Command Palette
Search for a command to run...
超越独立同分布:表格基础模型究竟有多通用?
超越独立同分布:表格基础模型究竟有多通用?
Lennart Purucker Andrej Tschalzev Nick Erickson Gioia Blayer David Holzmüller Alan Arazi Alexander Pfefferle Mustafa Tajjar Gaël Varoquaux Frank Hutter
摘要
用于表格数据预测机器学习的基础模型近期在学术界和工业界获得了显著关注。各学科研究社区正越来越多地在多样化数据集和任务上评估表格基础模型。然而,这些针对特定任务和学科的评估对模型研究者而言大多难以获取,因为基准软件和评估协议碎片化。因此,模型研究者依赖标准基准,这些基准大多定义在表格基础模型已表现优异的任务上。最具挑战性的场景被排除在外,导致该领域将重点放在独立同分布数据上的边际改进,而非更广泛、更艰巨的挑战,从而限制了有意义的进展。为克服这一问题,我们引入了BeyondArena,这是首个统一的表格数据整体基准,支持多样化的任务类型(独立同分布、时间、分组),涵盖不同样本量和特征维度规模,并包含来自广泛学科的多样化特征类型(含文本、高基数特征)。为支持超越标准基准的统一评估,我们推出了DataFoundry,一个用于整理预测机器学习表格数据集的Python框架和元数据模式。我们在11个模型和142个精选数据集上的结果表明,现有表格基础模型在小型至中型独立同分布数据上表现优异,而传统的树模型和深度学习模型在非独立同分布、大规模和高维数据集上仍占主导地位。BeyondArena为表格数据中最具挑战性的任务指引模型研究,推动迈向真正基础的表格模型。
一句话总结
Prior Labs、弗赖堡大学、INRIA Saclay等机构的研究人员提出了BeyondArena,这是首个支持独立同分布(IID)、时序和分组任务的统一表格数据基准,并推出了一个数据集构建框架DataFoundry。在11个模型和142个数据集上的评估表明,现有表格基础模型仅在小规模IID数据上表现优异,而基于树的方法和深度学习方法在非IID、大规模和高维任务上占据主导地位,凸显了对真正通用表格AI的需求。
核心贡献
- BeyondArena是一个统一基准,整合了IID、时序和分组的表格任务,覆盖不同数据集规模、特征维度和模态(文本、高基数),基于来自多个领域的142个精选数据集提供标准化评估。
- DataFoundry是一个Python框架和元数据模式,用于可复现的数据集构建,支持跨任务范式的一致预处理、验证和基准测试。
- 对11个模型的评估显示,表格基础模型在中型到中型规模的IID数据上表现突出,但在非IID、大规模和高维数据上被基于树和深度学习的方法超越,揭示了未来模型需要解决的关键缺陷。
引言
表格基础模型(TFMs)已被广泛评估,但表格研究社区大多将基准测试局限于独立同分布(IID)任务,忽略了现实预测应用中常见的分组和时序划分。此前的努力也面临碎片化问题,不同规模和类型的表格(小规模、时序或富含文本)使用各自独立的基础设施和标准,给从业者带来困扰并拖慢了进展。作者提出了BeyondArena,一个统一基准,涵盖IID、时序和分组任务,覆盖广泛的样本量、维度和特征类型(包括高基数类别特征和文本数据)。通过精选142个高质量数据集并将11个模型集成到开源的TabArena生态系统中,他们提供了一套严格且标准化的评估,揭示了当前TFMs的优势所在(小到中型IID数据)以及传统模型仍占据主导地位的情境(非IID、大规模、高维设置)。
数据集
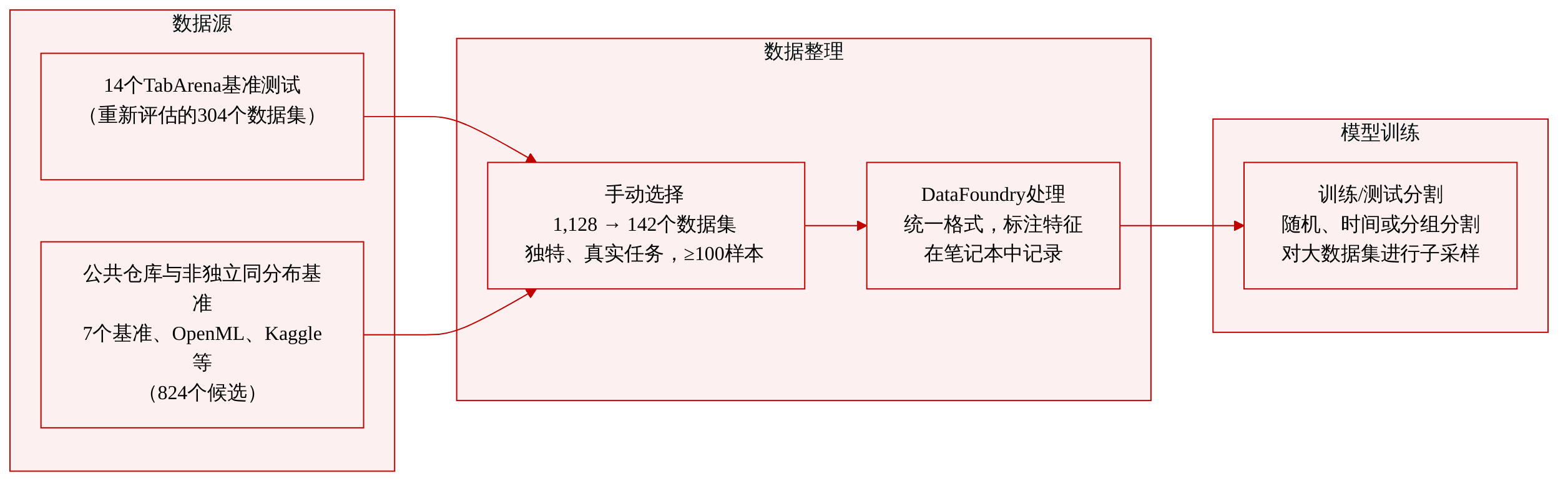
作者构建了BeyondArena,这是一个经过人工验证的142个表格数据集集合,旨在反映具有挑战性的现实预测任务。该集合扩展了先前的基准,纳入了非IID场景(时序和分组划分)、训练样本少于500或多于100,000的数据集,以及包含文本和日期特征的表格。
数据集组成与来源
- 初始候选池包含1,128个候选数据集,来自21项先前的表格基准研究、公共仓库(UCI、OpenML、Hugging Face、Kaggle、Zindi、ASlib)以及政府网站。
- 重新评估了来自14个早期TabArena基准(包括已被接受和此前被拒绝的)中的304个数据集。
- 7个非IID或多模态基准(TabReD、TableShift、CARTE、TextTabBench、TabSTAR、AutoGluon Multimodal以及一个字符串向量化基准)贡献了额外的候选数据集。
每个数据集的关键细节
- 选择规则: 数据集必须在基准内是唯一的,包含至少100个训练样本,支持随机、时序或分组验证划分,已明确发布用于分类或回归任务,代表真实应用(非纯合成数据或向量化图像),并且不涉及明显的伦理问题。
- 筛选结果: 经人工审核后,142个数据集满足所有标准;被拒绝的大多数是因为重复、缺乏真实任务或原本并非为监督预测而设计。
- 特征: 最终集合涵盖小规模到大规模数据集,包含多种特征类型(数值、类别、日期、文本),覆盖分类和回归任务,并来自多样化的应用领域。这142个数据制品托管在Hugging Face上。
论文如何使用这些数据
- 每个数据集通过DataFoundry框架进行处理,该框架统一了文件格式(CSV、Parquet、Excel),并标注特征类型、目标列以及组或时间索引的元数据。
- 作者为每个数据集定义了训练-测试划分——根据原始任务描述采用随机、时序或分组划分。对于非常大的数据集,采用子采样以保持训练的可管理性,同时保留任务的预测挑战性。
- 未使用显式的混合比例或裁剪;相反,经过筛选的数据集作为一个独立的基准套件,每个数据集根据其指定的划分和预处理进行单独评估。
- 仅在必要时应用特征工程,以与原始任务对齐(例如,如论文或获胜竞赛方案中所述),所有处理步骤均在可复现的Python笔记本中记录。
方法
作者旨在扩展表格基准测试,以更好地代表具有挑战性的现实世界中预测性机器学习应用。为此,他们彻底修订了选择标准,以支持非IID数据(时序和分组)、训练样本少于500或多于100,000的数据集,以及包含文本和日期特征的表格数据。为确保高质量和代表性,作者采用劳动密集的人工筛选过程,所有结果均由人工验证,这对科学严谨性至关重要。
为实现大规模且可复现的数据集构建,作者引入了DataFoundry,一个面向表格数据集和预测性机器学习的Python框架和元数据模式。DataFoundry提供一个成熟的Python包,用于数据集校验、训练-测试划分,以及可扩展的元数据模式,同时配有处理每个数据集的可复现Python笔记本。
作者从21个表格基准研究和公共数据仓库中收集数据集,包括UCI机器学习仓库、OpenML、Hugging Face、Kaggle等。他们重新评估了先前基准中的数据集,并从非IID或多模态表格基准中收集数据。
一个数据集必须满足特定标准才能被纳入BeyondArena:它必须代表一个独特的预测性机器学习任务,至少包含100个训练样本以避免小样本任务,支持恰当的验证协议如随机、时序或分组划分,已作为预测性分类或回归任务发布,代表一个真实世界应用问题,并且不涉及明显的伦理问题。
选择工作流如下图所示:
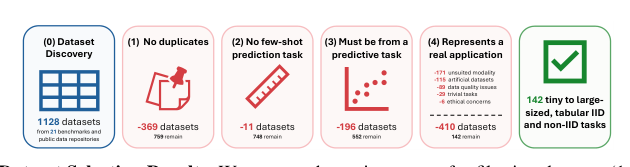
从各种来源的1128个数据集开始,作者过滤掉重复项、小样本预测任务、非预测性任务以及不代表真实应用的数据集。经过严格过滤,最终得到142个选定数据集,涵盖从小规模到大规模的各种规模,以及表格IID和非IID任务。
每个选定数据集都经过彻底研究并集成到DataFoundry中。作者统一了数据格式和特征类型标注,包括数字、类别、日期和字符串。他们将任务所需的元数据和标注存储在机器可读的模式中。必要时进行特征工程以构建适当的任务。
选定数据集的特征如下图所示:
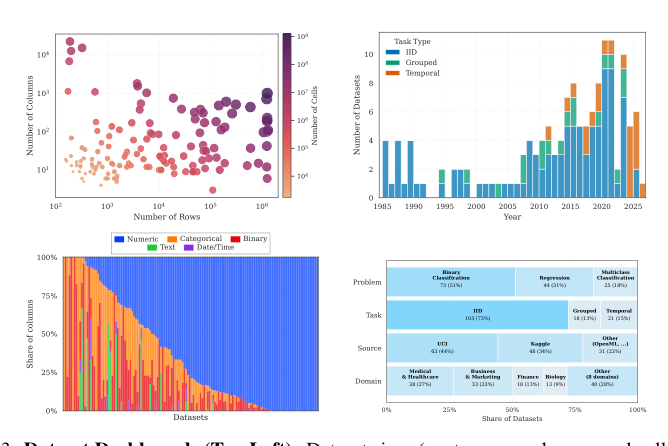
这些数据集在行数、列数、单元格数、数据年龄以及特征类型(如数值、类别、二元、文本和日期/时间)方面差异很大。它们涵盖多种问题类型,包括二元分类、回归和多分类,以及不同的任务类型,如IID、分组和时序。该集合涵盖多个来源和应用领域,包括医疗与健康、商业与营销、金融和生物学。
实验
BeyondArena基准在多样化的数据集特征(如规模、维度、任务类型和特征类型)上评估了11个表格模型,其中包括多个表格基础模型(TFMs)。虽然TFMs在小型、微型和IID数据集上表现强劲,但在时序、分组、大规模、高维和高基数任务上,经过良好调优的传统模型——尤其是像RealMLP这样的深度网络——始终更胜一筹。总体而言,TFMs在70%的数据集上能够匹敌或超越最佳的传统模型,但其预训练的通用性在许多现实世界非IID场景中仍显不足,需要进一步发展。消融实验证实了采用适当的非IID划分和预处理的重要性,并表明事后校准通常能提高对数损失性能。
消融实验证实,BeyondArena的内部划分策略(重复5折交叉验证和非IID划分)是稳健的,能够持续提高平均性能同时保持排名稳定。针对分组和文本数据的预处理决策效果不一:对每个样本都有标签的数据集处理组索引会显著改变排名,而在长文本特征上使用TF-IDF而非Qwen3嵌入能够大幅提升性能且不改变模型排序。事后概率校准几乎总是优于未经校准的默认设置,仅少数几个特例模型除外。将8折交叉验证替换为5×5折交叉验证可在保持排名几乎不变(τ=0.93)的同时提升模型性能。对时序和分组数据使用非IID内部划分而非IID划分能达到更好的平均性能,且模型排名完全相同(τ=1.00)。对于每个样本都有标签的分组数据集,丢弃索引预处理会极大打乱模型排名(τ=0.43),尽管BeyondArena的预处理仍然在71%的比较中获胜。在长文本数据集上,从Qwen3嵌入切换到TF-IDF能大幅提升预测性能,而BeyondArena的Qwen3设置在仅6%的比较中获胜,但排名仍高度相关(τ=0.89)。应用事后概率校准在82%的情况下优于无校准的默认设置,但可能对TabPFN-2.6和RealMLP产生负面影响。

消融实验证实,BeyondArena的内部划分策略——重复5折交叉验证和非IID划分——能够持续提高平均性能且保持模型排名稳定。针对分组和文本数据的预处理决策效果不一:对每个样本都有标签的数据集,处理组索引至关重要;而在长文本特征上使用TF-IDF而非Qwen3嵌入能够在不扰乱模型排序的前提下大幅提升预测能力。事后概率校准几乎总是优于无校准的默认设置,尽管可能对TabPFN-2.6和RealMLP产生不利影响。总体上,核心设计选择是稳健的,校准和谨慎的预处理是提升性能且不损害排名一致性的关键。