Command Palette
Search for a command to run...
DeepSeek-V4:迈向高效的 Million-Token 上下文智能
DeepSeek-V4:迈向高效的 Million-Token 上下文智能
一键部署 DeepSeek-V4-Flash
摘要
我们在此发布 DeepSeek-V4 系列的预览版本,其中包括两款强大的 Mixture-of-Experts (MoE) 语言模型:拥有 1.6T 参数(激活参数为 49B)的 DeepSeek-V4-Pro,以及拥有 284B 参数(激活参数为 13B)的 DeepSeek-V4-Flash。两款模型均支持一百万 tokens 的上下文长度。DeepSeek-V4 系列在架构与优化方面进行了多项关键升级:(1) 采用了结合了压缩稀疏注意力(Compressed Sparse Attention, CSA)与重度压缩注意力(Heavily Compressed Attention, HCA)的混合注意力架构,以提升长上下文处理效率;(2) 引入了流形约束超连接(Manifold-Constrained Hyper-Connections, mHC),旨在增强传统的残差连接(residual connections);(3) 使用了 Muon 优化器,以实现更快的收敛速度和更高的训练稳定性。我们使用超过 32T 多样化且高质量的 tokens 对这两款模型进行了预训练,随后通过全面的 post-training pipeline 进一步释放并增强了它们的各项能力。其中,DeepSeek-V4-Pro-Max 作为 DeepSeek-V4-Pro 的最大推理强度模式(maximum reasoning effort mode),重新定义了开源模型的 state-of-the-art 水平,在核心任务中的表现均超越了其前代模型。同时,DeepSeek-V4 系列在长上下文场景下表现出极高的效率。在一百万 tokens 的上下文设置下,与 DeepSeek-V3.2 相比,DeepSeek-V4-Pro 仅需 27% 的单 token 推理 FLOPs 以及 10% 的 KV cache。这使我们能够常规化地支持百万级别的上下文长度,从而使长程任务(long-horizon tasks)以及进一步的 test-time scaling 变得更加可行。模型 checkpoint 已发布于:https://huggingface.co/collections/deepseek-ai/deepseek-v4。
一句话总结
DeepSeek-V4 系列引入了两个 Mixture-of-Experts 模型:DeepSeek-V4-Pro 拥有 1.6T 参数(49B 激活)和 DeepSeek-V4-Flash 拥有 284B 参数(13B 激活)。它们通过结合 Compressed Sparse Attention 和 Heavily Compressed Attention 的 hybrid attention architecture,以及 Manifold-Constrained Hyper-Connections 和 Muon optimizer,支持 one million tokens。DeepSeek-V4-Pro-Max 重新定义了 open models 的 state-of-the-art,而 DeepSeek-V4-Pro 相比 DeepSeek-V3.2 仅需 27% 的 single-token inference FLOPs 和 10% 的 KV cache。
核心贡献
- DeepSeek-V4 系列引入了两个支持 one million tokens 上下文长度的 Mixture-of-Experts 语言模型。DeepSeek-V4-Pro 拥有 1.6T 参数,其中 49B 激活,而 DeepSeek-V4-Flash 拥有 284B 参数,其中 13B 激活。
- 架构升级包括结合 Compressed Sparse Attention 和 Heavily Compressed Attention 的 hybrid attention architecture,以提高 long-context 效率。该系列还引入了 Manifold-Constrained Hyper-Connections 以增强 residual connections,以及 Muon optimizer 以实现更快的收敛和更大的训练稳定性。
- DeepSeek-V4-Pro-Max 通过在核心任务上超越前身,重新定义了 open models 的 state-of-the-art。在 one-million-token 上下文设置中,与 DeepSeek-V3.2 相比,DeepSeek-V4-Pro 仅需 27% 的 single-token inference FLOPs 和 10% 的 KV cache。
引言
处理 ultra-long contexts 对于实现下一代大型语言模型的 test-time scaling 和复杂 agentic tasks 至关重要。然而,现有解决方案面临效率障碍,阻碍了 open-source models 匹配专有系统的推理能力。为此,作者引入了 DeepSeek-V4 系列,该系列结合了 hybrid attention architecture 与广泛的基础设施优化。这种方法实现了对 million-token contexts 的高效原生支持,并为 open models 在推理性能和成本效率方面确立了新标准。
数据集
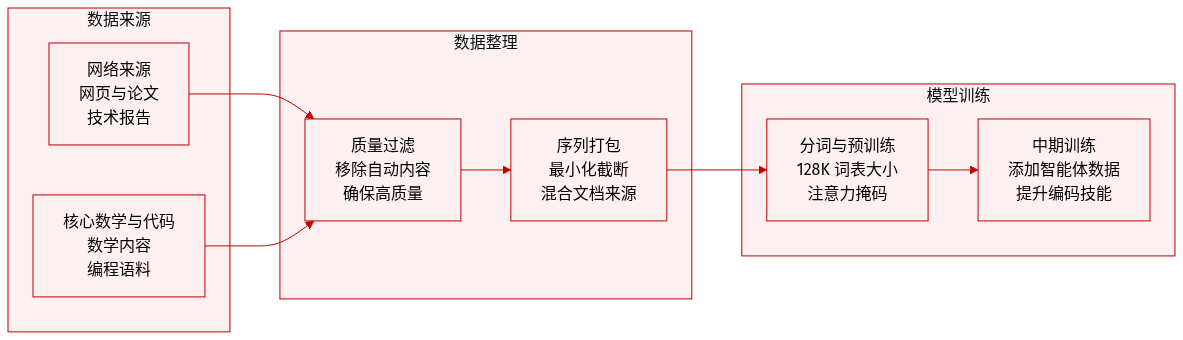
- 数据集组成与来源
- 作者基于 DeepSeek-V3 的 pre-training data 构建了一个超过 32T tokens 的多样化语料库。
- 主要来源包括网页、数学内容、代码、多语言文本以及科学论文和技术报告等长文档。
- 子集详情与过滤规则
- 网页来源数据经过过滤,移除批量自动生成和模板化内容,以减轻模型坍塌风险。
- 数学和编程语料库作为核心组件,在 mid-training 阶段添加了 agentic data 以增强编码能力。
- 多语言语料库得到扩展,以改进对各种文化中长尾知识的捕捉。
- 长文档数据策展优先考虑反映 DeepSeek-V4 系列独特学术价值的材料。
- 训练使用与处理
- 预处理主要遵循 DeepSeek-V3 策略,固定 vocabulary size 为 128K。
- tokenizer 引入了用于上下文构建的特殊 tokens,同时保留了 token-splitting 和 Fill-in-Middle (FIM) 策略。
- 来自不同来源的文档被打包成适当的序列,以最小化样本截断。
- 预训练期间采用了样本级 attention masking,这与上一版本不同。
方法
模型架构与训练方法
DeepSeek-V4 系列保留了 Transformer architecture 和 Multi-Token Prediction (MTP) 策略,同时引入了关键升级以增强 long-context 效率和训练稳定性。整体框架结合了 hybrid attention mechanism 和 Manifold-Constrained Hyper-Connections (mHC) 以及 DeepSeekMoE 结构。完整的架构展示了从 input tokens 经过 embedding、Transformer blocks 到 prediction heads 的流程,如下图所示。
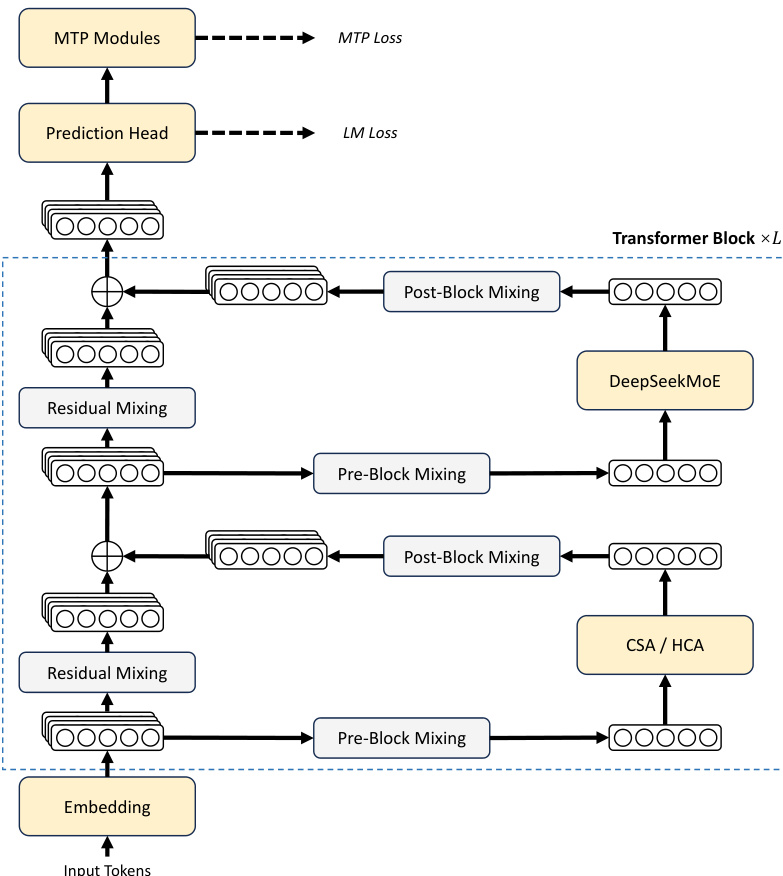
为了加强跨层的信号传播,作者引入了 Manifold-Constrained Hyper-Connections (mHC) 以升级传统的 residual connections。核心思想涉及将 residual mapping matrix 约束在 doubly stochastic matrices 的 manifold 上。这确保了 mapping matrix 的 spectral norm 被限制在 1 以内,从而在不影响内层设计的情况下,增加了前向传播和 backpropagation 期间的数值稳定性。
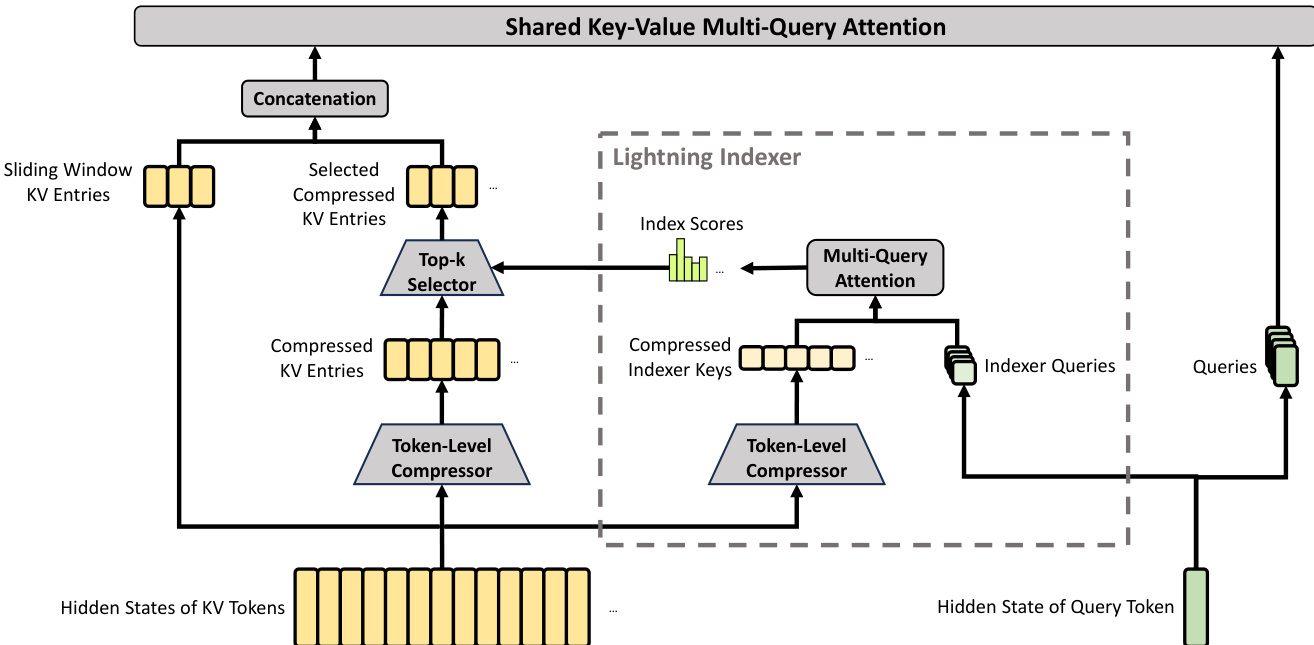
处理 ultra-long contexts 的关键组件是 hybrid attention architecture,它结合了 Compressed Sparse Attention (CSA) 和 Heavily Compressed Attention (HCA)。CSA 首先将每 m 个 tokens 的 Key-Value (KV) cache 压缩为一个条目,然后应用 sparse selection strategy。Lightning Indexer 计算 index scores 以选择 top-k 压缩 KV entries 用于核心 attention mechanism。CSA 的详细架构,包括 token-level compressor 和 selection process,如下图所示。
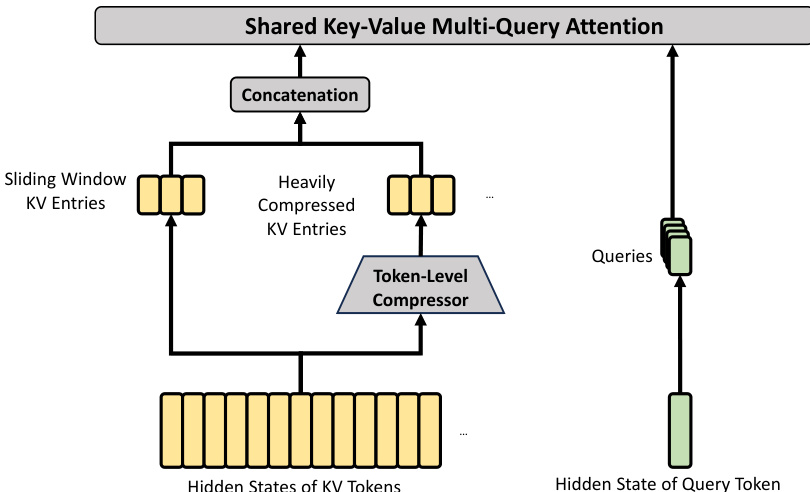
HCA 旨在通过每 m′ 个 tokens 的 KV cache 整合为单个条目来实现极端压缩,其中 m′ 显著大于 m。与 CSA 不同,HCA 不采用 sparse attention,而是在 heavily compressed representation 上执行 dense attention。该设计进一步降低了计算成本和 KV cache 大小。HCA 的核心架构利用 token-level compressor 而不使用 indexer,如下图所示。
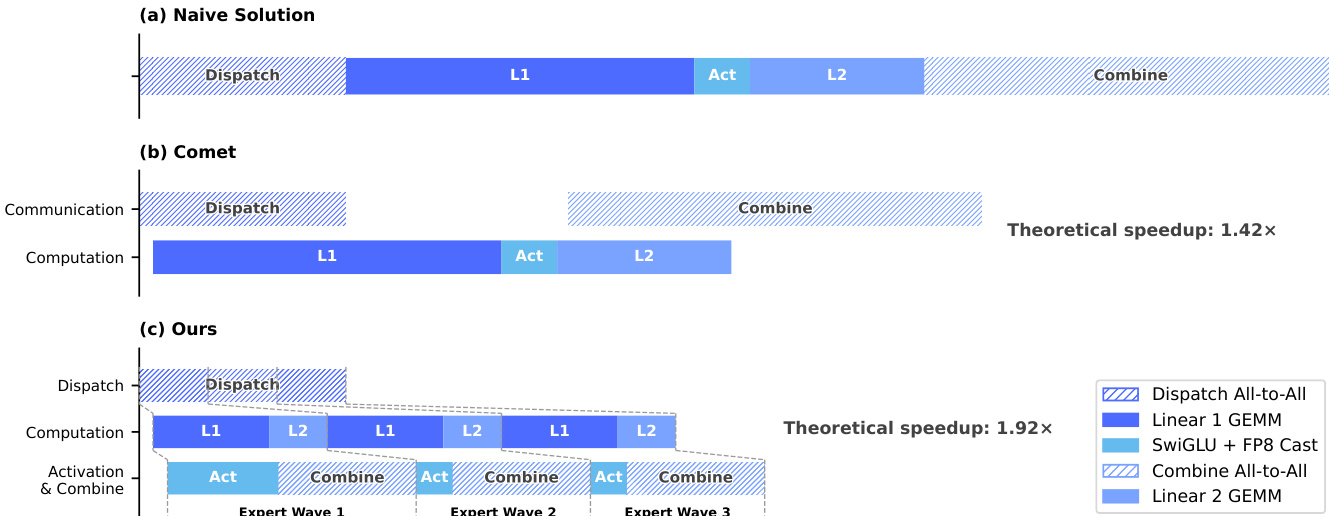
对于优化,模型采用 Muon optimizer 以实现更快的收敛和更大的训练稳定性。为了支持 Mixture-of-Experts (MoE) 组件的高效训练和 inference,系统实现了细粒度的 Expert Parallelism 方案。该方法通过将 experts 分成 waves,将 communication 和 computation 融合到单个 pipelined kernel 中。如下面的 timing diagram 所示,这允许一个 wave 的计算继续进行,同时下一个 wave 的 communication 发生,有效地隐藏了 communication latency。
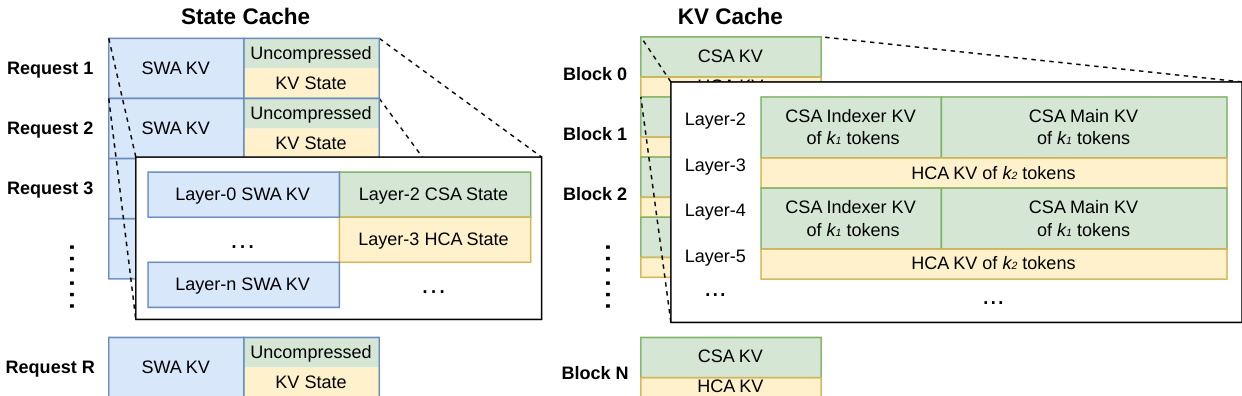
hybrid attention mechanism 需要 heterogeneous KV cache structure 来管理不同的 compression ratios 和 attention policies。系统维护用于 sliding window attention 和 uncompressed tail tokens 的 State Cache,以及用于 compressed entries 的经典 KV Cache。如下面的布局所示,该布局组织 cache blocks 以适应不同请求中 CSA 和 HCA layers 的 varying requirements。
预训练后,模型经历涉及 specialist training 和 On-Policy Distillation 的 post-training pipeline。训练支持多种 reasoning effort modes,允许模型根据任务复杂度调整其计算深度。这些 reasoning modes 的比较,包括它们的 context windows 和 length penalties,如下表所示。
对于 maximum reasoning effort,特定的 instructions 被注入 system prompt 以指导模型在 "Think Max" 模式下的行为。用于此模式的 instruction template 如下图所示。
实验
评估框架在 knowledge、reasoning、coding 和 long-context benchmarks 上评估 DeepSeek-V4 变体与领先的 open 和 proprietary models,并辅以针对 real-world applications 的内部指标。DeepSeek-V4-Pro-Max 为 open-source models 确立了新的领先标准,显著缩小了与 frontier closed systems 的性能差距,同时在 1 million token context retention 和 Agentic Search 方面展示了强大的能力。虽然高效的 Flash 变体优于前几代,但 Pro 系列在复杂 enterprise tasks 和 coding 方面表现出色,尽管在 formatting precision 和 instruction following 方面仍略逊于顶级竞争对手。
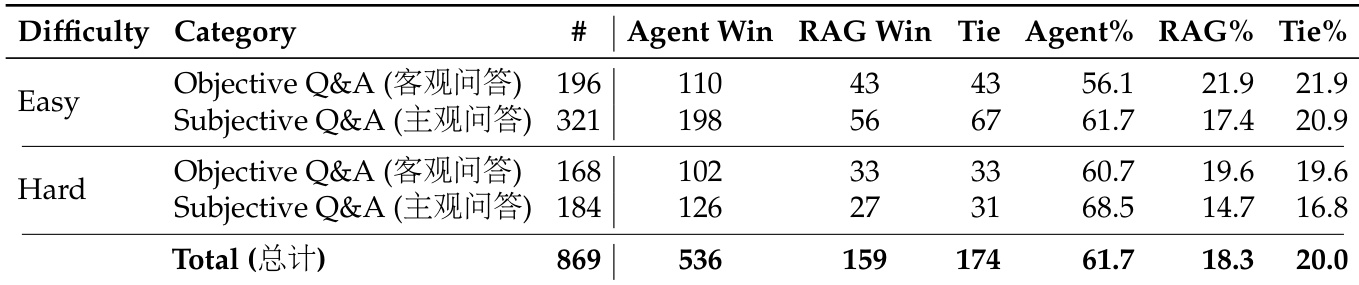
该表展示了 Agentic Search 和 Retrieval-Augmented Search (RAG) 在不同难度级别和问题类别之间的 pairwise comparison。结果表明,Agentic Search 始终优于 RAG,在 easy 和 hard 场景中均实现了显著更高的 win rate。这种性能优势在 objective 和 subjective question types 中均观察到,证实了 agentic approach 的有效性。Agentic Search 在所有评估类别中均对 RAG 实现了主导 win rate。对于 easy 和 hard 难度级别,性能差距保持一致。Agentic Search 在 hard subjective questions 方面相比 RAG 显示出特别的优势。
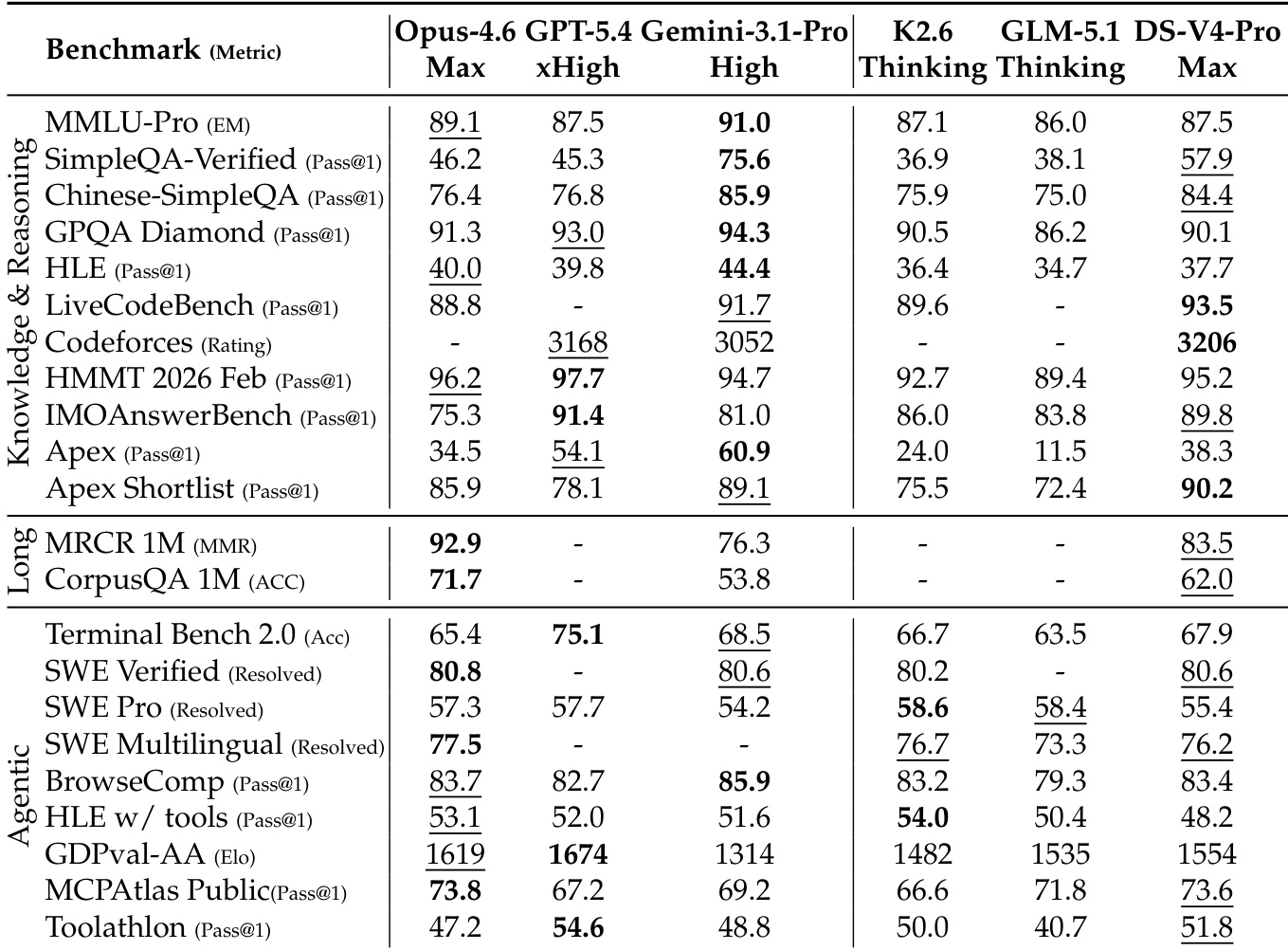
提供的数据在 knowledge、reasoning、long-context 和 agentic benchmarks 上比较了 DeepSeek-V4-Pro 与领先的 proprietary 和 open-source models。DeepSeek-V4-Pro 始终优于其他 open-source models,通常整体排名第二或第三,仅次于 Opus-4.6 和 GPT-5.4 等顶级 closed models。虽然它在 long-context retrieval 和特定 coding evaluations 方面表现出显著优势,但在复杂 mathematical reasoning 和某些 agentic tasks 方面仍落后于最强的 proprietary models。DeepSeek-V4-Pro 在 SimpleQA 等 knowledge benchmarks 上显著优于 open-source competitors,但仍落后于 Gemini-3.1-Pro 等 proprietary leaders。与 Gemini-3.1-Pro 相比,该模型实现了 superior long-context retrieval performance,尽管 Opus-4.6 保持领先。在 agentic 和 coding evaluations 中,DeepSeek-V4-Pro 匹配或超过其他 open models,但通常落后于 performance 最高的 closed models。
作者展示了 DeepSeek-V4-Pro-Max 与几个 Claude model variants 在测量 pass rates 的 benchmark 上的比较。数据显示,DeepSeek-V4-Pro-Max 显著优于 Sonnet 4.5 模型,并且表现水平与 base Opus 4.5 模型相当。尽管性能强劲,但 DeepSeek 模型仍不及 Opus 系列的 specialized Thinking variants,后者在该评估中实现了最高的 success rates。DeepSeek-V4-Pro-Max 在此 benchmark 上对 Sonnet 4.5 模型显示出明显优势。性能与标准 Opus 4.5 配置具有竞争力,但低于启用 Thinking 的 Opus 变体。Opus 4.6 Thinking 实现了最高的 pass rate,超过了 DeepSeek 模型和其他 Claude variants。

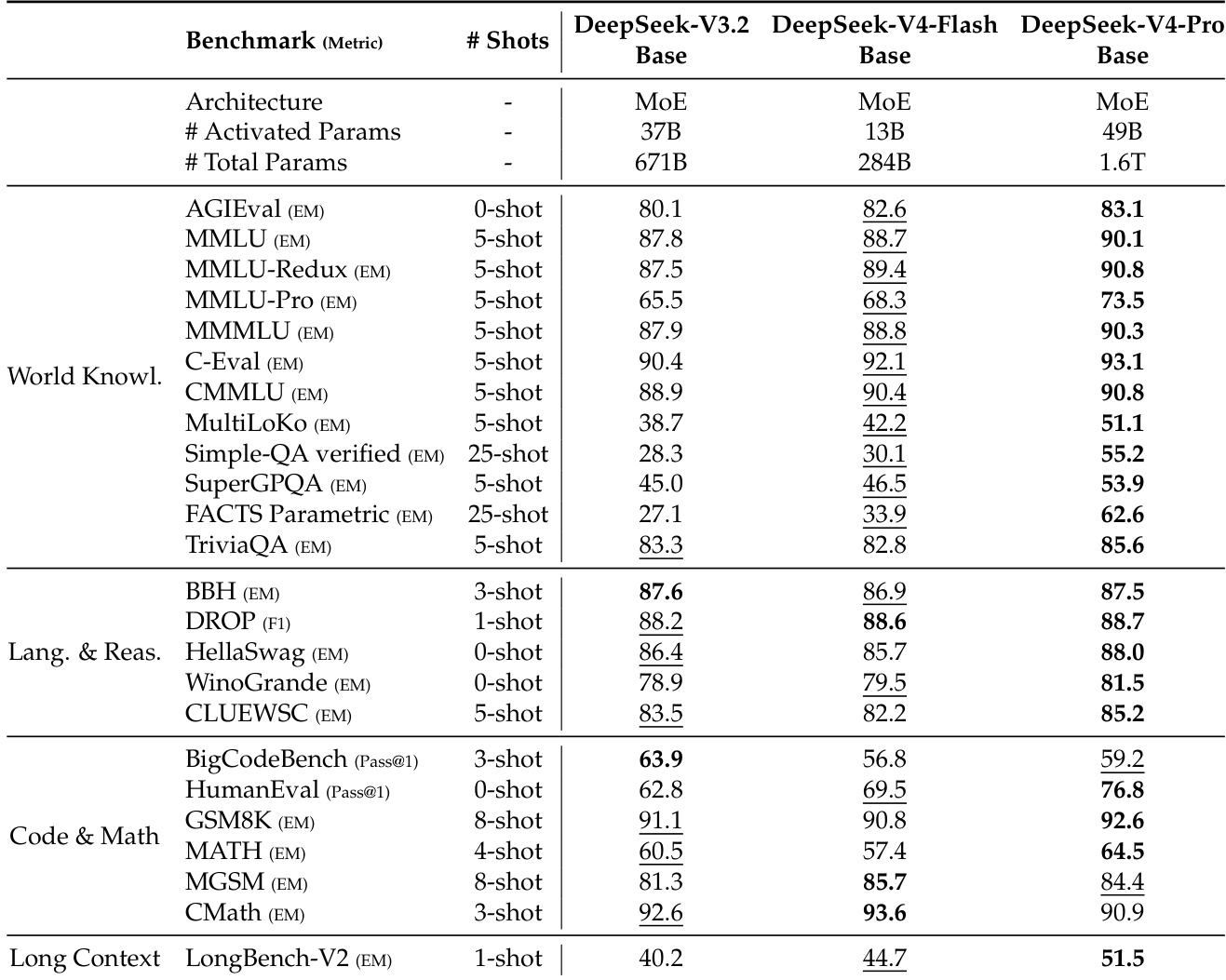
该表比较了 DeepSeek-V3.2、DeepSeek-V4-Flash 和 DeepSeek-V4-Pro base models 在 knowledge、reasoning、coding 和 long-context benchmarks 上的性能。DeepSeek-V4-Pro-Base 展示了决定性的能力飞跃,在大多数类别中取得了最高分数,并确立了自己作为该系列中最强 foundation model 的地位。同时,DeepSeek-V4-Flash-Base 展示了显著的 efficiency gains,尽管 activated parameters 较少,但在许多 evaluations 中仍优于更大的 DeepSeek-V3.2-Base。DeepSeek-V4-Pro-Base 在几乎所有评估维度上都取得了 top performance,在 world knowledge 和 long-context processing 方面显示出决定性的改进。DeepSeek-V4-Flash-Base 通过以显著更少的 parameters 在广泛 benchmarks 上超越更大的 DeepSeek-V3.2-Base 证明了其高效性。虽然 Pro 变体整体领先,但特定的 coding 和 math tasks 揭示了 V3.2 和 Flash 模型保持 competitive 或 superior scores 的实例。
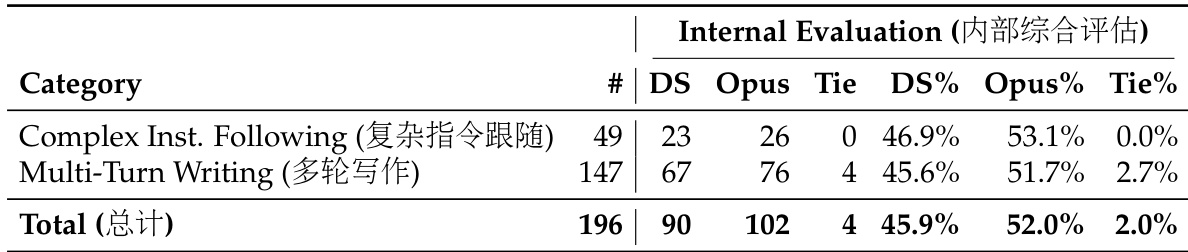
作者进行了内部评估,比较 DeepSeek-V4-Pro 与 Claude Opus 4.5 在涉及 complex instruction following 和 multi-turn writing 的任务上的表现。结果表明,虽然 DeepSeek-V4-Pro 表现具有竞争力,但 Opus 4.5 在这些特定的 challenging categories 中保持了 consistent performance advantage。这表明尽管具备强大的 general capabilities,该模型在处理 high-complexity constraints 和 extended interactions 方面仍落后于领先的 proprietary counterpart。Opus 4.5 在 complex instruction following 和 multi-turn writing benchmarks 中实现了比 DeepSeek-V4-Pro 更高的 win rate。DeepSeek-V4-Pro 通过在近一半的评估实例中战胜领先模型展示了强大的竞争力。评估突出了 DeepSeek-V4-Pro 在 high-complexity 和 multi-turn scenarios 中落后于 Opus 4.5 的特定 performance gap。
评估比较了 Agentic Search 与 Retrieval-Augmented Search,并在 knowledge、reasoning 和 coding tasks 上 benchmark 了 DeepSeek model variants 与领先的 proprietary 和 open-source competitors。结果表明,Agentic Search 始终优于 RAG,而 DeepSeek-V4-Pro 变体在 efficiency 和 long-context capabilities 方面优于 open-source peers,但在复杂 mathematical reasoning 和 multi-turn writing 方面通常落后于 top-tier closed models。在 DeepSeek 系列内部,Pro-Base 变体确立了最强的 foundation,尽管竞争对手的 specialized Thinking models 在 complex instruction following 方面保持优势。