Command Palette
Search for a command to run...
TUA-Bench:面向通用终端使用智能体的基准测试
TUA-Bench:面向通用终端使用智能体的基准测试
Shoufa Chen Luyuan Wang Xuan Yang Zhiheng Liu Yuren Cong Yuanfeng Ji Feiyan Zhou Xiaohui Zhang Fanny Yang Belinda Zeng
摘要
随着大语言模型和集成框架的持续进步,在终端中运行的智能体正日益能够执行超越编码的更广泛的通用计算机使用任务。然而,现有基准测试未能充分评估通用终端计算机使用智能体(TUA):通用计算机使用基准主要针对图形用户界面(GUI),而基于终端的基准则大多强调历史上原生于Shell的技术性和以编程为中心的工作流。我们推出了TUA-Bench,一个面向终端使用智能体的通用基准测试。TUA-Bench包含跨越五个任务家族的120个真实世界任务,涵盖日常数字活动——包括文档编辑、电子邮件管理和实时网络信息检索——以及与博士级领域专家共同设计的、需要专业软件的科学与工程工作流。这一广度使TUA-Bench区别于以往以Shell为中心或特定领域的基准测试。每个任务均经人工设计,在真实终端中运行,并配有确定性设置脚本,通过基于执行的评分协议进行评估。我们发现,最强的尖端智能体——使用Claude Opus 4.8并施加最大推理努力的Claude Code——取得了65.8%的整体性能,在两个赛道中均存在显著差距。通过提供对终端使用能力的广泛且现实的评估,TUA-Bench旨在加速从狭窄、任务特定的助手向能够在多样化数字环境中可靠运行的通用智能体的转变。
一句话总结
来自 Meta AI、杜克大学和斯坦福大学的研究人员提出了 TUA-Bench,一个包含 120 个真实世界终端任务的基准,覆盖日常数字活动与博士级科学工作流,其中表现最佳的 Claude Code 搭配 Claude Opus 4.8 仅达到 65.8% 的成功率,揭示了当前差距,并旨在加速可靠的通用终端使用 agent 的开发。
核心贡献
- TUA-Bench 引入了一个通用基准,包含 120 个人工设计的终端任务,覆盖日常数字活动以及与博士级专家共同开发的特定领域科学/工程工作流。
- 每个任务在真实终端中运行,具有确定性的环境搭建脚本,并通过基于执行的评分协议进行评估。
- 最强的 frontier agent,Claude Code 搭配 Claude Opus 4.8 并启用最大推理努力,总体成功率达到 65.8%,揭示了在可靠终端计算机使用方面两条赛道上的显著差距。
引言
随着大型语言模型发展为执行多步骤数字工作的自主 agent,可靠地评估其计算机使用能力变得至关重要。现有大多数基准依赖图形用户界面,这迫使 agent 处理视觉定位和布局变化,使得难以分离规划与推理能力。同时,命令行界面(CLI)提供了适合语言模型的文本原生交互方式,且已在许多专业工作流中占据核心地位,但之前的 CLI 基准(如 Terminal-Bench)狭隘地聚焦于 shell 编程和技术任务。作者引入了 TUA-Bench,一个包含 120 个人工策划的终端使用任务基准,覆盖日常计算机使用和与领域科学家共同设计的专家工作流,以评估通用 CLI agent。最强的受测 agent 仅达到 65.8% 的成功率,凸显了在长周期规划、工具使用和错误恢复方面的开放挑战。
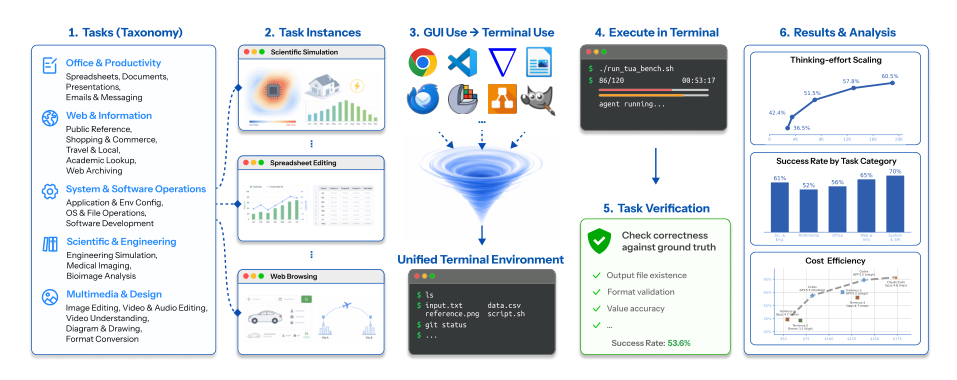
数据集
TUA-Bench 是一个包含 120 个基于终端的任务的基准,旨在评估 agent 在真实计算环境中进行规划、与软件交互和验证结果的能力。任务分为两个互补的组别,覆盖日常工作流和专业化的专业流程。
数据集组成与来源
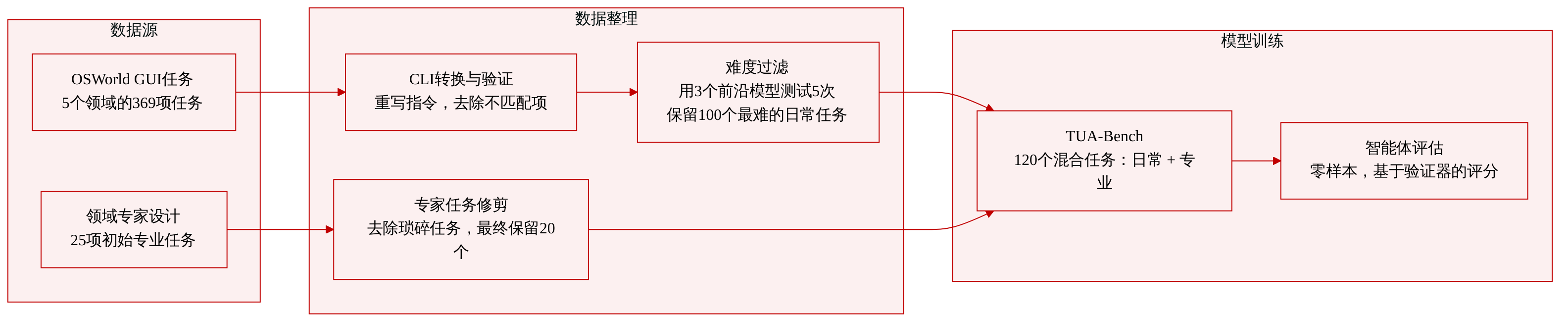
- 日常数字任务(100 个任务): 源自 OSWorld,一个以 GUI 为中心的 369 个任务基准,涵盖网页、办公、多媒体和系统操作。作者通过重写指令以适配命令行使用,将每个 GUI 任务转换为终端原生规范,同时保留原始输入文件和黄金输出构件。转换后,经过人工验证步骤,移除输入文件与黄金构件不一致的任务(例如,幻灯片主题不匹配),确保仅保留可靠的评估项。然后,剩余的候选任务使用三个 frontier 模型(GPT-5.5、Claude Opus 4.7、Gemini 3.1 Pro)在 Terminus-2 agent 框架下进行难度评分,每个任务进行五次试验。保留平均可解性最低(即最具挑战性)的 100 个任务。
- 专业科学任务(20 个任务): 与生物学、医学物理、建筑工程和机械工程领域的博士级专家共同设计。初始的 25 个任务集围绕需要专门软件和领域特定程序知识的真实多步骤工作流构建。每个任务都配有可执行验证器或专家知情的评判标准。移除被多个 agent 轻松解决的任务后,保留 20 个具有挑战性的任务。
任务打包与执行环境 每个任务是一个自包含的软件包,包含 Dockerfile、任务输入文件、自然语言指令、环境变量和一个环境内验证器。基准在 Harbor 上运行,Harbor 是一个编排框架,用于配置隔离的 Linux 容器、管理并行执行、收集轨迹、token 使用情况和分数。这确保了可重现性,同时允许 agent 使用真实文件、shell 命令和可选的互联网访问。
任务分类与统计(图 2) 120 个任务分为五个顶级家族:办公与生产力(38.3%)、网页与信息(18.3%)、系统与软件操作(16.7%)、科学与工程(13.3%)以及多媒体与设计(13.3%)。这些家族进一步细分为 20 个子类别,涵盖电子表格编辑、电子邮件管理、工程仿真、医学成像、软件配置等。
基准使用方法 TUA-Bench 是一个评估套件,而非训练数据集。作者用它来测量 agent 在开放式计算机使用任务上的性能。Agent 在 Harbor 环境中以零样本的方式进行评估,其成功与否由任务验证器决定。该基准的难度感知策展和日常/专业混合组成,旨在为评估跨异构真实世界工作流的规划、工具选择和验证能力提供一项长期挑战。
方法
作者通过一个有原则的、双管齐下的策展策略,并辅以标准化的执行层,构建了 TUA-Bench。该方法论涵盖环境打包、任务转换、质量筛选和难度驱动的过滤,确保了一个可重现且具有挑战性的终端 agent 评估基准。
评估基础设施构建于 Harbor 之上,这与 Terminal-Bench 使用的编排框架相同。Harbor 管理一次试验的完整生命周期:任务配置、容器化环境设置、并行执行、以及轨迹、token 使用量、分数和运行时元数据的收集。每个任务在隔离的、可重置的 Linux 容器中运行,因此失败或不安全的执行不会污染后续运行。除 Docker 外,还支持 Podman 以在共享集群上进行无 root 权限的执行。这一底层允许 agent 在包含文件、软件包、可选互联网访问和原生 CLI 基础 agent 接口的真实终端环境中运行。
每个任务被打包为一个自包含的单元,包含 Dockerfile、输入构件、自然语言指令、环境变量、模型和运行时设置,以及一个环境内验证器。这种打包方式固定了初始状态、执行过程和评估协议,提供了一致且可重现的比较,同时仍允许随机的 agent 行为和在启用网络时的互联网依赖性变化。
任务策展沿两个正交维度进行:广度,捕捉日常数字工作(网页浏览、文档编辑、电子邮件、媒体处理);深度,针对与生物学、医学物理、建筑工程和机械工程领域的博士级专家共同设计的专家工作流。这两条赛道遵循不同的设计流程。
对于日常任务,作者从 OSWorld 开始,这是一个包含 369 个真实计算机使用任务的基于 GUI 的基准。他们通过保留底层意图但剥离特定于应用程序的假设,将每个任务转换为以 CLI 为中心的表述。输入文件和黄金构件规范保留自 OSWorld,而指令被重写为自然且可从终端执行。至关重要的是,agent 不被强制使用原始的 GUI 应用程序;它们可以选择任何命令行工具、实用程序或工作流来达成目标。
此转换之后是两个质量控制阶段。首先,人工验证检查失败的执行轨迹和 agent 产生的构件,识别出失败源于输入与黄金标准不一致而非 agent 缺陷的任务(例如,演示任务中幻灯片主题不匹配)。任何经核实存在差异的任务都会被移除。其次,应用难度感知的选择程序:每个剩余候选任务使用三个 frontier 模型(GPT-5.5、Claude Opus 4.7 和 Gemini 3.1 Pro)进行评估,每个模型均在 Terminus-2 agent 框架内运行。对于每个模型-任务对,进行五次独立试验,并记录平均奖励作为经验可解性分数。任务按总体可解性排序,并保留 100 个最难的任务。这确保了即使基础模型持续改进,基准也能抵抗饱和,保持长期的区分力。
深度赛道遵循与领域专家互补的共同设计方法,尽管其详细构建是独立的;它强调真实的程序、领域特定的约束,以及直接为终端 agent 交互制作的可执行评估。两条赛道共同产生了包含 120 个任务的基准,所有任务均为基于 Harbor 的执行环境统一打包,已准备好进行大规模 agent 评估。
实验
论文在 TUA‑Bench 上评估了五个基于终端的 agent 框架,并搭配了广泛的 frontier 和开放模型,测量了基于执行的成功率和多次试验的可靠性。该基准清楚地区分了能力层级:最强的模型实现了较高的平均成功率,然而 scaffold 的选择可能逆转模型排名,且可靠、一致的性能仍然具有挑战性。更长的任务时间限制和增加推理努力均能提高成功率,但收益递减,而成本效率分析显示,使用轻量级 scaffold 和开放权重模型可以以低成本提供有竞争力的结果。类别级别的性能差异很大,特定的困难任务抵抗了所有测试系统,表明未来的进展需要解决这些困难案例,而非仅仅提高整体平均值。
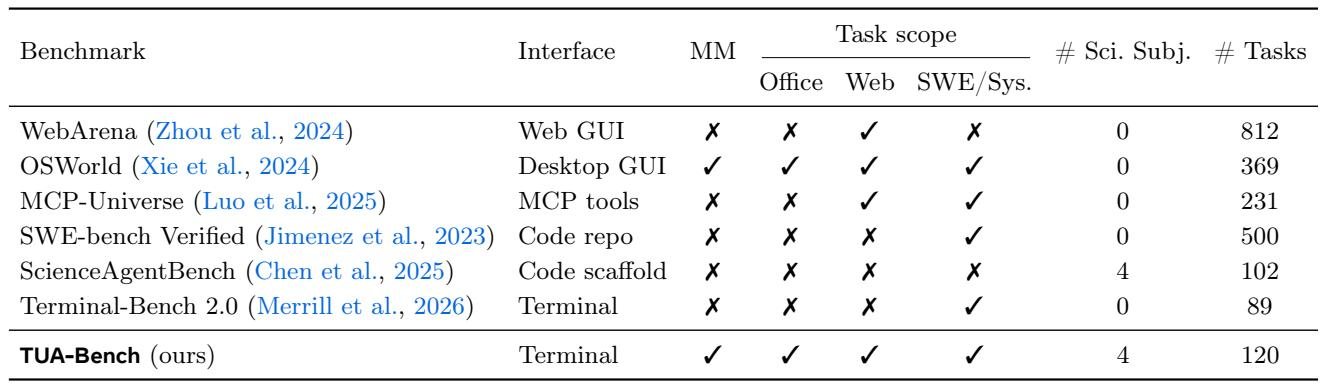
现有基准揭示了一个明显的分裂:具有广泛任务覆盖(涵盖办公、网页和系统操作)的工具构建于图形界面上,而命令行基准仍然局限于软件和系统任务。没有基于终端的基准提供办公或网页任务评估,这凸显了一个缺口,即日常计算机使用的文本原生交互未被评估。OSWorld 是唯一覆盖办公、网页和系统任务的基准,并通过桌面 GUI 运行。所有列出的终端(或代码仓库)基准,如 Terminal-Bench 2.0 和 SWE-bench Verified,均缺乏办公和网页任务覆盖,仅专注于软件或系统挑战。
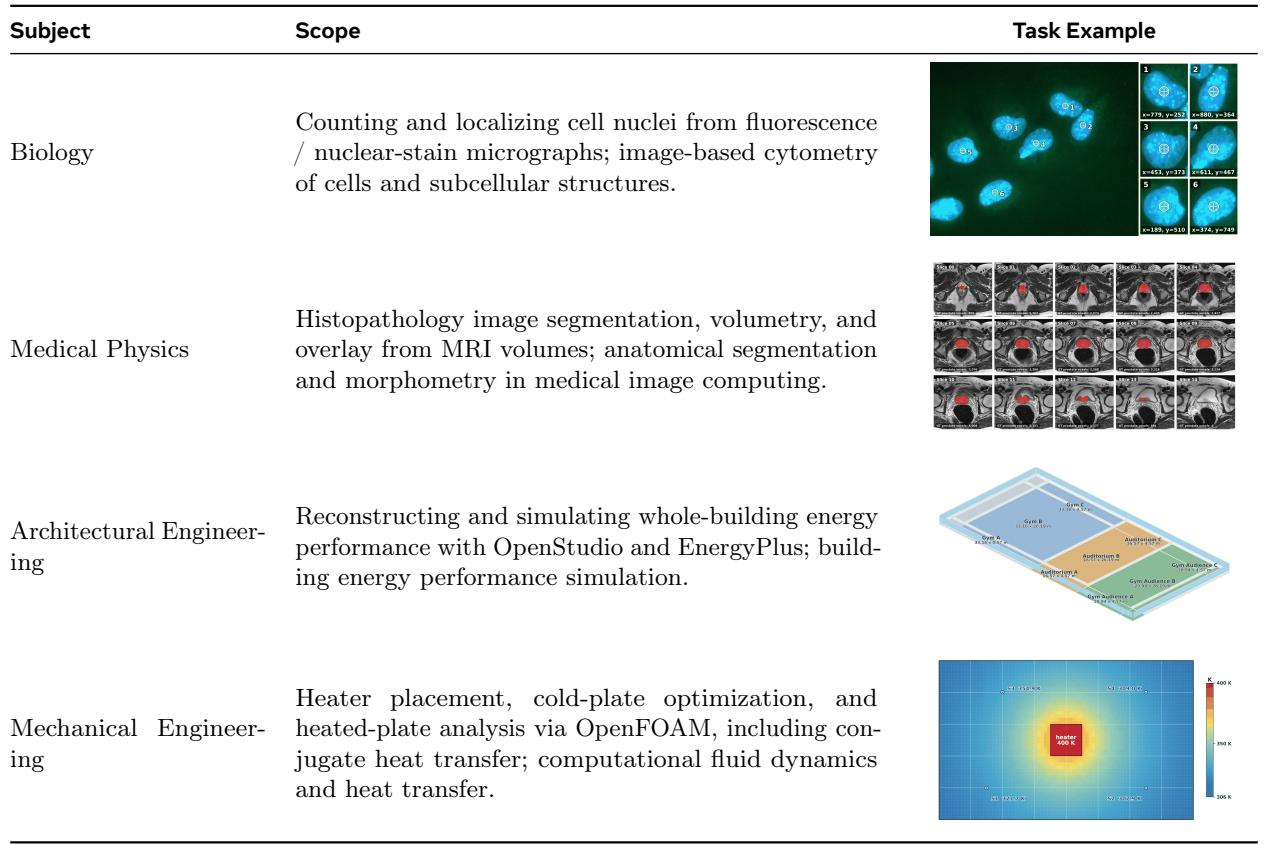
该基准涵盖四个科学和工程领域——生物学、医学物理、建筑工程和机械工程——每个领域都有不同的任务范围。任务范围从基于图像的细胞计数和组织病理学分割,到全建筑能耗模拟和计算流体动力学,代表了真实世界的工作流。这种多样性为评估 AI agent 在实用科学任务上的表现提供了一个广泛的测试平台。生物学任务侧重于从荧光和核染色显微照片中计数和定位细胞核,包括细胞和亚细胞结构的基于图像的细胞计数。建筑工程涉及使用 OpenStudio 和 EnergyPlus 重建和模拟全建筑能耗性能。
将 agent scaffold 固定为 Terminus-2,排名前三的模型(GPT-5.5、Claude Opus 4.8 和 Claude Opus 4.7)的平均成功率在 58-60% 的狭窄区间内,但 Claude Opus 4.8 明显更一致,在 42.5% 的任务上成功解决了所有五次尝试,而 GPT-5.5 为 31.7%。Claude 家族内部呈现清晰的能力层级,从 Opus 4.8(59.7%)下降到 Haiku 4.5(23.9%)。当每个 agent 与其最佳模型配对时,Claude Code 搭配 Claude Opus 4.8 达到 65.8%,而领先的 scaffold 均落在 5.7 个百分点的区间内,表明强大的 frontier 模型可以在不同的 agent 实现中提供有竞争力的结果。在 Terminus-2 scaffold 上,GPT-5.5 和 Claude Opus 4.8 的平均成功率几乎持平,但 Opus 4.8 在 42.5% 的任务上解决了所有五次种子试验,显著优于 GPT-5.5 的 31.7% 全五次成功率。最佳的 agent-模型组合,Claude Code 搭配 Claude Opus 4.8,实现了 65.8% 的成功率,仅比基础 Terminus-2 搭配 GPT-5.5 高出 5.7 个百分点,表明 agent scaffold 调优提供了适度但有意义的优势。
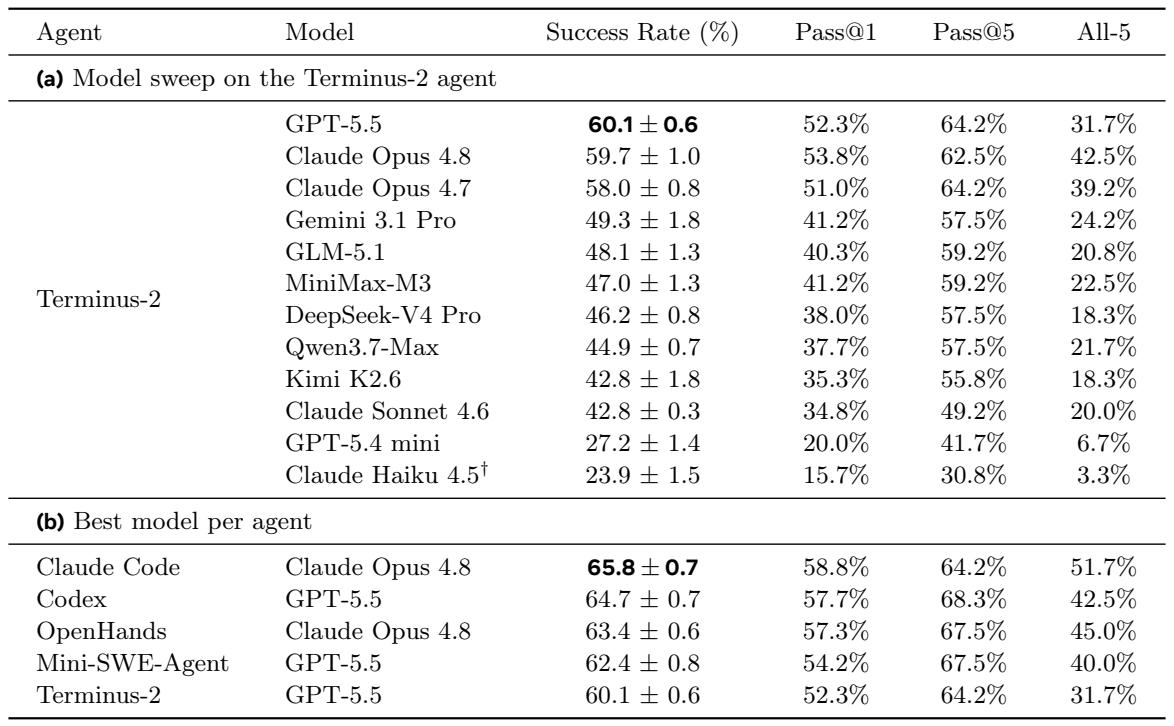
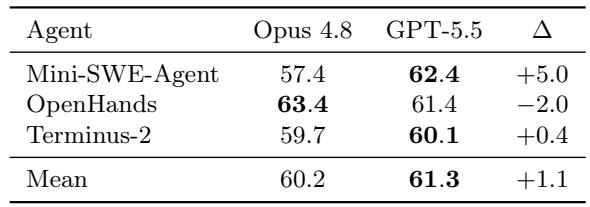
当在三个开源 agent scaffold 上取平均值时,GPT-5.5 和 Claude Opus 4.8 实现了相似的成功率(61.3% 对 60.2%),但这个微小的差距隐藏了巨大的 scaffold 依赖性差异。GPT-5.5 在 Mini-SWE-Agent 上领先 5 个百分点,而 Opus 4.8 在 OpenHands 上领先 2 个百分点,两者在 Terminus-2 下几乎持平,证明了相对模型性能并非对 agent 框架保持不变。GPT-5.5 和 Claude Opus 4.8 的排名取决于 agent scaffold,每个模型在不同的框架上表现最佳。在 Terminus-2 下,两个模型实际上持平,仅相差 0.4 个百分点。Agent scaffold 的选择可能产生与底层模型选择相当的影响,因此单 scaffold 比较可能错误地表示相对模型能力。
一个新的基于终端的基准填补了办公和网页任务的评估空白,同时也覆盖了多样化的科学领域,如生物学和建筑工程。实验表明,领先模型实现了相似的平均成功率,但在一致性上存在差异,并且 agent scaffold 的选择可以改变模型排名,表明这两个组件都显著影响能力评估。