Command Palette
Search for a command to run...
场景即物体,而非基元:从无位姿视角实现实例结构化的三维分词
场景即物体,而非基元:从无位姿视角实现实例结构化的三维分词
Mijin Yoo In Cho Subin Jeon Jiwoo Lee Eunbyung Park Seon Joo Kim
摘要
三维场景是通过其构成的物体来理解的,而非组成物体的基元。然而,前馈重建方法输出的是密集、无结构的点集或高斯分布,将物体级结构的恢复留待后处理。我们提出了一种前馈框架,直接从无位姿的多视角图像中将场景分解为实例结构化的三维分词组——这些紧凑的以物体为中心的单元,使得重建、分割和操作皆可由此展开。每个分词组将捕捉实体级身份的实例分词与编码局部几何和外观的锚点分词配对,并解码为一组三维高斯分布。这种两层分解将物体身份与局部外观解耦,使物体实例成为表示的原生接口,而非派生结果。分词组通过可微渲染结合联合重建与分割监督进行学习,无需任何三维标注。我们的前馈模型在类别无关的实例分割上超越了逐场景优化基线,同时在新视角合成中保持竞争力。除了这些指标,相同的分词组还直接支持实例级场景编辑——通过操作其组来移除、平移或插入物体——以及高效的开放词汇三维实例检索,其中检索复杂度随实例数量而非基元数量增长。
一句话总结
由延世大学和首尔大学的研究者提出,一种前馈框架从未标定位姿的多视图图像中将场景分解为以实例结构化的 3D token 组,通过两级 token 解耦物体身份与局部外观,并在无 3D 标注的情况下通过可微渲染以及联合重建/分割监督进行训练,它在类别无关的实例分割中超越了逐场景优化方法,同时支持直接的实例级编辑和高效的开放词汇检索。
核心贡献
- 该方法是一个前馈框架,直接从未标定位姿的多视图图像中将 3D 场景重建为以实例结构化的 token 组,每个组由一个捕获物体级身份的实例 token 和编码局部几何与外观的 anchor token 组成,并被解码为 3D 高斯体。
- 在无 3D 标注的情况下,通过可微渲染以及联合重建加分割监督进行训练,该模型在类别无关的实例分割中超越了逐场景优化基线,同时在新视图合成方面保持竞争力。
- 同样的 token 组直接支持实例级场景编辑(移除、平移和插入物体)以及高效的开放词汇 3D 实例检索,其复杂度随实例数量而非基元数量增长。
引言
为使 3D 场景支持物体级推理,表征必须以完整物体而非单个基元作为一等单元。现有的前馈重建方法产生密集且无结构的高斯体或点集合;即便从 2D 模型中提升出逐基元语义,物体身份依然分散,任何实例级操作都依赖于事后分组。作者针对这一表征错位,通过单次前向传递将场景重建为一个紧凑的、以实例结构化的 token 组集合。每个组将一个捕获物体身份的实例 token 与编码局部几何的 anchor token 耦合在一起,从而产生一种表征,其中物体是显式且可操作的接口,同时适用于重建和分割任务,且无需任何 3D 标注。
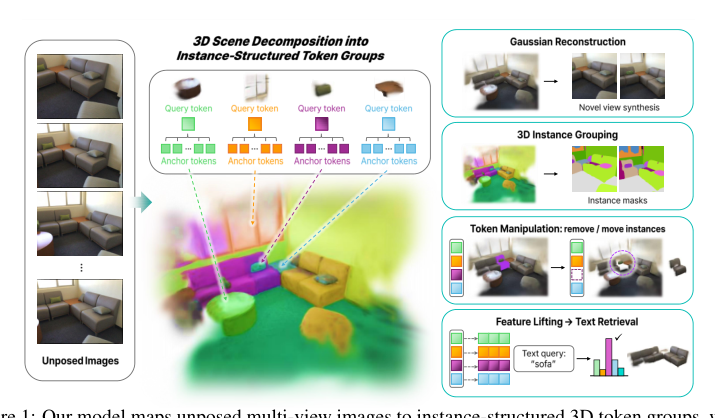
方法
作者提出了实例结构化的token 组,这是一种从未标定位姿的多视图图像构建的前馈 3D 场景表征。每个组将一个捕获实体级身份的实例 token 与编码局部几何和外观的 anchor token 配对,这些 token 随后被解码为一组 3D 高斯体。
参考框架图:
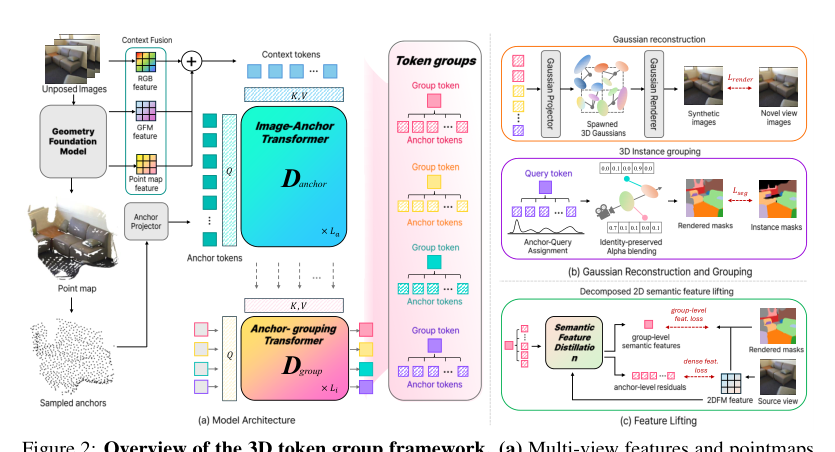
如下图所示,模型架构从一个冻结的几何基础模型开始,该模型从输入图像中提取多视图特征和点云图。这些信息被融合为上下文 token。图像-anchor 变换器通过交叉注意力处理这些上下文 token 以产生 anchor token,anchor-分组变换器则通过交叉注意力处理 anchor token 以产生组 token。这些组 token 通过 softmax 分配竞争 anchor 的归属权。
多视图特征编码与 Token 初始化 给定 V 张未标定位姿的 RGB 图像,冻结的 3D 基础模型提取多视图特征和点云图。点云图经下采样以获得与图像块对齐的 3D 坐标。为提供额外的外观和几何线索,RGB 图像和点云图被线性分块后加入基础模型特征中。得到的特征被展平,作为 token 组解码器的多视图上下文。
Anchor token 从与图像块对齐的 3D 坐标及其对应的上下文特征初始化。作者对所有图像块坐标应用最远点采样,选出 K 个 anchor 位置。位于 ak 位置的第 k 个 anchor token 初始化为: Ak(0)=xak+ϕpos(ak) 其中 xak 是在被选为 anchor 位置 ak 的图像块处的上下文特征,ϕpos 是一个将 3D 坐标投影到特征维度的 2 层 MLP。L 个组 token 初始化为可学习的嵌入。
Token 组解码与高斯重建 Token 组解码器由两个交叉注意力变换器组成:图像-anchor 解码器和 anchor-组解码器。图像-anchor 解码器通过对上下文特征进行交叉注意力,将 anchor token 与多视图上下文关联起来。随后,anchor-组解码器通过对解码后的 anchor 进行交叉注意力来更新组 token,使得每个组 token 能够聚合物体级信息: A=Danchor(A(0),X),G=Dgroup(G(0),A) 其中 D(Q,Z) 表示一个交叉注意力变换器,它利用上下文 Z 更新查询 Q。
每个解码后的 anchor 在 L 个组上的分配概率,通过其与组 token 之间点积相似度的 softmax 计算得到: πk,ℓ=softmax({⟨Ak,Gℓ′⟩}ℓ′=1L)ℓ 此 softmax 操作在组 token 之间引起了对 anchor 归属权的竞争。每个解码后的 anchor 随后通过一个 2 层 MLP 映射为 Ng 个 3D 高斯体,MLP 负责预测高斯体属性,包括位置偏移、尺度、旋转、不透明度和球谐系数。每个生成的高斯体继承其父 anchor 的分配得分。
通过联合重建与分组监督进行训练 这些解码器完全通过 2D 监督进行训练。预测的高斯体在目标视点处被渲染,并针对真实图像进行监督,使用组合的 MSE 和感知损失: Lrender=Lmse+λlpipsLlpips 为了监督分组,作者将 anchor 到组的分配问题建模为 2D 实例分割问题。每个高斯体继承其父 anchor 的分配概率;通过 alpha 合成渲染这些概率即可得到实例概率图。遵循标准 2D 分割流程,在预测掩码和真实掩码之间执行匈牙利匹配。对于每个匹配对,施加逐像素的二元交叉熵损失和 Dice 损失: Lseg=λbceLbce+λdiceLdice 完整的训练损失结合了这两个目标,并在初始训练步骤中对分割损失权重施加线性预热,以确保在初始几何形成后分组监督充分生效。
解耦的语义特征蒸馏 实例结构为整合语义提供了天然基础。token 组并未将高维特征向量独立地附加到每个高斯体上,而是实现了一种解耦化表征。一个共享的组级嵌入捕获每个实例的主导语义,而低维的 anchor 级残差则负责组内空间变化的细节。
给定逐视图的 2D 基础特征,训练好的图像-anchor 交叉注意力被复用以将这些特征聚合为 anchor 语义 token。组级语义 token 由一个额外的 anchor-组交叉注意力变换器产生。在渲染时,每个 anchor 被硬分配至其最高概率的组,且该独热分配和 anchor 级残差组成的元组被附加到从该 anchor 生成的所有高斯体上。完整的逐像素语义特征按如下方式重建: Fv(u)=∑ℓS^v,ℓ(u)sℓ+WrR^v(u) 其中 Wr 将残差投影回基础特征维度。作者优化两个互补的损失:一个是像素级余弦相似度损失,驱动完整重建特征与基础模型输出相匹配;另一个是组级对齐损失,直接监督每个组嵌入以捕获物体级语义摘要。这强制了组级和 anchor 级之间清晰的角色分工。
实验
该 token 化框架在 ScanNet 上针对重建、特征提升和实例分割进行了评估,并随后应用于实例级编辑和开放词汇检索。Token 组表征实现了更优的开放词汇特征提升以及完全前馈的实例分割,超越了逐场景优化方法,同时在零样本迁移下原始重建质量的差距在缩小,表明其具有更可迁移的场景先验。消融实验证明,带有分割损失预热的联合训练对于稳定涌现连贯的分组至关重要,且将语义分解为组级语义和 anchor 级残差有效地捕获了实例身份和子实例细节。最终表征支持从单次前向传递直接进行自然的实体级操作和检索,无需掩码或逐场景优化。
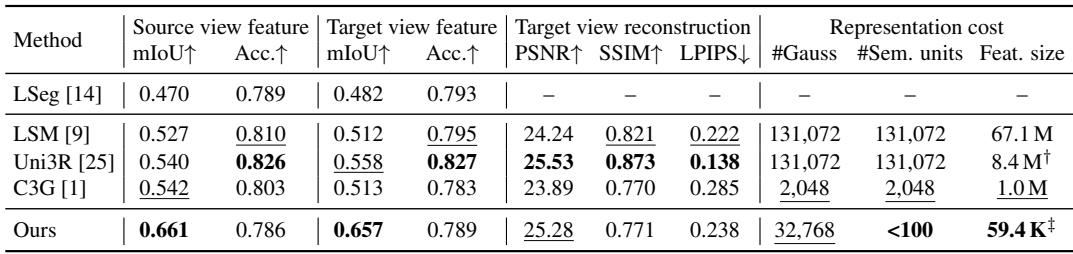
所提出的模型在源视图和目标视图上均以明显优势实现了最高的特征提升 mIoU,同时使用的存储特征标量数量大幅减少。语义存储量从其他方法中的 8.4M 或 67.1M 降低至仅 59.4K,这是因为实例级 token 组将语义集中起来,而非将其分布到各个高斯体上。重建质量具有竞争力,在使用极少的高斯基元情况下达到了第二高的 PSNR。该模型在源视图 mIoU 上达到 0.661,目标视图 mIoU 上达到 0.657,以不到 100 个语义单元的性能超越了次优方法(分别为 0.542 和 0.558)。存储的特征标量降至 59.4K,相比之下 Uni3R 需要 8.4M,LSM 需要 67.1M,而重建 PSNR(25.28)在仅使用 32,768 个高斯体的情况下依然接近 Uni3R 的 25.53。
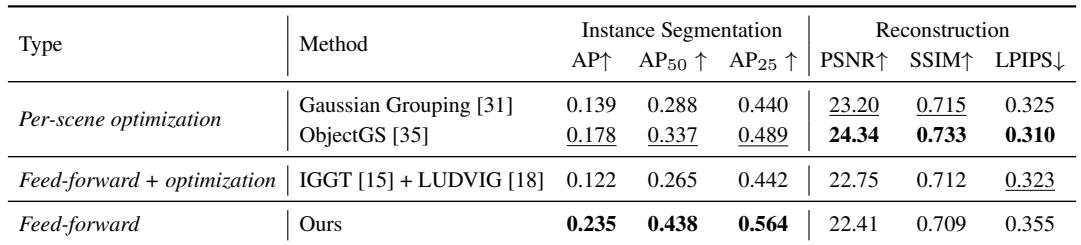
在 8 个上下文视图下,基于 token 的前馈模型在所有 AP 指标上均实现了最佳的实例分割,超越了逐场景优化基线和带有事后优化的前馈方法。尽管使用了紧凑的、基于 token 的表征,重建质量依然保持竞争力,同时实例分割结果明显更干净、更连贯。该模型取得了最高的实例分割分数,超越了逐场景优化的 Gaussian Grouping 和 ObjectGS,以及 IGGT+LUDVIG 前馈+优化管线。即使该方法不执行逐场景优化,并且依赖于紧凑的基于 token 的表征,但重建指标仍接近顶级的逐场景优化器。这种完全前馈的方法仅通过 2D 监督进行训练,却超越了那些需要逐场景分组或优化的方法,这表明原生实例结构是比事后聚类更强的归纳偏置。
重建与分割的联合训练取得了最强的结果(PSNR 25.11,AP 0.193)。先训练重建再冻结其权重进行分割,会导致 AP 骤降至 0.032 并降低重建指标。省略分割损失预热会使重建 PSNR 降至 23.09,同时分割 AP 部分恢复至 0.081,但两种变体均远低于联合训练方案。顺序训练导致实例分割 AP 从 0.193 骤降至 0.032,表明仅靠重建无法诱发必要的分组结构。若不进行预热,重建 PSNR 降至 23.09,分割 AP 仅达到 0.081,表明早期的几何稳定性对两个目标都有好处。
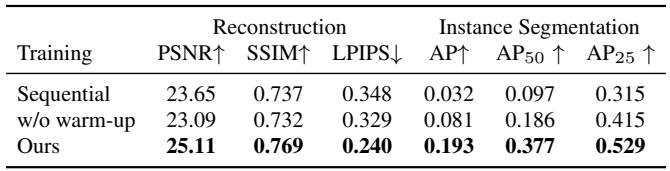
关于特征提升的消融实验表明,完全依赖 anchor 残差会产生最差的结果,而仅使用共享的组级特征就已达到强劲的性能。将 anchor 残差加入组嵌入取得了最高的精度,证实了一种分工方式:即组特征承载实例级语义,而 anchor 残差捕获细粒度的子实例变化。组独有方案显著优于 anchor 独有方案,表明共享的组嵌入是主要的语义承载者。完整分解方案(组 + anchor)达到了最高的 mIoU 和准确率,因为 anchor 残差提供了组特征单独无法表示的局部细节。仅靠 anchor 残差的性能最差,因为低维特征在没有共享组嵌入的情况下缺乏表征完整语义内容的能力。
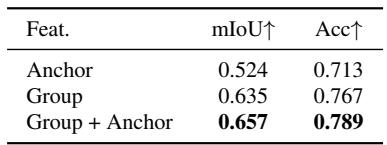
所提出的模型通过将语义集中入实例级 token 组,大幅压缩了语义存储量,仅以极少数的存储特征实现了最高的特征提升 mIoU。借助多个上下文视图,基于 token 的前馈模型在实例分割上超越了逐场景优化和事后分组方法,表明原生的分组方式构成更强的归纳偏置。重建与分割的联合训练至关重要,因为顺序训练会导致分割性能崩溃并降低重建质量。消融实验揭示,共享的组嵌入承载主要的语义信号,而 anchor 残差贡献了细节信息,二者结合使用能达到最佳性能。