Command Palette
Search for a command to run...
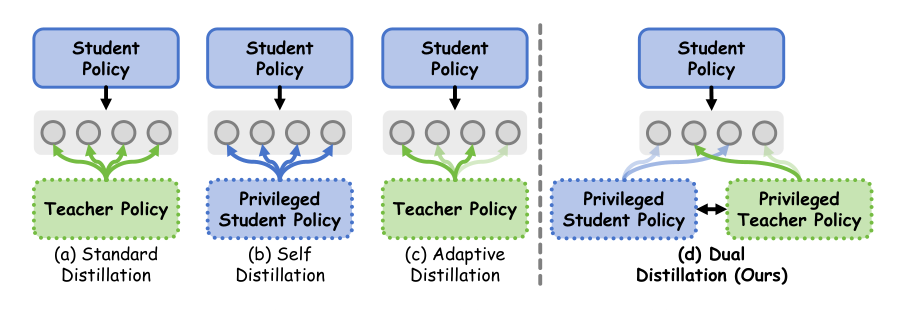
DOPD:双重在线策略蒸馏
DOPD:双重在线策略蒸馏
摘要
在线策略蒸馏(OPD)通过以密集的令牌级信号监督学生采样的轨迹,提供了卓越的能力迁移。为了提供高质量的监督来源,从而提升蒸馏的性能前沿,一个直观的方向是向教师或学生本身注入特权信息。然而,这种额外输入会引发一种我们称为“特权幻觉”的潜在失败模式:一种将学生本应缩小的可迁移能力差距与只能模仿却永远无法复制的信息不对称差距混为一谈的模式。由于令牌级监督的固有非均匀性,只有一小部分令牌承载着关键的能力信号,这一问题被进一步放大。为此,我们提出了DOPD,一种优势感知的双重蒸馏范式,它根据特权教师与特权学生策略之间的优势差距及相对概率,动态路由令牌级监督。每个令牌从教师或学生自身接收不同强度、目标和策略的监督,既传递可信的能力,又同时接收辅助信号,以缓解特权幻觉。在大语言模型(LLM)和视觉语言模型(VLM)上的广泛实验表明,DOPD始终优于普通OPD及其他同类方法。在稳定性、鲁棒性、持续学习和分布外任务上的进一步结果验证了其优越性。
一句话总结
新加坡国立大学、MMLab、香港中文大学等机构的研究人员提出了 DOPD,一种优势感知的双重在线蒸馏范式,利用教师与学生的优势差距和相对概率,动态地在特权教师策略和学生策略之间分配 token 级监督,以缓解特权幻觉,在 LLM 和 VLM 任务上持续优于基线方法。
核心贡献
- 特权幻觉被识别为在线蒸馏中的一种失败模式,即特权输入造成信息不对称,学生可以模仿但无法内化,导致性能下降和熵崩溃。
- DOPD 是一种优势感知的双重蒸馏框架,基于优势差距和相对 token 概率,动态地在特权教师和特权学生策略之间分配 token 级监督:对承载能力的 token 施加教师强蒸馏,对其余 token 进行辅助自优化。
- 在大型语言模型和视觉-语言模型设置上的实验表明,DOPD 持续优于普通在线蒸馏和其他对应方法,并在稳定性、鲁棒性、持续学习和分布外任务上带来额外增益。
引言
在线蒸馏(On-Policy Distillation,OPD)已成为一种有效的后训练方法,它通过提供密集的 token 级监督,将教师模型的能力迁移给学生,监督信号来自学生自身策略采样的轨迹。这种范式有助于减轻分布偏移,并广泛应用于大型语言和视觉-语言模型。然而,当教师或学生获得特权信息(如经过验证的推理提示或结构化的视觉标注)时,教师表面的性能优势可能源于信息不对称,而非真正可迁移的能力——作者将这种失败模式称为“特权幻觉”。之前的 OPD 方法不加区分地蒸馏所有 token,不区分能力驱动和特权驱动的增益,常常导致熵崩溃、探索减少和蒸馏效果不佳。为解决该问题,作者提出了 DOPD,一种优势感知的双重在线蒸馏框架,根据特权优势差距自适应地分配 token 级监督:在教师展现真实能力优势的 token 上施加教师强蒸馏,其余 token 上使用较轻的自监督,从而有选择性地迁移能力同时避免特权幻觉。
数据集
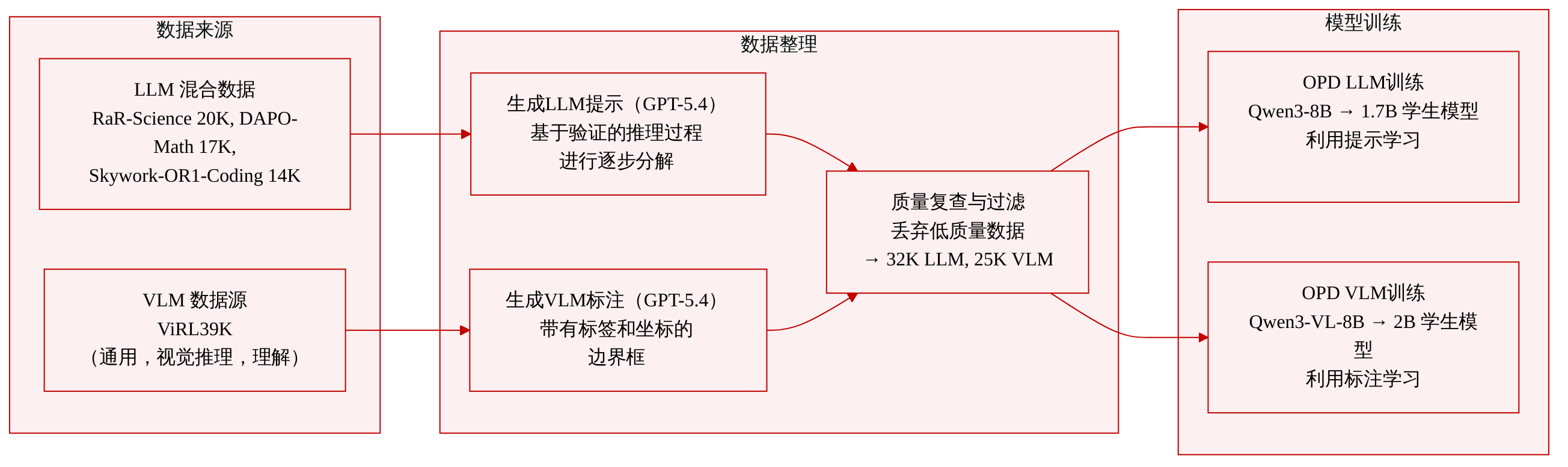
作者为语言模型(LLM)和视觉-语言模型(VLM)场景分别构建了两个训练集,均源自现有公开资源并补充了特权信息。
数据集组成与来源
- LLM 训练集:包含三个来源数据集的混合,覆盖通用、推理和编码任务:
- RaR-Science-20K(通用)
- DAPO-Math-17K(推理)
- Skywork-OR1-Coding-14K(编码)
- VLM 训练集:基于 ViRL39K 数据集,涵盖通用、视觉推理和视觉理解任务。
处理与元数据构建
- 每个样本的特权输入使用 GPT-5.4(2026-03-05)生成。
- LLM 特权信息:从经过验证的理由中提取的逐步分解提示;不包含直接的执行轨迹或最终答案。
- VLM 特权信息:结构化的视觉标注,包括与查询相关的边界框、每个框带有对象标签和四元坐标,提供明确的视觉上下文。
- GPT-5.4 进行第二次检查,剔除低质量样本。
最终数据集统计
- 过滤后,最终的 LLM 训练集包含 32K 高质量样本。
- 最终的 VLM 训练集包含 25K 高质量样本。
数据使用方式
- 数据集用于在 OPD(Output‑privileged Distillation)框架下训练非思考型学生策略。LLM 数据训练来自教师-学生对(如 Qwen3‑8B → Qwen3‑1.7B)的学生模型,VLM 数据训练如 Qwen3‑VL‑8B → Qwen3‑VL‑2B 的学生模型。
- 两个集合直接作为训练数据输入;除总大小外,未提供明确的训练/验证分割或混合比例。特权信息在训练中作为额外输入用于指导学生,教师的理由或视觉标注作为特权知识。
方法
作者识别出现有在线蒸馏(OPD)中的一个关键问题,称为“特权幻觉”,即引入特权信息会产生由信息不对称而非真正能力增强所驱动的表面性能优势。当特权输入仅授予教师或学生时,早期训练会显示微弱增益,但由此产生的信息不对称导致后期性能下降和熵崩溃。即使两种策略均能访问特权信息,统一蒸馏也无法帮助学生内化核心能力,导致其仅仅被动适应特权线索。
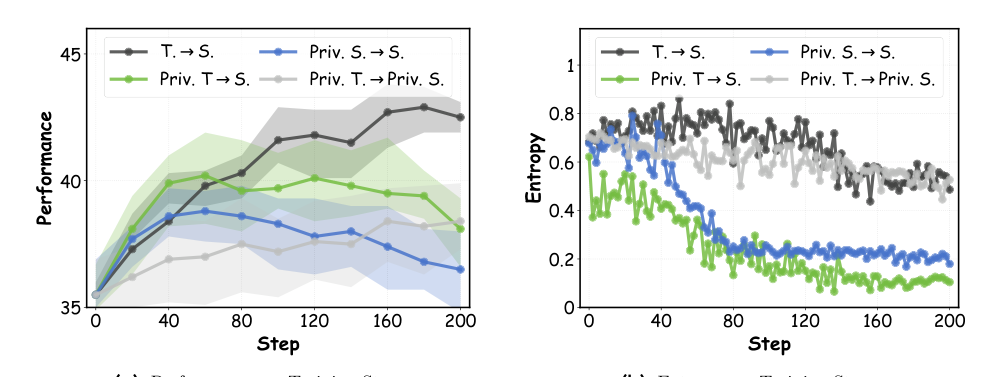
为了将能力差距与信息差距解耦,作者引入了特权优势差距。当教师策略 ΠT 和学生策略 ΠS 均能访问特权输入 p 时,它们之间的相对优势可作为特权条件下的预测差距代理。对给定输入 x 和当前 token yn,特权优势差距 A 定义为其对数概率的绝对差: A=∣logΠT(yn∣x,p,y<n)−logΠS(yn∣x,p,y<n)∣ 该指标捕获了在相同特权条件下由性能差距引起的预测差异。实验分析显示,移除具有高优势差距的 token 会导致显著性能下降,证实这些 token 包含了最关键的可迁移知识。
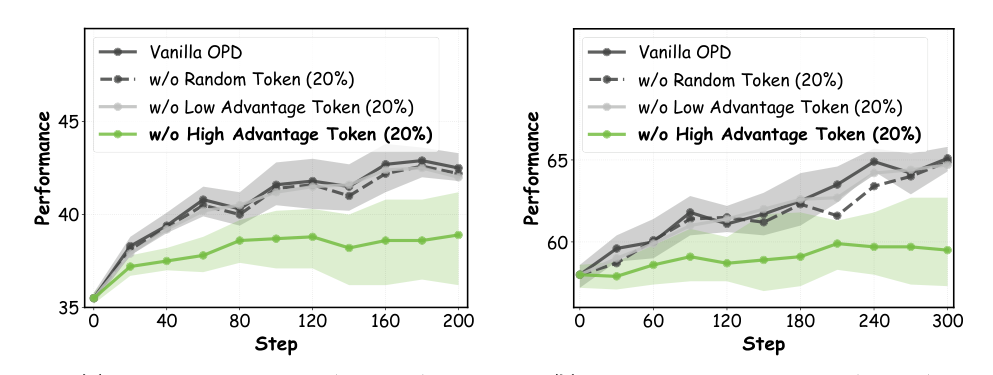
基于此,作者提出双重在线蒸馏(DOPD)。首先评估三种基于散度的目标:前向 KL 散度(促进全面模仿)、反向 KL 散度(鼓励模式寻求行为)和 Jensen-Shannon(JS)散度(提供平衡的优化信号)。标准的 OPD 目标在学生采样的轨迹上最小化教师和学生策略之间的 token 级散度。
为解决特权幻觉,DOPD 采用优势感知的双重蒸馏策略,根据 token 级的特权优势差距 An 以及 token 级概率 qS 和 qT 动态选择监督来源和蒸馏形式。排除异常值并在批次内归一化后,token 被划分为四种情况:
- 低优势,高概率(qS & qT):两种策略做出一致且置信的预测。瓶颈在于缺乏特权信息而非能力差距。作者使用 Top-K 反向 KL 的轻量教师蒸馏目标,以保守地吸收有用知识。
- 低优势,低概率(qS & qT):两种策略都分配低概率,表明该 token 超出其可靠能力范围。为避免噪声监督,他们使用特权学生作为弱自正则化锚点,通过较小系数的 Top-K 反向 KL 防止策略漂移。
- 高优势,教师高概率(qT):教师展现清晰且置信的优势。这些 token 包含关键的可迁移知识。作者使用 JS 散度进行全词汇教师蒸馏,以平衡支撑覆盖和模式集中。
- 高优势,学生高概率(qS):学生比教师更置信。强约束可能压制有效探索。他们采用带 Top-K 反向 KL 的轻量特权学生蒸馏目标,温和地鼓励一致性而不造成过正则化。
总 DOPD 目标通过指示掩码组合这四种 token 级损失,确保仅在教师展现真实能力优势时施加全词汇教师监督,从而缓解能力迁移与特权信息模仿之间的纠缠。
实验
实验使用 Qwen3(8B→1.7B)和 Qwen3-VL(8B→2B)教师-学生对评估提出的 DOPD 框架,逐步提示或结构化视觉标注作为特权信息。在多个 LLM 和 VLM 基准上,DOPD 始终优于标准蒸馏、自蒸馏和自适应蒸馏基线,恢复了高达 89.8% 的教师-学生差距,并在推理和编码任务上偶尔超越教师。该方法表现出跨模型规模的强泛化性、稳定训练和有效的持续学习,而消融实验揭示,面向能力的提示和 token 级自适应蒸馏对这些增益至关重要。
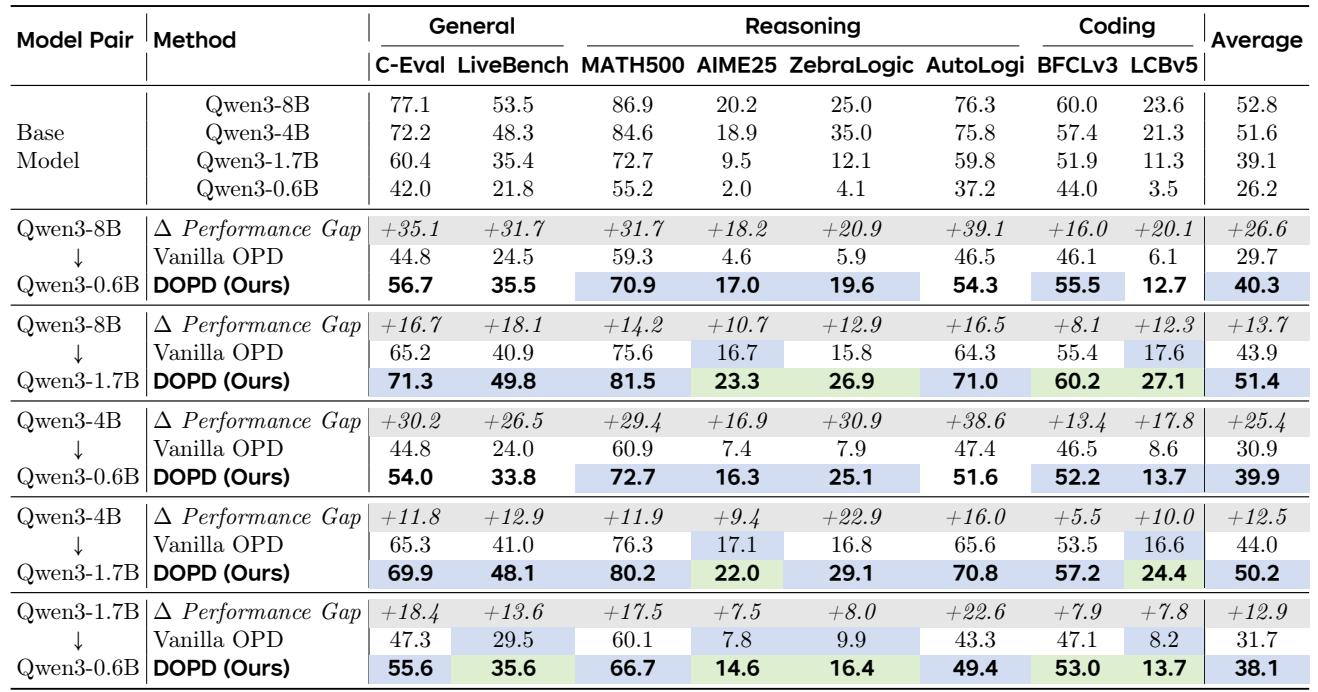
提出的 DOPD 方法大幅缩小了学生与教师策略之间的性能差距,平均恢复了近 90% 的原始差距。它不仅接近而且在四个具有挑战性的基准上超过了教师,尤其是在推理和编码任务中。DOPD 在全部八个评估基准上持续取得最佳结果,显著优于强大的自适应蒸馏基线。DOPD 平均恢复了 89.8% 的教师-学生性能差距。该方法在四个推理和编码基准上超过了教师策略。DOPD 平均比最强的自适应蒸馏基线(ExOPD、Uni-OPD、EOPD)高出超过 4 个点。自蒸馏基线仅提供微弱改进,突显了优势感知双重蒸馏的优势。
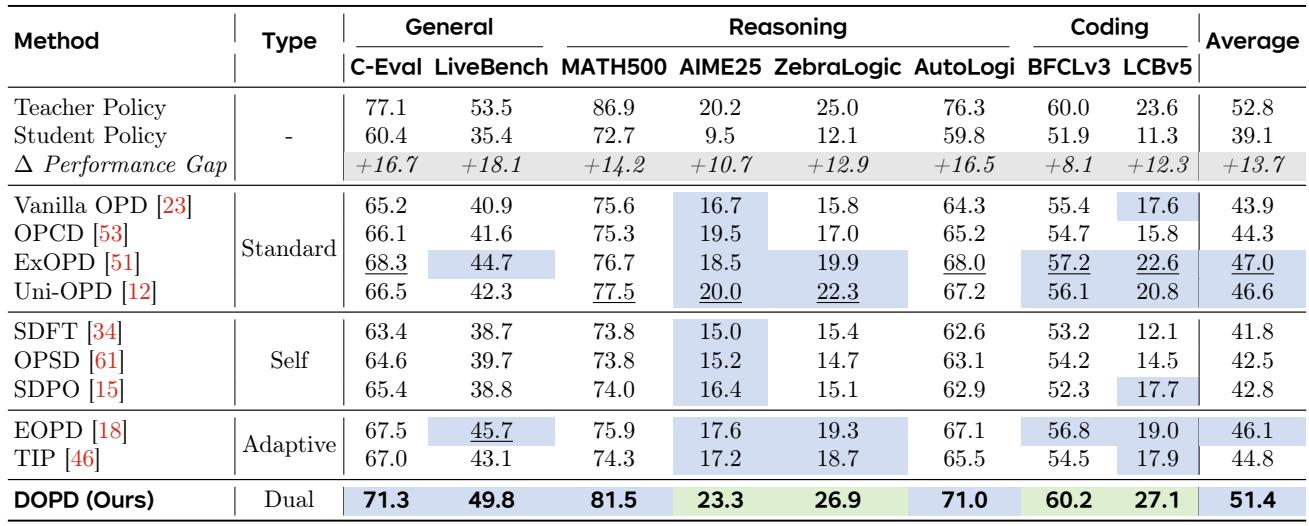
在基于 VLM 的偏好蒸馏上,DOPD 将学生策略提升 10.1 个点,恢复了 69.2% 的教师-学生差距。它取得了最高平均分数,比普通 OPD 高 6.0 个点,并比 Uni-OPD、Vision-OPD 和 VA-OPD 分别高出 2.1 到 4.2 个点。在视觉理解任务上增益尤为显著,该任务中初始学生-教师差距最大。DOPD 相对于学生策略实现了 10.1 个点的绝对增益,平均分达到 58.4,缩小了 69.2% 的教师-学生差距。与最强的面向 VLM 的蒸馏基线相比,DOPD 平均改进幅度为 2.1 到 6.0 个点,对普通 OPD 的优势最大。
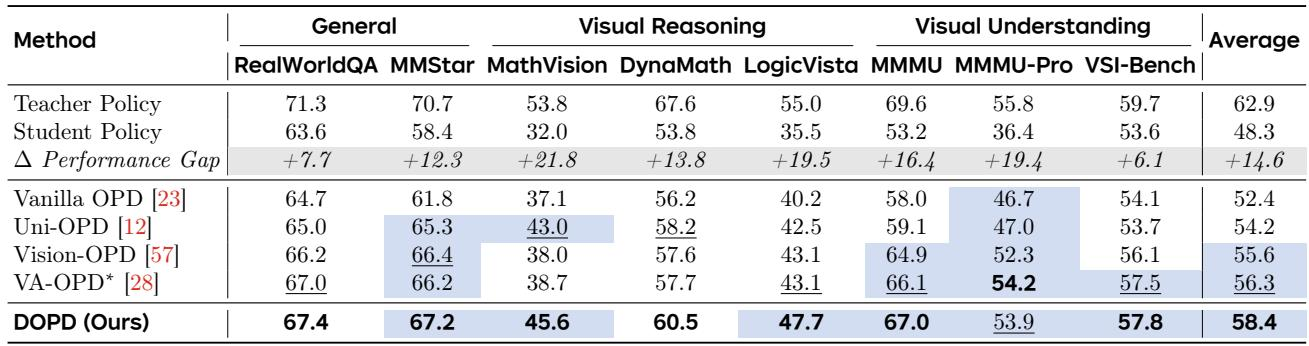
DOPD 在每一对测试的教师-学生对上均超过普通 OPD,平均增益高达三倍以上,并在规模差距大时展示出特别优势。当容量差距扩大时,普通蒸馏表现挣扎,而 DOPD 维持或增加其改进,在最极端的不匹配场景中恢复了超过一半的教师-学生性能差距。这些结果证实了该方法在不同模型规模上的鲁棒性和可扩展性。DOPD 在五种教师-学生配置下实现比普通 OPD 大 2-3 倍的平均性能提升。在最大不匹配情况(Qwen3-8B → Qwen3-0.6B)下,DOPD 取得 14.1 个点增益,恢复了 53.0% 的教师-学生差距,而普通 OPD 仅增益 3.5 个点。随着师生尺寸比增大,普通 OPD 的增益减弱,而 DOPD 的增益增长或保持稳定,表明其更好地处理分布不一致性。
使用最终答案作为特权信息会导致学生模型过拟合,表现比不提供特权输入更差。提供不含执行轨迹的逐步提示取得最高准确率,在两个评估基准上均明显优于所有其他特权形式。最终答案蒸馏的表现低于无特权基线,在 C-Eval 和 LiveBench 上的得分最低。不含执行的逐步提示达到最佳结果,相比无特权输入,在 C-Eval 上提高超过 8 个点,在 LiveBench 上提高超过 10 个点。总结性提示提供中等增益,而包含执行轨迹的逐步提示几乎与不提供特权信息持平。

使用基于 VLM 的特权信息时,直接提供最终答案相比无特权输入只有微小提升,而提供空间定位线索(如带对象标签的边界框)在两个基准上带来显著更大的准确率增益。在所有策略中,边界框加对象标签的组合作为特权输入取得了最大改进,明显优于仅使用标注、仅使用边界框或提供最终答案。

评估检验了 DOPD 在文本和视觉-语言偏好蒸馏上的表现,跨越八个基准,将其与强大的自适应基线进行比较,并分析特权信息策略。DOPD 持续恢复几乎全部的教师-学生性能差距,在推理和编码任务上超越教师,并且在模型规模差距增大(普通蒸馏失败)的情况下增益更大。消融实验显示,不含执行轨迹的逐步推理提示和空间定位视觉线索(如带对象标签的边界框)明显优于最终答案或执行轨迹先验。