Command Palette
Search for a command to run...
MAI-Thinking-1:构建爬山算法
MAI-Thinking-1:构建爬山算法
摘要
人工智能的进步并非由单一模型驱动,而是源于对现有模型状态的持续优化。实现这一目标需要将模型开发视为一个系统级优化问题,其解决方案在于构建一台用于快速迭代的“爬山机”(hill-climbing machine)。我们的流程包括:专注于扩展的预训练模型决策框架,以及一套能够支撑长期对数线性性能提升的强化学习方案与基础设施。通过该流程开发的首个模型是 MAI-Thinking-1。这是一个拥有 35B 活跃参数和 1T 总参数的混合专家(MoE)模型,在科学、技术、工程和数学(STEM)推理及编码任务中表现出色,处于同类规模模型的前沿水平(例如,在 SWE-Bench Pro 上得分为 52.8%,在 AIME 2025 上得分为 97.0%,在 LiveCodeBench v6 上得分为 87.7%)。MAI-Thinking-1 采用从头预训练(from-scratch)的方式构建,仅使用干净的企业级数据进行训练,未借助任何第三方模型的蒸馏技术。在本技术报告中,我们深入剖析了 MAI-Thinking-1 的开发过程。通过分享我们的技术细节与经验教训,我们期望培育一种透明且以科学为导向的方法,以推动人工智能的进一步发展。
一句话总结
MAI-Thinking-1 是一个 35B 活跃参数和 1T 总参数的 MoE 模型,从头开始在清洁的企业级数据上训练,未经第三方模型蒸馏,利用爬山机框架进行系统级优化,结合专注于扩展的预训练和鲁棒的强化学习,以在 STEM 和编码任务上维持对数线性性能提升,在 SWE-Bench Pro 上达到 52.8%,在 AIME 2025 上达到 97.0%,在 LiveCodeBench v6 上达到 87.7%。
核心贡献
- 本文介绍了一种爬山机框架,从数据、基础设施到强化学习配方和评估,优化管道的每个组件。该系统将模型开发视为系统级优化问题,以维持对数线性性能提升。
- MAI-Thinking-1 是该流程产生的第一个模型,利用 35B 活跃/1T 总参数 MoE 架构,从头开始在清洁的企业级数据上训练。基准测试表明该模型在其权重类别中属于最强之列,在 SWE-Bench Pro 上达到 52.8%,在 AIME 2025 上达到 97.0%,在 LiveCodeBench v6 上达到 87.7%。
- 开发了内部安全基准以夯实进展,同时将有用性和安全训练纳入强化学习爬升中,以平衡对用户请求的合规性。在整个开发过程中采用持续的红队测试,以在发布前发现和修复漏洞。
引言
推进人工智能需要系统级优化,而不是依赖孤立的模型突破。先前的方法经常依赖第三方模型的蒸馏,这限制了可控性并阻碍了持续的对数线性性能提升。作者利用爬山机框架将模型开发转化为专注于数据、基础设施和强化学习的实证优化循环。他们推出了 MAI-Thinking-1,一个在清洁企业级数据上从头训练的 35B 活跃参数混合专家模型。这种方法避免了蒸馏捷径,并在复杂的 STEM 推理和软件工程任务上实现了具有竞争力的性能。
数据集
-
数据集组成和来源
- 作者从公开可用和许可的人类生成来源编译了一套高质量、多样化的预训练数据。
- 主要来源包括网页 HTML、网页 PDF、书籍、期刊和公共 GitHub 代码。
- 团队明确避免在预训练中使用语言模型生成的合成数据,并从收集的来源中移除 AI 生成的内容。
- 数据收集遵守 robots.txt 协议,并排除违反安全政策或出现在美国贸易代表办公室臭名昭著市场名单上的来源。
- 常见的机器学习存储库如 huggingface.co 被排除在网页数据之外,以防止污染。
-
每个子集的关键细节
- 网页 HTML: 专有爬虫处理了约 1.2 万亿页,经策略过滤后减少至 7940 亿,经精确去重后减少至 4230 亿。最终语料库包含 734 亿英文和 1165 亿非英文文档。Common Crawl 数据增加了另外 242 亿页。
- 网页 PDF: 团队收集了约 100 亿文档,过滤至 6.2 亿进行处理。这产生了 1.8 万亿英文 token 和 1.85 万亿多语言 token。
- 书籍和期刊: 通过商业协议获取,这些在注释主题和质量之前经过 OCR 伪影处理和去重。
- GitHub 代码: 语料库总计 7.4 万亿 token,组织为文件(1.26T)、提交(4.5T)和拉取请求(1.19T)。
- RL 和 SFT 数据: STEM Mix 数据集包含超过 500 万样本,而竞争性编码包括 160,000 个问题。软件工程环境由 1.02 亿公共拉取请求构建,产生 265,617 个已验证环境。
-
训练使用和混合比例
- 预训练: 最终混合目标为 30 万亿 token 运行。编码数据占大部分,为 16.4 万亿 token,平均略超过 2 个 epoch。
- 数学和 STEM: 约 3000 亿数学 token 平均采样 5.28 次,是所有来源家族中重复率最高的。
- 网页和 PDF: 这些来源平均被看到不到一次(分别为 0.55 倍和 0.53 倍),意味着未耗尽整个语料库。
- 多语言: 该语料库被积极下采样,有 8.1 万亿唯一 token 可用,但仅消耗 0.5 万亿(0.06 倍)。
- 中期训练: 混合偏向 STEM、数学和代码以构建推理基础,分配 35% 给 STEM/数学,55% 给代码,10% 给背景来源。
-
处理和元数据构建
- 提取: 作者使用特定于源的结构化解析器处理 HTML/XML,为一致域手工制作提取器,并基于 LLM 处理进行针对性提取而不添加合成内容。Wikipedia 数据基于原始标记进行训练以保留信息框。
- 去重: 多阶段管道通过哈希移除精确重复项,应用 80% 相似阈值的 MinHash LSH 模糊去重,并通过嵌入使用语义去重。跨数据集去重仅保留最高排名数据集中的实例。
- 过滤: 数据经过策略合规检查、AI 内容检测,并使用属性模型对教育价值和推理内容进行质量分箱。
- 去污染: 使用 80% 相似阈值的通用 20-gram 模糊去重移除公共评估基准。
- 打包: 示例被贪婪地打包成固定长度序列。对于拉取请求,应用前缀压缩以适应 token 预算,超过 256K token 的序列被丢弃。
- 安全和 PII: 整个语料库在训练前使用 PII 风险和安全过滤进行处理。
方法
模型架构与设计
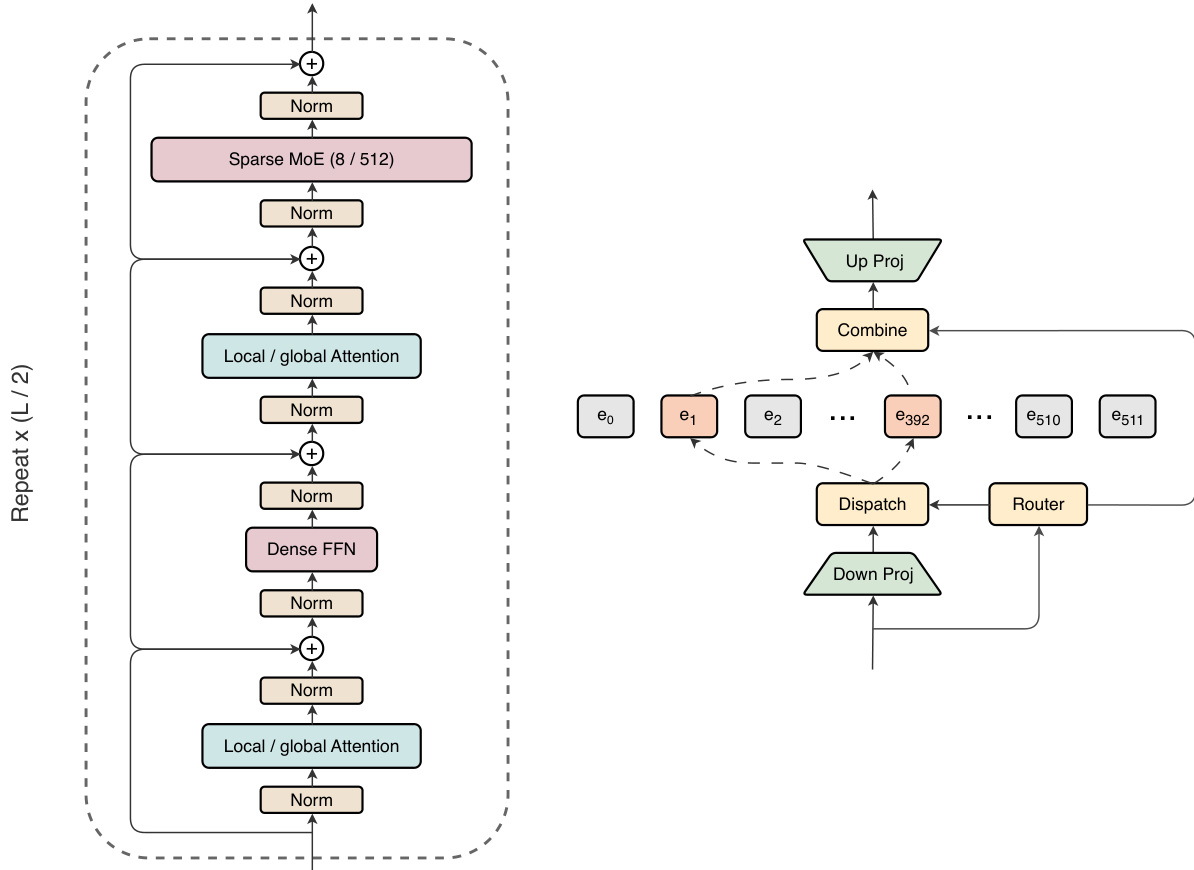
MAI-Thinking-1 的基础模型称为 MAI-Base-1,是一个 35B 活跃和 1T 总参数的稀疏混合专家(MoE)模型。该架构旨在在底层 GPU 基础设施上高效利用规模。它采用仅解码器 Transformer 结构,具有周期性的局部和全局注意力层,以及交替的稠密和 MoE 前馈块。在每一层,RMSNorm 在残差加法之前立即应用于输入和输出。
模型利用周期性注意力设计,将五层局部注意力层与一层全局注意力层配对。这显著降低了训练期间的注意力计算成本和推理期间的 KV 缓存大小。对于前馈层,架构在 MoE 层和稠密前馈网络(FFN)之间交替。这种将高稀疏层与零稀疏层配对的模式,其扩展性与平衡稀疏分配相当,但在挂钟时间上更高效。MoE 层采用 LatentMoE 设计,其中在 all-to-all 分发之前应用共享下投影。路由决策基于原始表示,每个压缩表示被路由到 512 个专家中的 8 个,带有 softmax 门控。
参考框架图以了解 Transformer 主体的整体布局,其中高稀疏 MoE 层与小稠密 FFN 交错,全局注意力与局部注意力交错。该图还详细说明了 MoE 层,显示了每个 token 在压缩潜在空间中激活 512 个专家中的 8 个。
数据准备和语料库构建
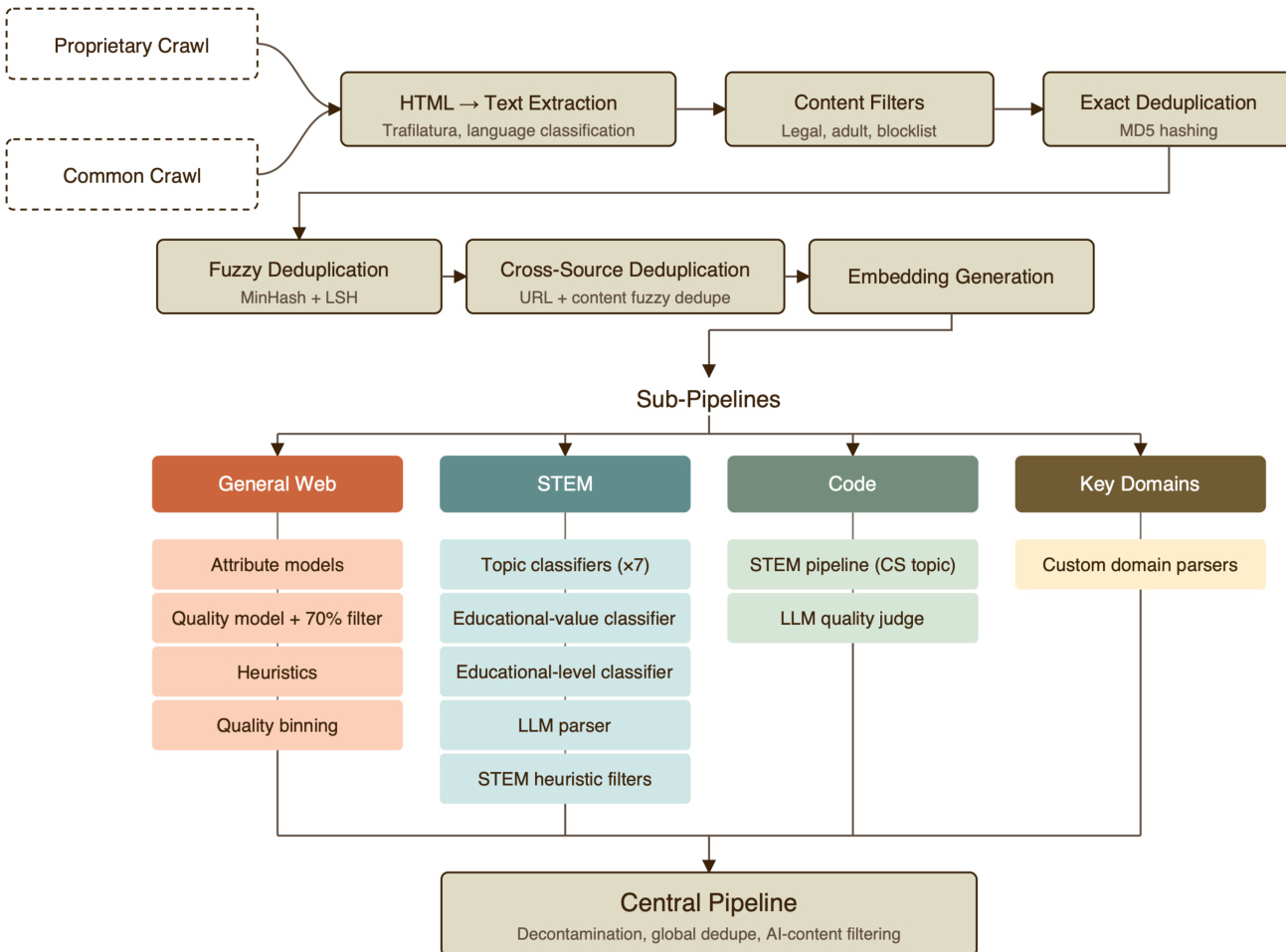
训练语料库完全在内部构建,来自公开可用和获取的数据源,确保模型从人类知识中学习,而不是模仿现有 AI 模型。管道从专有爬虫和 Common Crawl 源的数据开始,经过 HTML 到文本提取和语言分类。应用内容过滤器移除法律、成人和黑名单材料,随后使用 MD5 哈希进行精确去重。
进一步处理涉及使用 MinHash 和 LSH 的模糊去重,以及跨源去重。数据随后分为通用网页、STEM、代码和关键域的子系统。每个子系统采用特定的属性模型、质量分类器和启发式过滤器以确保高质量训练数据。最后,中央管道处理去污染、全局去重和 AI 内容过滤。
参考数据处理工作流以了解从原始爬虫到中央管道的完整管道,说明各种过滤和特定域处理阶段。
强化学习爬升
预训练和中期训练为基础模型提供广泛的预测能力,但强化学习(RL)爬升针对特定行为优化模型,如推理链、工具使用和安全。该过程从中期训练模型开始,并训练三个特定领域的专家模型:一个用于 STEM 和竞争性编码,一个用于 Agent 编码和工具使用,一个用于有用性和安全。这些专家模型随后使用监督微调(SFT)合并为单个模型。最后轻量级 RL 阶段将此合并模型转化为 MAI-Thinking-1。
RL 目标源自带有 token 级策略梯度的组相对策略优化(GRPO)。对于提示 q,展开策略采样一组 G 个响应,每个响应接收标量奖励。训练目标在应用自适应熵控制以维持策略稳定性的同时最大化预期奖励。
参考 RL 爬升概览以了解从中期训练模型到专家教师,最后到合并的 MAI-Thinking-1 模型的进展。

Agent 训练框架
对于 Agent 爬升,模型被训练以解决需要与外部环境交互的任务。这涉及分解用户请求,选择工具或代码操作,观察结果,并在多个步骤中调整计划。训练信号结合可验证奖励与 AI 反馈奖励,用于任务解释和轨迹质量等方面。
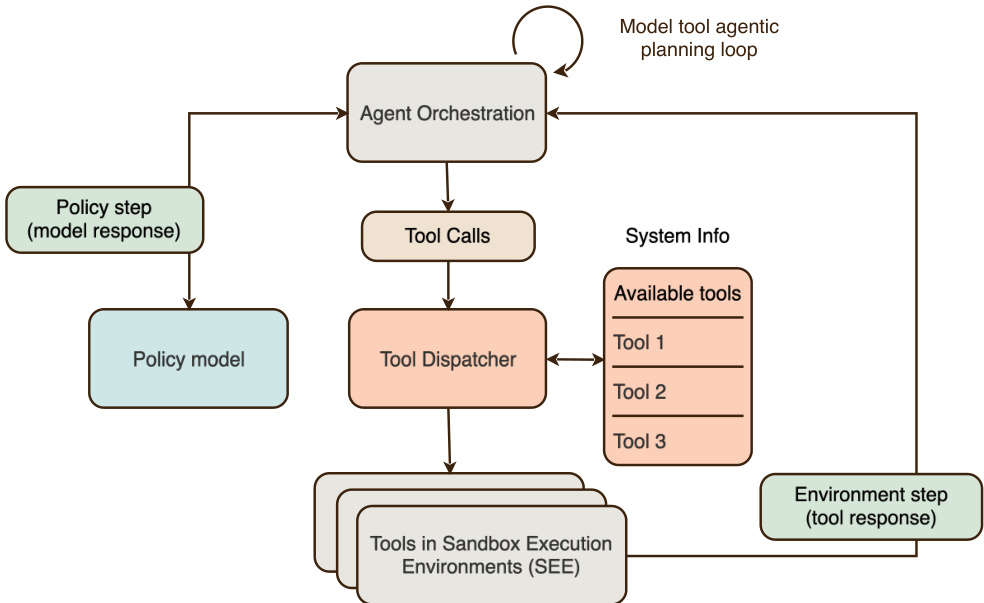
Agent 多步 RL 使用与单步推理相同的核心目标,但将展开扩展到策略步骤和环境步骤的轨迹。编排工具遵循 ReAct 风格循环,解析模型的推理,将工具调用分派到沙箱执行环境(SEE),并将返回的观察结果附加到上下文中。当模型不发出工具调用或超出预算限制时,循环终止。
参考 Agent 循环图以了解 Agent 编排、工具分派器和沙箱执行环境之间的交互,突出显示模型工具 Agent 规划循环。
RL 基础设施和系统设计
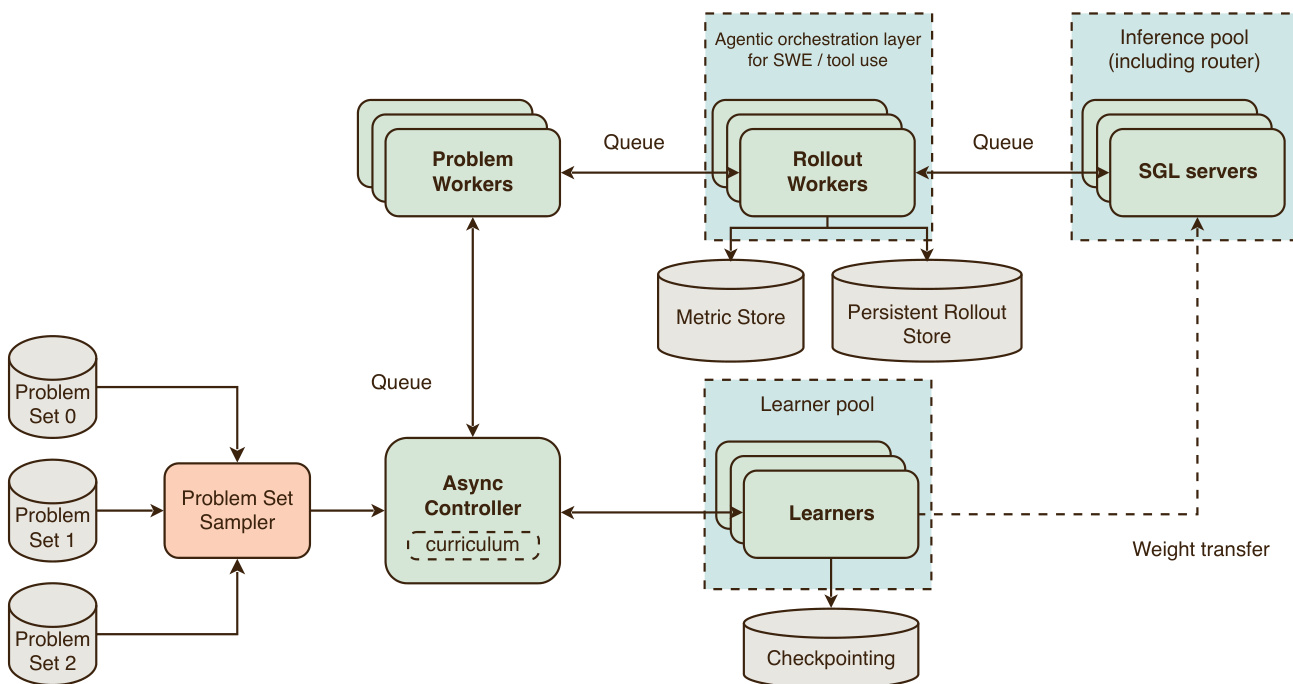
强化学习爬升依赖于 Rocket,这是一个用于大规模异步分布式强化学习的内部框架。Rocket 使用 YOLO 框架作为学习者,使用 SGLang 进行模型推理。系统围绕单个控制器、问题池和展开工作器以及产生模型生成的路由器和推理服务器组织。
控制器加载 RL 任务并将其发送到问题工作器,后者生成展开并计算归一化优势。展开工作器处理模型响应和工具交互的实际生成。推理性能至关重要,系统采用优化措施,如多轮工作负载的前缀缓存和长生成的专家并行。该框架通过副本、路由器和作业层面的纵深防御措施确保稳定性。
参考 Rocket 架构图以了解系统组件和数据流,显示控制器、问题工作器、展开工作器和推理服务器交互。
实验
实验设置采用扩展梯度和效率增益指标,以验证不同模型规模下的架构和数据设计选择。关键发现表明,数据混合性能排名并不总是对规模不变,而对推理轨迹的定性分析显示,更强的模型采用严格的验证策略,而较弱变体则表现出猜测行为。最终,最终模型在基准测试和人类偏好分数方面与同期模型具有竞争力,并得到了源自广泛红队测试和迭代训练稳定性改进的鲁棒安全缓解措施的支持。
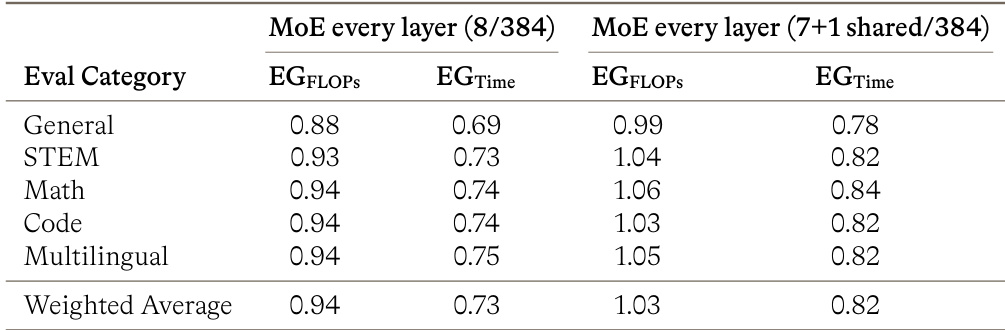
作者采用分阶段训练策略,从高容量预训练阶段过渡到专注于长上下文能力的专用中期训练阶段。初始阶段消耗大部分 token 预算和 GPU 资源,以在标准序列长度下构建基础知识。后续阶段优先考虑显著扩展上下文窗口,同时在最终阶段使用减少的 token 计数和较少的计算资源运行。预训练阶段与后续阶段相比,利用最大的 token 预算和 GPU 集群规模。上下文长度从初始阶段到最终中期训练阶段大幅增加。最终训练阶段以显著更少的 GPU 数量运行,同时针对最长的上下文窗口。
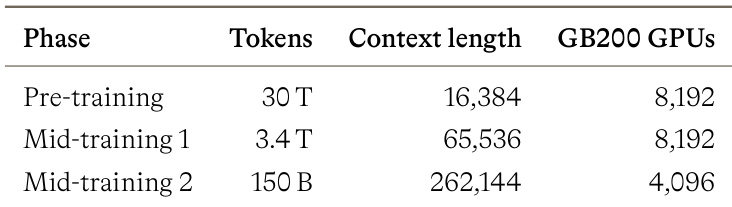
作者在 STEM 和 Agent 编码基准测试中评估 MAI-Thinking-1 与各种前沿模型,以评估其竞争地位。结果表明,虽然该模型在各类别中表现持续强劲,但在大多数领域通常落后于顶级同期模型,并未领先该领域。MAI-Thinking-1 在 AIME 2025 数学竞赛基准测试中优于 Sonnet 4.6。该模型在 SWE-Bench Pro 上的表现与 Opus 4.6 相当。Agent 编码基准测试如 Terminal-Bench 2.0 显示相对于领先模型如 Opus 4.6 和 GPT 5.4 性能较低。
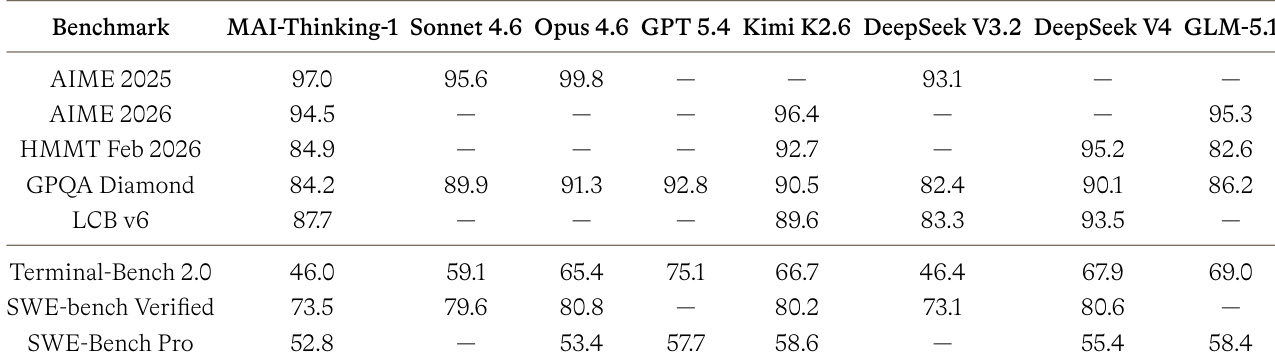
作者进行了人类并排评估,将其模型与 Sonnet 4.6 和 Opus 4.6 在多个质量维度上进行比较。结果表明,其模型对 Sonnet 4.6 有轻微的整体偏好,而 Opus 4.6 对其模型有轻微偏好。与两个竞争对手相比,该模型在简洁性、相关性、风格和语气方面表现出更优越的性能,而在指令遵循、事实性和完整性方面显示出轻微缺陷。整体偏好对 Sonnet 4.6 略为正,但对 Opus 4.6 为负。简洁性、相关性、风格和语气得分高于两个竞争对手模型。指令遵循、事实性和完整性指标显示相对于竞争对手较低或相当的性能。
该表说明了数据混合配置,其中 STEM 和编码内容在训练中被严重加权。通用有用性和安全数据占样本的很大一部分,但对整体 token 预算贡献很小,表明相对于 STEM 内容数据序列较短。STEM 和编码数据主导 token 量,获得最高分配。通用有用性和安全样本常见,但占总 token 的极小部分。Agent 能力数据在两个指标中代表训练混合的一小部分。

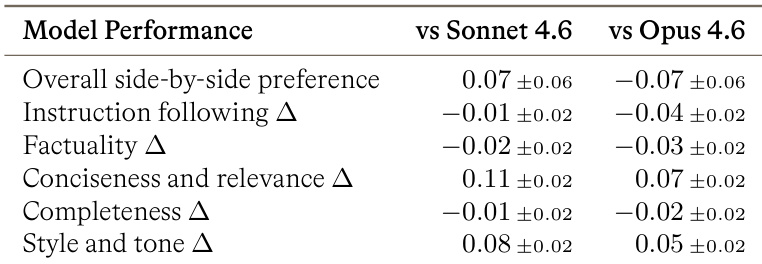
作者评估了两个 MoE 每层架构变体与交错基线布局,以评估不同评估类别下的效率增益。虽然包含共享专家的变体在 FLOPs 效率上显示出轻微改进,但两个 MoE 每层配置在训练时间效率上均低于基线。这表明在考虑硬件利用率和挂钟成本时,交错布局提供了更好的整体权衡。具有共享专家的 MoE 每层变体通常实现高于基线的 FLOPs 效率增益,而标准变体保持在基线水平以下或附近。两个 MoE 每层配置在训练时间效率上均显著低于交错基线布局。交错布局被确定为首选架构,因为其挂钟效率优越,尽管 FLOPs 存在权衡。
作者采用分阶段训练策略,从高容量预训练过渡到专用长上下文阶段,利用主要由 STEM 和编码 token 主导的数据混合。比较基准和人类评估显示在风格和推理方面表现强劲,但表明该模型在指令遵循和事实性方面通常落后于顶级竞争对手。架构消融研究进一步验证,与 MoE 每层变体相比,交错布局提供优越的挂钟效率。