Command Palette
Search for a command to run...
BlockPilot:面向扩散推测解码的实例自适应策略学习
BlockPilot:面向扩散推测解码的实例自适应策略学习
Hao Zhang Yiming Hu Yong Wang Mingqiao Mo Xin Xiao Xiangxiang Chu
摘要
推测解码通过使用轻量级草稿模型并行生成候选令牌,再由目标模型验证,实现无损加速。近期,基于扩散的推测解码通过块级扩散每次前向传播生成多个令牌,进一步提升了并行度,达到了当前最优性能。然而,现有方法采用固定的推理块大小,并假设所有输入均适用统一的优化解码策略。本文表明,该假设并非最优,因为最优块大小因样本而异,并对推测解码性能起关键作用。此外,这些值呈现出清晰的局部结构,集中在训练块大小附近,从而将问题简化为一个低维且结构化的决策空间。基于这些见解,我们提出BlockPilot,一种样本自适应策略,从预填充表示中预测最优块大小。具体而言,我们将块大小选择形式化为轻量级策略学习问题,并提出一种实例自适应决策机制,基于预填充阶段的表示预测最优块大小。预测仅在预填充后执行一次,便于无缝集成。大量实验表明,该方法即插即用,开销极小,并能持续提升效率,在温度T=1的条件下,Qwen3-4B上达到5.92的接受长度和4.20倍的加速比。
一句话总结
阿里巴巴集团 AMAP 的研究者提出 BlockPilot,这是一种样本自适应策略,从在预填充表示上学习的轻量策略中预测扩散式推测解码的最优块大小,利用最优块大小的局部结构缩减决策空间,在温度 T=1 下于 Qwen3-4B 上达到了 5.92 的接受长度和 4.20× 的加速比。
核心贡献
- 扩散式推测解码中的最优块大小因样本而异,且局部集中在训练块大小附近,形成一个结构化的低维决策空间,可从预填充状态中学习。
- 轻量级实例自适应策略 BlockPilot 仅使用预填充表示从离散候选集中预测最优块大小,开销极小,并能无缝集成到现有框架中。
- 在 Qwen3-4B 上的实验表明,BlockPilot 在温度 1 下达到了 5.92 的接受长度和 4.20 倍的加速比,相比固定块大小策略持续提升效率。
引言
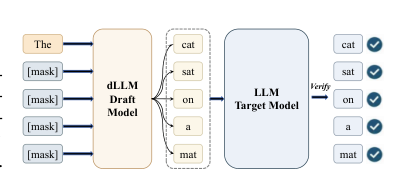
大语言模型取得了令人瞩目的成果,但其自回归解码产生了顺序瓶颈,导致高延迟。基于扩散的推测解码通过让草稿模型并行地逐块生成多个 token,再由目标模型进行验证,来解决这一问题。近期的实际系统,如 DFlash,将目标模型的隐藏状态注入扩散草稿器以提升草稿质量,但却将草稿块大小锁定为训练时继承的固定值。作者指出,最优块大小实际上取决于每个输入样本的可预测性,静态选择无法挖掘出效率增益。他们提出 BlockPilot,这是一种轻量、样本自适应的方法,利用目标模型对最后一个 token 的预填充分布,从一个小规模局部集合中预测合适的块大小。这种策略学习方式集成时无需改动目标或草稿模型,并在多种设置下提升了接受长度和推理加速。
数据集
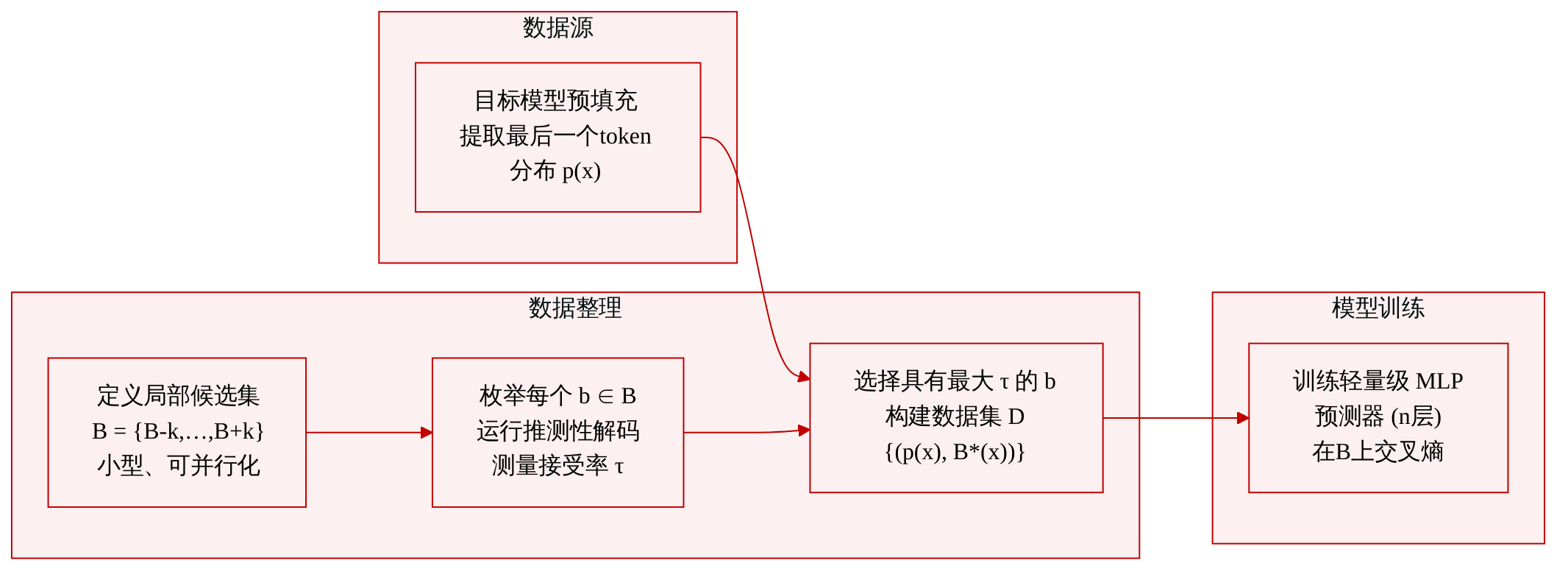
作者构建了一个有监督训练数据集,用以教会一个轻量块大小预测器如何从最后一个预填充隐藏状态中选择最优的推测解码块大小。
数据集组成与来源
- 每个样本是一个二元对:最后一个预填充位置上词汇表的预测概率分布,以及一个真实的最优块大小类别。
- 不使用外部标注数据;所有样本均离线地从目标语言模型自身生成,通过枚举候选块大小并衡量其效果来获得。
关键细节与构建过程
- 输入特征提取:对于输入提示 x,目标模型执行预填充阶段,捕获最后一个 token 的输出分布 p(x) 作为输入特征。
- 候选集:基于早先发现(发现 II),围绕基准块大小 B 定义一个小的局部候选集 B = {B−k, …, B+k}。
- 标签生成:对 B 中每个候选块大小 b,执行一次完整的推测解码过程,测量接受长度 τ(b; x)。取得最大接受长度的块大小被标注为最优块大小 B*(x)。
- 数据集:最终得到的集合 D = {(p(x_i), B*(x_i))} 包含 N 个这样的二元对。由于各候选的评估相互独立,该过程可并行化。
数据使用方式
- 该数据集仅用于训练一个浅层多层感知机(n 层 MLP),作为块大小预测器。
- 模型以 p(x) 为输入,输出候选块大小上的 logits,并使用标准交叉熵损失进行训练,最大化记录的最优块大小的概率。
- 未提及明确的训练/验证划分或混合比例;数据集按目标模型配置构建,并直接用于训练预测器。
其他处理细节
- 除特征-标签对之外,没有裁剪、增强或其他元数据。
- 候选集大小(2k+1)特意保持较小,以使得离线枚举在可处理范围内,同时仍覆盖块大小的相关动态范围。
- 特征 p(x) 已由目标模型的预填充进行了高度压缩,因此预测器可以保持紧凑并增加极少的延迟。
方法
作者提出了一种基于扩散语言模型的推测解码的样本自适应块大小选择方法。在该框架中,一个轻量扩散模型充当草稿模型,并行生成一个 token 块,随后由目标自回归模型进行验证。该过程的效率主要取决于每个验证步骤期望接受的 token 数量,即 τ(B)。每个 token 的平均生成延迟定义为 L(B)=τ(B)Tdraft(B)+Tverify(B),其中 Tdraft(B) 和 Tverify(B) 分别表示草稿生成和验证的计算成本。由于这些成本随块大小 B 呈次线性增长,最大化 τ(B) 对于提升端到端加速比 η(B)=L(B)LAR 至关重要。为此,作者旨在确定一个样本特定的最优推理块大小 B∗,而非依赖固定的训练时块大小。
为了理解最优块大小的行为,作者对候选块大小进行了穷举扫描。他们观察到显著的实例间差异,给定样本的最优块大小经常偏离训练时使用的固定块大小。此外,他们还识别出一个显著的局部区间性质:最优块大小始终落在训练块大小 B 周围一个狭窄的范围内,具体而言 B∗(x)∈{B−k,…,B+k}。
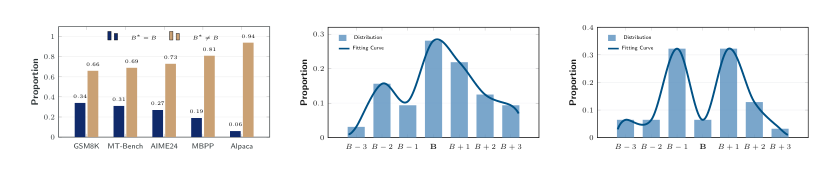
这些发现促使将块大小选择形式化为一个有限离散空间上的结构化分类任务。作者利用预填充阶段最后一个 token 的预测概率分布作为输入表示。该分布可作为输入序列的紧凑摘要,捕获上下文约束和不确定性,这使其对预测最优块大小具有高度信息性。
训练过程包含两个主要部分:监督数据构建和学习一个轻量块大小预测器。由于最优块大小并非显式标注,作者通过离线枚举构建训练数据集。对于每个输入样本 x,他们提取最后一个位置的预测分布 p(x),并评估局部邻域内每个候选块大小的接受长度。产生最大接受长度的块大小作为真实标签,由此形成数据集 D={(p(xi),B∗(xi))}i=1N。块大小预测器实现为一个轻量多层感知机。它接收预测分布作为输入,输出候选块大小集上的 logits,再通过 softmax 函数转换为概率:P(b∣x)=∑b′∈Bexp(ob′)exp(ob)。通过最小化标准交叉熵损失 L=−N1∑i=1NlogP(B∗(xi)∣xi) 来训练模型,学习从解码状态到最优块大小决策的直接映射 f:p(x)→B∗(x)。
在推理时,学习到的预测器被无缝集成到推测解码流程中。
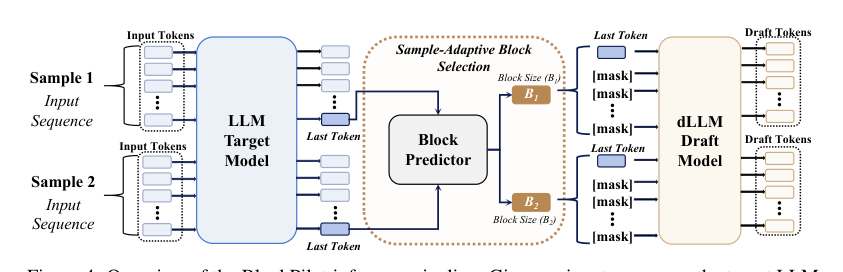
给定输入序列,目标模型首先执行预填充阶段并产生最后一个 token 的预测分布。该分布被送入块大小预测器,后者输出候选块大小的 logits。得分最高的块大小被选为 B^(x)=argmaxb∈Bf(p(x))b,并在整个后续推测解码过程中固定使用,指导草稿生成和目标模型验证。由于预测只在预填充后执行一次,且预测器是一个轻量网络,额外的计算开销极小,而自适应选择相比固定块大小策略显著提升了解码效率。
实验
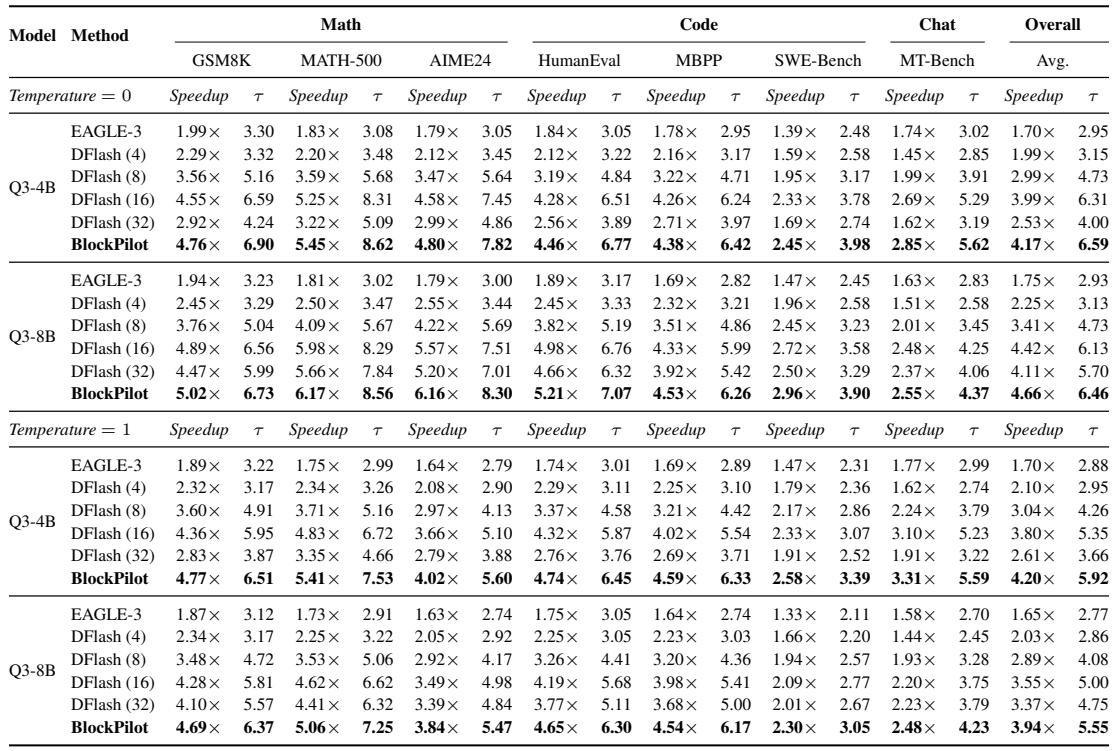
实验在涵盖数学、代码和对话基准的四款不同规模和领域的 LLM 上评估了 BlockPilot 的样本自适应块大小选择,对比自回归解码、EAGLE-3 以及固定块 DFlash 基线。BlockPilot 在确定性和随机解码下均持续取得最高加速比,甚至优于最佳固定块变体,证明了按样本调整块大小能更好地平衡并行性与验证接受率,且这一优势在所有任务类别中均成立。消融研究确认,一个两层 MLP(隐藏大小 2048)、半径 2 的候选区间、以及原始的最后 token 预填充分布作为预测器输入,构成了最优配置,因为原始分布已携带有足够的置信度信息,无需预处理。
块大小预测器与骨干模型相比引入的开销极小,延迟在个位数毫秒,内存占用远低于整个模型。这使得自适应块大小选择在推理时几乎无额外成本。预测器运行耗时 7.34 毫秒,而骨干模型需要 183 到 278 毫秒。其激活内存仅为 0.62 GB,比骨干模型所需的 8–16 GB 低一个数量级。
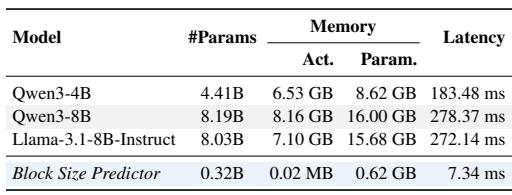
BlockPilot 在 Qwen3-4B 和 Qwen3-8B 上达到了最高加速比,在确定性和随机解码下均优于固定块 DFlash 变体及 EAGLE-3。其样本自适应块大小选择在加速比和平均接受长度上带来了持续改进,而过大的固定块则因草稿错误导致收益递减。这些增益几乎不增加延迟,且无需修改草稿模型或目标模型。在温度 0 下的 Qwen3-4B 上,BlockPilot 平均加速比达到 4.17×,超过最佳固定块 DFlash(16) 的 3.99×,并将平均接受长度从 6.31 提升至 6.59。在温度 0 下的 Qwen3-8B 上,BlockPilot 取得了 4.66× 的加速比,对比 DFlash(16) 的 4.42×,而在温度 1 下达到 3.94×,对比固定块基线的 3.55×。DFlash(32) 始终不如 DFlash(16),因为尽管并行度更高,但较大的块大小因草稿错误累积降低了 token 接受率。BlockPilot 的自适应策略在数学、代码和对话基准上均实现了更高的加速比,且在随机采样(此时草稿接受更具挑战性)下这些增益依然得以保持。该方法在不同模型规模上泛化,无需修改草稿模型或目标模型,且最后 token 的原始预填充分布是块大小预测的可靠信号。
将预测器的隐藏大小从 1024 增加到 2048,在加速比和接受长度上仅有适度改善,但进一步扩展到 4096 则没有额外益处。两层预测器始终优于单层,而第三层效果不一——在 HumanEval 上更好,但在 GSM8K 上略微变差——无明显的整体优势。将隐藏宽度扩展到 2048 以上后,所有三个基准上的加速比和接受长度均保持不变,表明已饱和。单层预测器性能逊于两层,所有任务上的加速比和接受长度均更低。
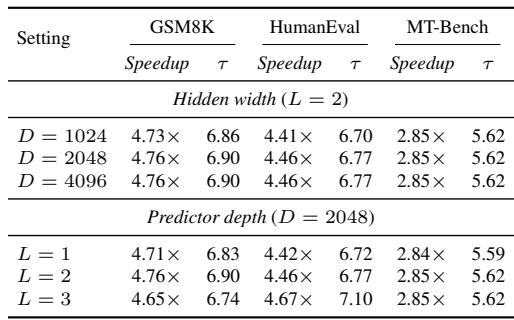
将候选区间半径从 1 增加到 2,在所有评估任务上持续提升加速比和接受长度。进一步将半径扩大到 3,在 GSM8K 和 HumanEval 上性能下降,在 MT-Bench 上仅有边际收益,表明适度较宽的区间能最好地平衡候选覆盖与预测难度。半径 2 在每个基准上都比限制性的半径 1 提供了更高的加速比和更长的接受长度。从半径 2 到半径 3,GSM8K 和 HumanEval 的加速比和接受长度下降,而 MT-Bench 有微小改善,显示出收益递减。
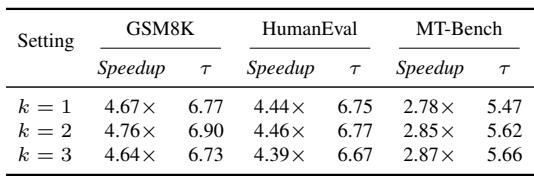
使用预填充后最后一个 token 的原始预测分布作为预测器输入,在所有基准上取得了最高的加速比和接受长度。应用 softmax 或归一化预处理持续降低性能,表明原始分布已编码了必要的置信度信号,而预处理可能抑制了有用信息。在 GSM8K、HumanEval 和 MT-Bench 上,原始预填充分布在加速比和接受长度上均优于 softmax 和归一化预处理。softmax 预处理导致最低的加速比和最短的接受长度,而归一化介于 softmax 和原始输入之间,说明任何预处理都会损害预测质量。
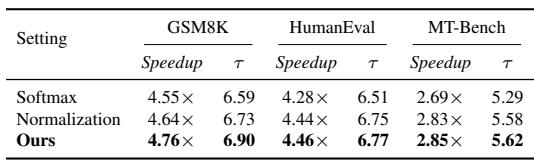
评估首先确认块大小预测器引入了可忽略的开销(个位数毫秒的延迟,内存比骨干模型低一个数量级)。在不同模型和解码模式下,BlockPilot 都通过自适应选择块大小超越固定块 DFlash 和 EAGLE-3,在不修改草稿或目标模型的情况下取得了更高的加速比和更长的接受长度。消融研究表明,最优预测器采用两层、隐藏大小 2048、候选区间半径 2 和原始预填充 token 分布作为输入;增加模型容量或应用 softmax 及归一化预处理,要么使收益饱和,要么降低性能。