 模型在评估任务上持续记录最低分数。对 residual activation norms 的诊断分析揭示了预训练期间早期层不稳定性是训练发散的主要原因,而基础设施比较表明 Megatron-LM 相对于 HuggingFace transformers 大幅减少了工作流程时间。最后,量化研究确定了一个特定的精度阈值,该阈值在不增加开销的情况下提高了 long-context 推理,支持为部署选择平衡的工作点。