Command Palette
Search for a command to run...
DSpark:基于置信度调度与半自回归生成的推测解码
DSpark:基于置信度调度与半自回归生成的推测解码
摘要
投机解码(Speculative Decoding)通过将草稿生成与目标验证解耦,从而加速大语言模型(LLM)的推理过程。尽管近期提出的并行草稿生成器能够在单次前向传播中高效地提议长序列 token,但由于缺乏 token 间的依赖关系,其接受率(acceptance rate)会迅速衰减。此外,对所有扩展块进行无差别验证会浪费关键的批次容量(batch capacity)在具有高拒绝风险的 token 上,严重降低了高并发服务系统吞吐量。我们推出了 DSpark,这是一种投机解码框架,将高吞吐量的并行生成与自适应、感知负载的验证统一起来。为了保持草稿质量,DSpark 采用了一种半自回归(semi-autoregressive)架构——将并行主干网络与轻量级序列模块耦合——以引入块内依赖建模并缓解后缀衰减(suffix decay)。为了优化系统效率,DSpark 采用置信度调度验证(confidence-scheduled verification),根据估计的前缀存活概率和特定引擎的吞吐量配置,动态调整每个请求的验证长度。在跨越多个领域的离线 benchmark 测试中,DSpark 在接受长度方面显著优于最先进的自回归和并行草稿生成器。当部署在 DeepSeek-V4 服务系统中并承载真实用户流量时,DSpark 成功减少了验证资源的浪费。
一句话总结
DeepSeek 研究者提出 DSpark,一种推测解码框架,该框架将半自回归草稿架构(将并行主干与轻量级序列模块结合,引入块内依赖以缓解后缀衰减)与置信度调度验证相结合,根据估计的前缀存活概率和引擎特定的吞吐量曲线动态调整每个请求的验证长度,从而减少验证浪费并提升 DeepSeek-V4 在线部署中的吞吐量。
核心贡献
- DSpark 使用一种半自回归草稿器,将并行主干与轻量级序列 RNN 头部结合,注入块内依赖以缓解后缀衰减,同时保持精确的逐 token softmax 概率以用于拒绝采样。
- 该框架引入置信度调度验证,利用估计的前缀存活概率和引擎级吞吐量曲线,为每个请求动态选择验证长度,以消除在高风险 token 上的批次容量浪费。
- 在各种离线基准测试中,DSpark 相比最先进的自回归和并行草稿器显著提高了接受长度,并在 DeepSeek-V4 在线服务部署中,面对真实用户流量缓解了验证浪费。
引言
自回归解码强制大型语言模型每次前向传播只生成一个 token,导致推理延迟与输出长度线性增长。推测解码通过让快速草稿模型一次提出多个 token,然后目标模型并行验证以保持精确的输出分布,从而绕过这一瓶颈。然而,实际加速效果有限,因为草稿模型难以同时兼顾高接受率和低草稿成本:轻量级自回归草稿器重新引入序列开销,而并行生成方案(非自回归 Transformer、基于 CTC 的模型)难以为标准的拒绝采样接受规则提供逐 token 概率,将其限制在贪心验证。作者提出 DSpark,引入一种半自回归草稿器,首先从共享表示并行预测一个 token 块,然后应用局部序列修正头部以产生精确的逐 token 分布,完全兼容推测解码的验证步骤。结合一个基于置信度的调度器,动态调整每个周期的草稿 token 数量,DSpark 改善了草稿速度-质量平衡和整体解码吞吐量。
方法
作者提出 DSpark,一个旨在统一高吞吐量并行生成与自适应、负载感知验证的推测解码框架。为解决现有草稿器的局限性,DSpark 集成两个互补组件:一个半自回归生成模块和一个置信度调度验证机制。
如下图所示:
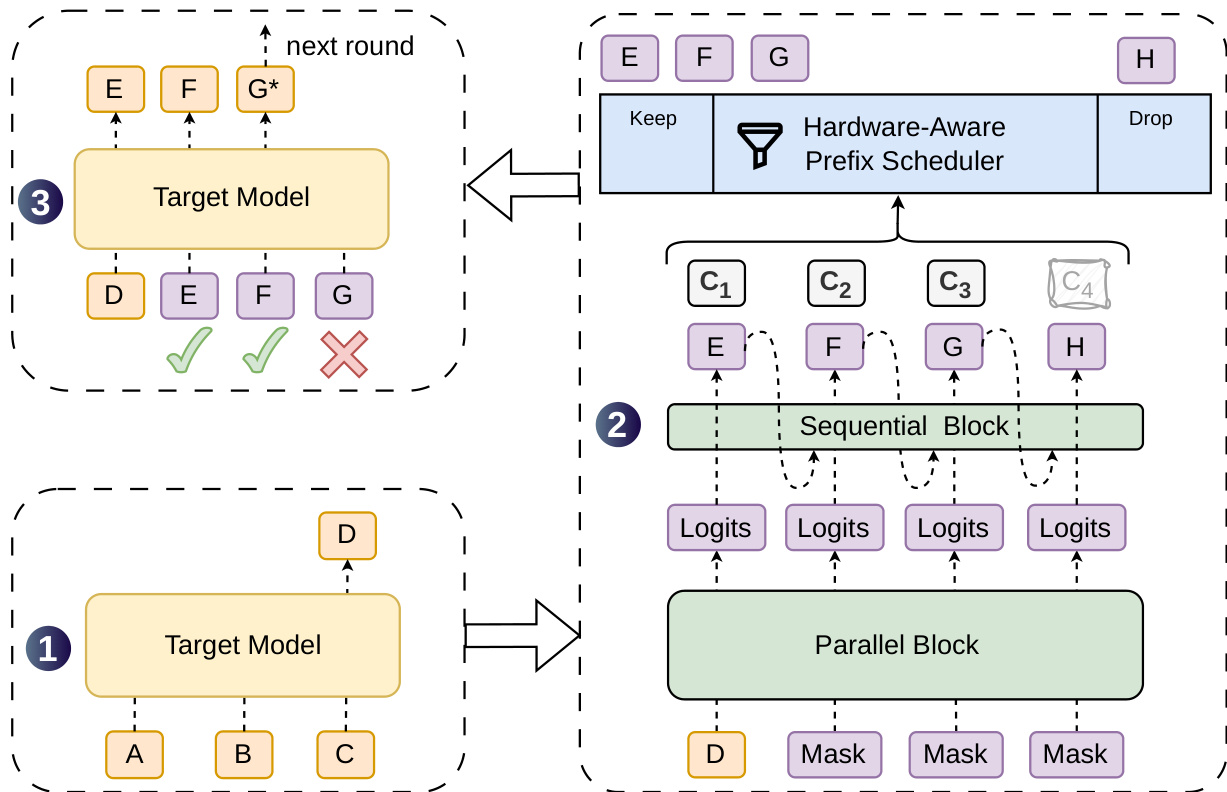
半自回归生成模块将草稿生成分为两个阶段,以在保持草稿质量的同时维持低延迟。首先,并行主干在单次前向传播中处理整个块,产生隐藏状态和基础 logits。这使草稿时间几乎独立于块大小。其次,轻量级序列块在草稿 token 之间引入依赖。序列阶段并非定义全局归一化能量模型,而是通过自回归分解诱导出因果块分布:
P(X∣x0)=k=1∏γpk(xk∣x0,x<k),pk(v∣x0,x<k)=∑u∈Vexp(Uk(u)+Bk(x0,x<k,u))exp(Uk(v)+Bk(x0,x<k,v)).此处,x0 是锚点 token,Uk 表示来自并行主干的基础 logits,Bk 是依赖前缀的转移偏置。作者通过 Markov 头部或 RNN 头部实现这一序列阶段,前者通过低秩分解将偏置限制为仅依赖前一个 token,后者维持一个循环状态以累积完整的前缀历史。
为优化系统效率,DSpark 采用置信度调度验证。一个置信度头部为每个草稿位置输出标量估计值 ck∈(0,1),模拟在所有前序 token 已被接受的条件下,当前草稿 token 能通过目标验证的条件概率。该架构使用轻量级线性投影后接 sigmoid 函数:
ck=σ(w⊤[hk;W1[xk−1]]),其中 hk 是主干隐藏状态,W1[xk−1] 是前一个草稿 token 的嵌入。为确保这些概率的绝对大小在调度中准确,作者采用序列温度缩放来校准草稿前缀被接受的联合概率。
硬件感知前缀调度器随后使用这些校准后的存活概率动态确定每个请求的最优验证长度。调度器将验证长度选择形式化为全局吞吐量最大化问题。对于一批 R 个活跃请求,发送至目标模型的总批次大小为 B=∑r=1R(1+ℓr),预期的接受 token 数为 τ=∑r=1R(1+∑j=1ℓrar,j),其中 ar,j=∏i≤jcr,i 是累积存活概率。调度器旨在最大化期望的全系统 token 吞吐量 Θ=τ⋅SPS(B),其中 SPS(B) 是采样的引擎吞吐量。通过贪心接受存活概率最高的 token,并采用提前停止机制以保持因果关系,调度器在不影响推测解码无损保证的情况下防止验证浪费。
在训练期间,目标模型被冻结,草稿模型仅更新主干、序列块和置信度头部。训练目标组合三个位置加权项:用于下一 token 预测的交叉熵损失 Lce、惩罚草稿与目标分布间总变差距离的分布匹配损失 Ltv,以及二元交叉熵置信度损失 Lconf。总体目标为加权组合:
L=αceLce+αtvLtv+αconfLconf.这种多任务训练确保草稿模型生成高质量 token,同时为调度器提供可靠的置信度估计。
实验
评估使用覆盖数学推理、代码生成和聊天的离线基准,将半自回归 DSpark 草稿器与全自回归和并行草稿器进行比较,结果显示 DSpark 通过轻量级序列头部结合了并行模型的高初始 token 容量与减少的后缀衰减。对照实验进一步表明,即使少量自回归也能带来显著的连贯性收益,并且置信度头部能够自适应剪枝低概率后缀,减少浪费的验证。在真实用户流量的在线生产部署中,DSpark 的硬件感知调度器动态调整验证长度以适应负载,将吞吐量与交互性帕累托前沿向外推移,并在严格延迟约束下保持稳健容量。
作者针对多个目标模型和领域,将 DSpark 推测解码框架与自回归和并行基线进行比较评估。结果表明,DSpark 在每个解码轮次中始终获得最高的接受长度,在所有测试配置下均优于两种基线草稿器。此外,实验揭示,与开放式聊天领域相比,结构化任务(如数学和代码)天然维持更高的接受率。DSpark 在所有目标模型规模和基准领域上一致地优于自回归 Eagle3 和并行 DFlash 草稿器。结构化任务,如数学推理和代码生成,比开放式聊天任务产生更高的接受长度。DSpark 的性能优势在不同模型家族间泛化,包括 Qwen3 和 Gemma4 目标。
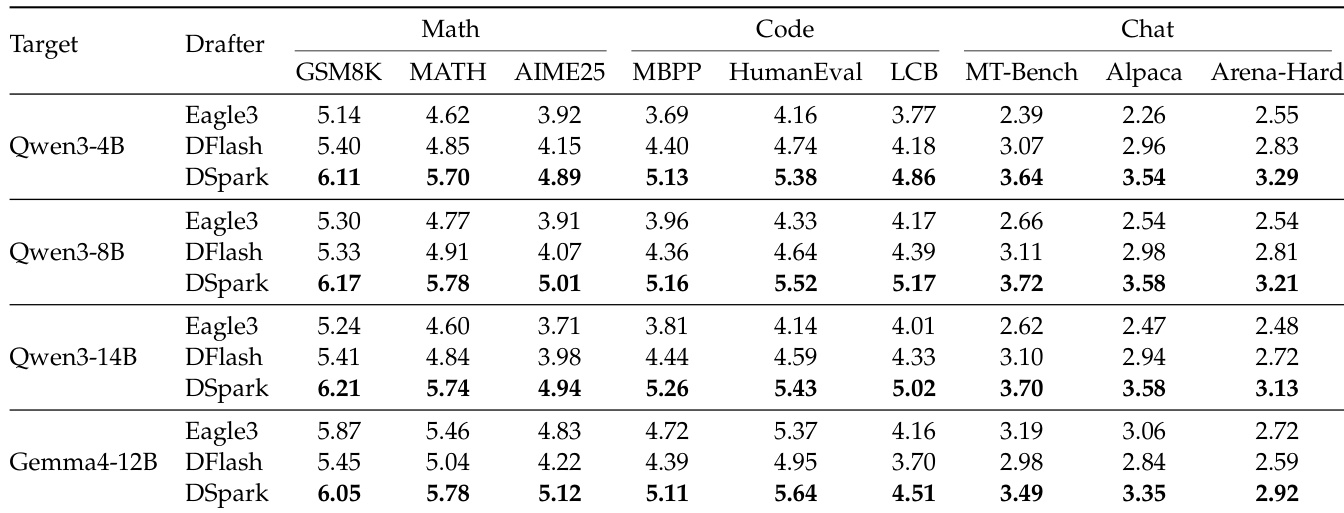
评估将 DSpark 与自回归 (Eagle3) 和并行 (DFlash) 草稿器在多个目标模型规模和领域(包括 Qwen3 和 Gemma4)上进行基准测试,测量每个解码轮次的接受 token 长度。DSpark 持续产生最高的接受长度,在所有配置上均优于两种基线,其优势跨模型家族泛化。结构化任务,如数学推理和代码生成,比开放式聊天维持更高的接受率,表明该框架在更可预测的生成环境中表现出色。