Command Palette
Search for a command to run...
LLM训练中学习率缩放的非线性研究
LLM训练中学习率缩放的非线性研究
Zaiwen Yang Huaqing Zhang Jing Xu Jingzhao Zhang
摘要
学习率迁移可以降低训练大语言模型的成本:研究人员不必在目标规模上扫描学习率,而是从小规模实验中推断。现有方法通常假设最优学习率在数据规模和模型大小上遵循对数线性缩放定律。我们仔细检验并评估了这一缩放定律。在对参数量从2200万到7.07亿的GPT-2风格模型进行5B到100B tokens训练的实证研究中,最优学习率在较大规模时呈现出向上的曲率,导致外推结果不准确。我们发现,当用有效学习率(归一化权重空间中的步长)替代学习率,并且使用数据量D外推而非模型规模N外推时,这种曲率现象基本消失。接着,我们解释了缩放中的非线性:当最优学习率较小时,权重范数趋于平衡的速度较慢,因此需要更大的步长来缩短瞬态阶段。使用直接控制有效学习率的AdamH进行的实验进一步支持了这一解释。
一句话总结
清华大学和上海期智研究院的研究者发现,在训练 5B 至 100B tokens 的 GPT-2 风格模型(22M 至 707M 参数)时,最优学习率在大规模下出现非线性向上弯曲,导致外推不准确;而当使用有效学习率(归一化权重空间中的步长)并基于数据规模 D 而非模型规模 N 进行外推时,这种弯曲基本消失。他们将其归因于低学习率下权重范数收敛较慢,并且 AdamH 实验进一步支持了这一解释。
核心贡献
- 论文揭示了 GPT-2 风格模型(22M–707M 参数,5B–100B tokens)中最优学习率缩放定律在大规模下呈现向上弯曲,导致从小规模训练外推时系统性地低估最优值。
- 两项改进显著提高了学习率迁移效果:使用有效学习率(归一化权重空间中的步长)进行参数化,以及沿数据轴外推;后者的额外训练算力仅为真正最优学习率所需算力的 2%。
- 提供了这种弯曲现象的机理解释:在 AdamW 下,当最优学习率较小时,权重范数动力学收敛更慢,需要更大的有效步长来缩短瞬态阶段;而直接控制有效学习率的 AdamH 实验进一步支持了该解释。
引言
高效训练大语言模型依赖于精心调整的学习率,但在目标规模上进行网格搜索的代价过高,因此从小规模训练迁移超参数至关重要。先前工作包括最大更新参数化(μP),它在宽度缩放时稳定最优学习率,但当权重范数漂移时可能失效,且不涵盖数据规模的迁移;其他方法则拟合将最优学习率与模型规模和数据规模关联的对数线性缩放定律。然而,这些幂律拟合在外推准确性或拟合成本方面尚未得到严格评估。作者系统研究了跨模型规模和数据规模的学习率迁移,表明对数线性外推会因向上弯曲而低估大规模下的最优学习率,而有效学习率(每步归一化权重方向的变化)则表现出更线性的缩放。他们证明沿数据轴拟合缩放定律比沿模型轴拟合能获得远为准确的预测,并基于 AdamW 权重范数动力学给出了机理解释,且通过一个直接控制有效学习率的优化器进行了验证。
方法
作者研究了大语言模型中学习率的缩放行为,重点关注最优学习率、数据集规模 D 和模型规模 N 之间的关系。他们将最优学习率 η∗(D,N) 定义为:在使用规模为 N 的模型训练 D 个 tokens 后,能使目标损失 L 最小化的值: η∗(D,N):=ηargminL(wT(η;D,N)). 先前工作假设该最优学习率服从对数线性缩放定律: logη∗(D,N)=alogD+blogN+c, 这意味着幂律关系 η∗(D,N)∝DaNb。
为深入理解优化动力学,作者引入了有效学习率的概念。由于 Transformer 等现代架构因归一化层而通常对于权重具有尺度不变性,权重重新缩放后损失保持不变。因此,优化动力学主要取决于权重的方向。有效学习率定义为归一化参数空间中的步长: ηeff(t)=∥w^t+1−w^t∥2, 其中 w^t=wt/∥wt∥2 是归一化权重向量。由于在固定学习率时,有效学习率在训练过程中变化缓慢,因此可以用训练过程中的平均值来近似。于是,最优有效学习率 ηeff∗(D,N) 定义为由最优学习率 η∗(D,N) 引起的平均有效学习率。
作者通过分析隐式有效学习率调度,解释了标准学习率的非线性缩放。他们观察到,对于大训练时长,最优有效学习率的外推比标准学习率更可靠。这是因为由于尺度不变性,优化动力学由有效学习率而非标准学习率决定。
在使用不带权重衰减的 Adam 训练时,有效学习率随时间衰减。对于足够大的学习率,无论初始学习率如何,累积步长都会收敛到同一轨迹,从而导致相似的验证损失。然而,在使用 AdamW 时,权重范数的均衡起着关键作用。权重范数达到均衡所需的时间为有效学习率带来了两个不同的区域。
如下图所示:
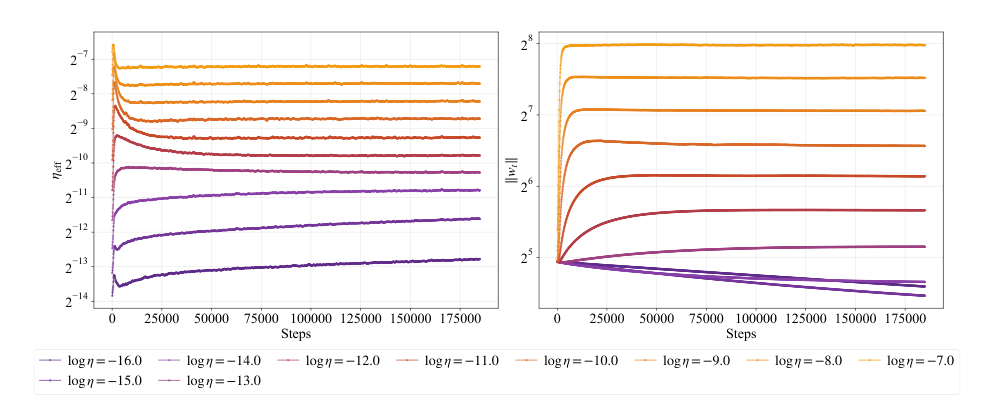
在 AdamW 下,有效学习率表现出两种渐近区域。在均衡区域,即训练时间远大于衰减时间 (2ηλ)−1 时,有效学习率与学习率的平方根成正比(ηeff∝η)。在预均衡区域,即训练时间远小于衰减时间时,有效学习率与学习率成正比(ηeff∝η)。较小的学习率向均衡松弛得更慢,停留在预均衡区域。随着训练时长增加,最优学习率降低,使得训练从均衡区域进入预均衡区域,这就解释了缩放定律中向上弯曲的原因。
为解决标准学习率缩放中的不规则性,作者提出了 AdamH,一种显式控制有效学习率的优化器。AdamH 并非让有效学习率从优化器动力学中隐式产生,而是将权重和更新均归一化到固定的范数。
参见框架图:
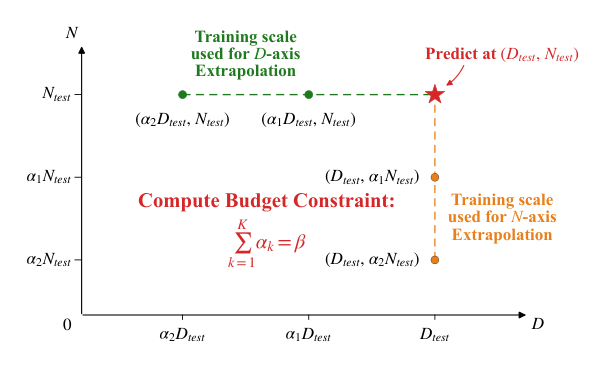
该图展示了用于评估缩放定律的算力受限外推策略。D 轴外推使用全模型配合缩减的数据量,而 N 轴外推使用小模型配合完整数据,两者均在固定算力预算下进行。该框架使作者能够测试不同学习率定义的外推可靠性。
在 AdamH 下,缩放分析恢复出清晰的对数线性关系 logηeff∗∝logD。
如下图所示:
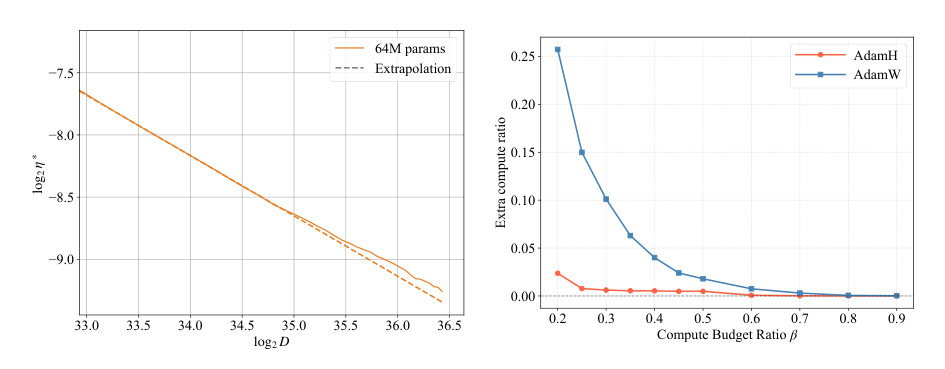
AdamH 展现出清晰的缩放关系,Pearson 系数很高。此外,在比较目标模型和数据集大小所需的额外算力比时,AdamH 在较小算力预算比下实现了比 AdamW 小得多的额外算力比。这表明 AdamH 遵循更线性的缩放定律,使其更适合算力受限的外推。
实验
该研究使用 GPT-2 模型,在不同模型规模和数据预算下评估了最优学习率和有效学习率的对数线性缩放定律。虽然名义学习率表现出系统性的弯曲,但有效学习率遵循更线性的双对数关系,尤其是当沿数据规模而非模型规模缩放时,可得到更可靠的外推。这种非线性源于 AdamW 动力学中的区域转换,且外推误差导致的额外算力成本与预测不准确性呈线性关系。总体而言,沿数据轴预测最优有效学习率可提供最准确且算力效率最高的缩放预测。
沿数据维度拟合有效学习率始终比拟合原始学习率获得更好的外推效果。在 13% 至 21% 的预算比范围内,D 维度有效学习率设置产生的验证损失差距低于 6×10^{-4},额外算力比低于 1.3%,而原始学习率产生的损失差距高出约一个数量级,额外算力比最高达 17%。即使在 20.64% 的预算下,N 维度有效学习率拟合的效果也不如其 D 维度对应方案,突显了使用有效学习率参数化数据轴的价值。D 维度有效学习率拟合使验证损失差距保持在 4.1 至 5.1 ×10^{-4} 之间,而原始学习率拟合则使该差距扩大至 33–66 ×10^{-4}。在所有预算比下,D 维度有效学习率拟合都能将额外算力比最小化,仅需 1.0–1.3% 的额外算力,而原始学习率则需要 8.7–17%。
如下图所示:
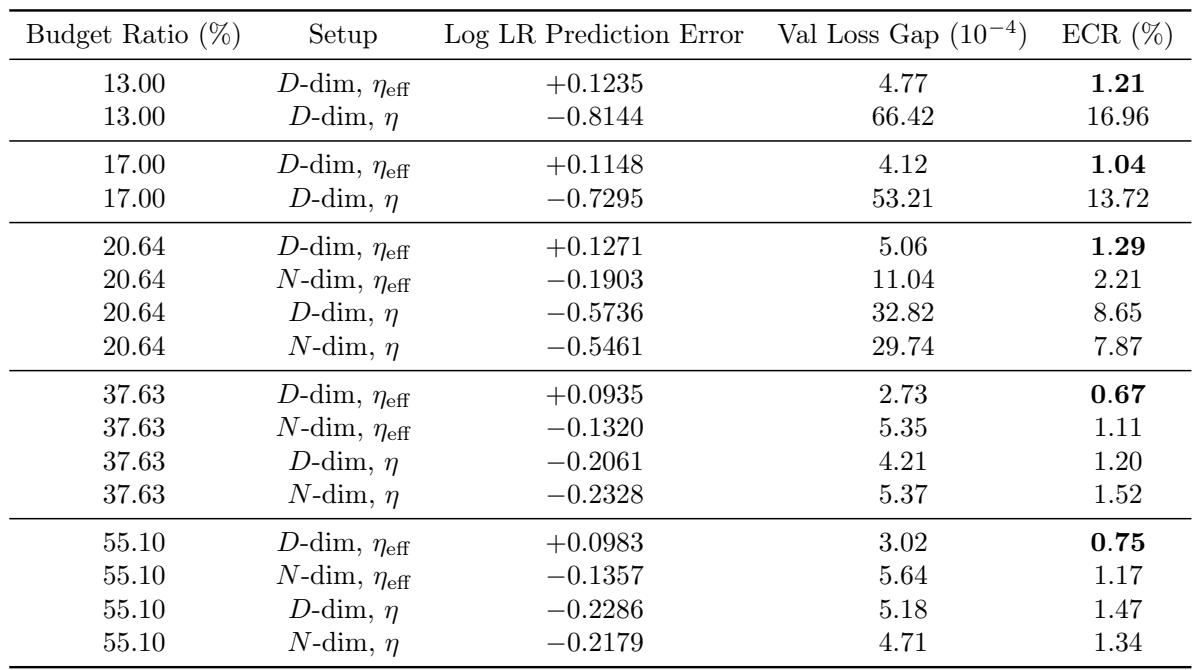
沿数据维度(D 维度)拟合有效学习率,相对于使用原始学习率或 N 维度有效学习率,持续提高了外推效果。在多个预算比下,D 维度参数化产生的验证损失差距小了一个数量级,且仅需要稍多的算力,而原始学习率则带来大得多的损失差距和额外算力开销。这些结果凸显出,使用有效学习率参数化数据轴对准确、高效的缩放定律外推至关重要。