Command Palette
Search for a command to run...
Dockerless:面向编程智能体的免环境程序验证器
Dockerless:面向编程智能体的免环境程序验证器
摘要
程序验证器在编程智能体训练中扮演核心角色,包括为监督微调选择轨迹以及为强化学习提供奖励。标准的基于执行的验证需要在诸如Docker镜像等特定于仓库的环境中运行单元测试,这会带来巨大的环境搭建成本。我们提出Dockerless,一种免环境的智能体式补丁验证器,能够在不执行生成代码补丁的情况下对其进行评估。Dockerless并非简单地将候选补丁与参考答案进行匹配,而是利用通过智能体式仓库探索所获取的证据来判断补丁的正确性。在验证器评估基准上,Dockerless比最强的开源验证器高出14.3个AUC点。将Dockerless同时用作监督微调轨迹过滤器和强化学习奖励,能够实现完全免环境的后训练流程。最终得到的模型在SWE-bench Verified、Multilingual和Pro上的解决率分别达到62.0%、50.0%和35.2%。它比Qwen3.5-9B基线分别高出2.4、8.7和2.9个百分点,与基于环境的后训练效果相当。
一句话总结
上海交通大学与抖音集团的研究人员提出 Dockerless,一种无需环境的补丁验证器,借助 Agent 式仓库探索在无需执行代码的情况下评估代码正确性,在 AUC 指标上比当前最佳的开源验证器高出 14.3 分,并实现了一条完全无需环境的后训练管线,将 Qwen3.5-9B 编程 agent 在 SWE-bench Verified、Multilingual 和 Pro 上的解决率分别提升至 62.0%、50.0% 和 35.2%,相较于基线模型分别超出 2.4、8.7 和 2.9 分,并达到与基于环境的后训练相当的性能。
核心贡献
- Dockerless 是一种无需环境的 Agent 式验证器,通过真实的工具调用主动探索代码仓库来判断补丁的正确性,并在验证器基准测试上以 14.3 AUC 分的优势超越最强的开源验证器。
- Dockerless 既能作为监督微调的轨迹过滤器,也能作为强化学习的奖励信号,从而构建起一条完全无需环境的后训练管线。
- 最终得到的模型在 SWE-bench Verified、Multilingual 和 Pro 上分别取得 62.0%、50.0% 和 35.2% 的解决率,相较 Qwen3.5-9B 基线模型分别提升 2.4、8.7 和 2.9 分,并达到与基于环境的后训练相当的性能。
引言
自动化编程 agent 依赖验证器来判断补丁是否解决了一项任务,从而为监督微调和强化学习提供正确性反馈。基于执行的验证是行业金标准,但需要为每个代码仓库构建带有特定依赖和测试套件的 Docker 环境,然而这种方法在私有、遗留或测试用例稀少的代码库上常常难以实施,并且会带来沉重的工程开销。此前的无环境验证器试图通过从共享基础镜像对补丁评分来降低搭建成本,但这些方法仅依赖浅层的文本或 diff 信号,而没有深入检查代码仓库本身,因此在需要理解调用图和模块集成的复杂功能等价性检查中不可靠。作者通过提出 Dockerless 来解决这些局限,这是一种 Agent 式验证器,通过生成验证问题并派遣子 agent 收集仓库证据来主动探索实际代码库,从而在构建起一条完全无需环境的后训练管线的同时,匹配基于执行方法的准确性。
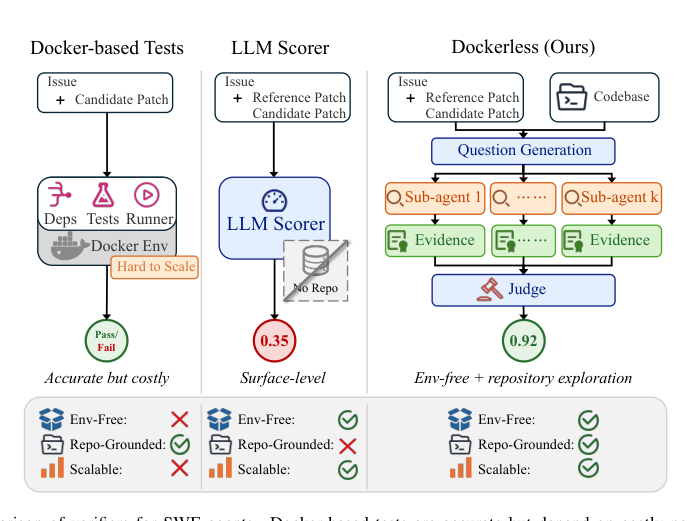
方法
作者为应对软件工程后训练中的可扩展性瓶颈,引入了一种无需环境的验证器 Dockerless,用一个学习得到的模型 rϕ(x,y) 取代了昂贵的仓库级测试执行流程。
如下图所示,Dockerless 的架构分为两个彼此独立的阶段,从而将其判断建立在仓库探索的基础上,而非浅层的补丁对比。
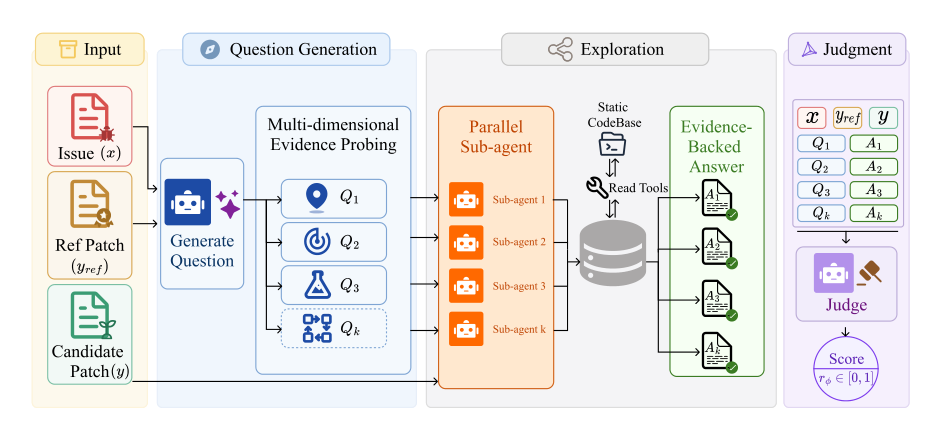
首先,给定一个问题 x 和一个参考补丁 yref,模型会生成一组共 K 个验证问题 {Q1,…,QK},这些问题探究修复应作用于何处、代码应具备何种行为以及可能存在的破坏。然后,并行运行的子 agent 使用只读 shell 工具探索静态代码库,并返回有证据支持的答案 Ak。在第二阶段,模型汇总问题、补丁以及收集到的 (Qk,Ak) 对,并输出一个二元判决 token,取值范围为 {0,1}。在推理阶段,连续的正确性分数通过计算这些 token 的 logits ℓ0 和 ℓ1 得出:
rϕ(x,y)=exp(ℓ0)+exp(ℓ1)exp(ℓ1)
为了训练这一验证器,作者对带有执行标签的候选补丁采用了拒绝采样管线。
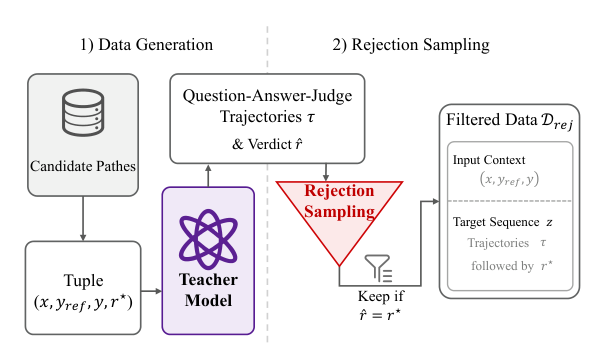
一个教师模型为每个元组 (x,yref,y,r⋆) 生成完整的“问题—回答—判决”轨迹 τ,其中 r⋆ 是根据留出的单元测试得到的真实判决。该管线仅保留教师模型预测判决 r^ 与 r⋆ 一致的轨迹,从而构建出过滤后的数据集 Drej。为缓解类别不平衡问题,负样本与正样本的比例被限制在 ρ 以内。然后,验证器在全输出序列 z 上使用标准的下一个 token 交叉熵损失进行端到端训练:
Lϕ=−EDrej[∑t=1Tlogpϕ(zt∣x,yref,y,z<t)]
训练完成后,Dockerless 被集成到无需环境的后训练管线中,在不依赖各仓库环境的情况下完成数据筛选和奖励计算。
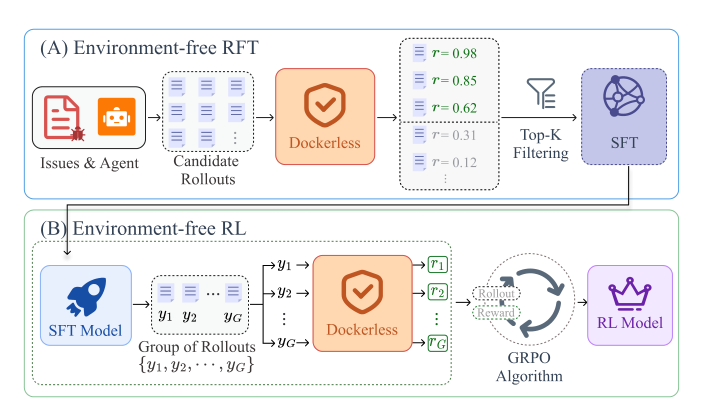
对于无环境的拒绝采样微调,作者在一个最小化的 Linux 镜像中收集了大规模的 agent 轨迹。Dockerless 对每条轨迹的最终补丁进行评分,并根据 rϕ 得分选择 top-K 的轨迹构成 DRFT,用于标准的 SFT 训练。对于无环境的强化学习,Dockerless 在 SFT 模型之上充当奖励模型。同样在最小化环境中收集轨迹,验证器对每条最终补丁 yi 进行评分。这些分数被用于为 GRPO 目标计算组归一化优势:
Ai=σ^rrϕ(x,yi)−rˉ,rˉ=G1∑j=1Grϕ(x,yj)
其中 σ^r 是一组 G 条轨迹内奖励的标准差。为进一步稳定奖励信号,每个奖励均通过对同一补丁进行 M 次独立的 Dockerless 评估后取平均计算得到。
实验
评估设置对比了在 SWE-bench 基准上对 Qwen3.5-9B agent 进行无环境 SFT 和 RL 训练的结果,并将其与基于环境的训练以及开源专业模型进行对照。关键发现表明,基于拒绝采样轨迹训练的自定义验证器能有效过滤噪声轨迹,并提供几乎与实际测试执行相匹配的奖励,使得完全无环境的后训练能够达到顶级的开源性能。验证器的 Agent 式探索带来了强大的辨别能力,并且只增加了极少的延迟,使可扩展的无环境 agent 训练成为现实。
一条完全无需环境的后训练管线在 SWE-bench 基准上取得了最先进的开源结果,同时超越了基础模型和此前的专业模型。无环境 SFT 与基于环境的 SFT 性能相当,而无环境 RL 则逼近测试执行 RL 的表现,并优于基于验证器奖励的方法,同时因 Agent 式奖励计算带来的额外延迟可忽略不计。无环境模型 Dockerless-RL-9B 相较 Qwen3.5-9B 基础模型有显著提升,其中在 Multilingual 分割上的相对增益最大。在 SFT 数据筛选中去除按仓库执行环境的依赖后,其在全部三个 SWE-bench 分割上的性能与基于环境的 SFT 不相上下。使用 Dockerless 奖励的无环境 RL 取得了接近理想测试执行 RL 的结果,并明显优于 DeepSWE Verifier 奖励方案。与 agent 轨迹生成相比,Agent 式验证所增加的时间仅占总单条轨迹时间的一小部分,使得额外开销在 RL 训练中几乎可以忽略。
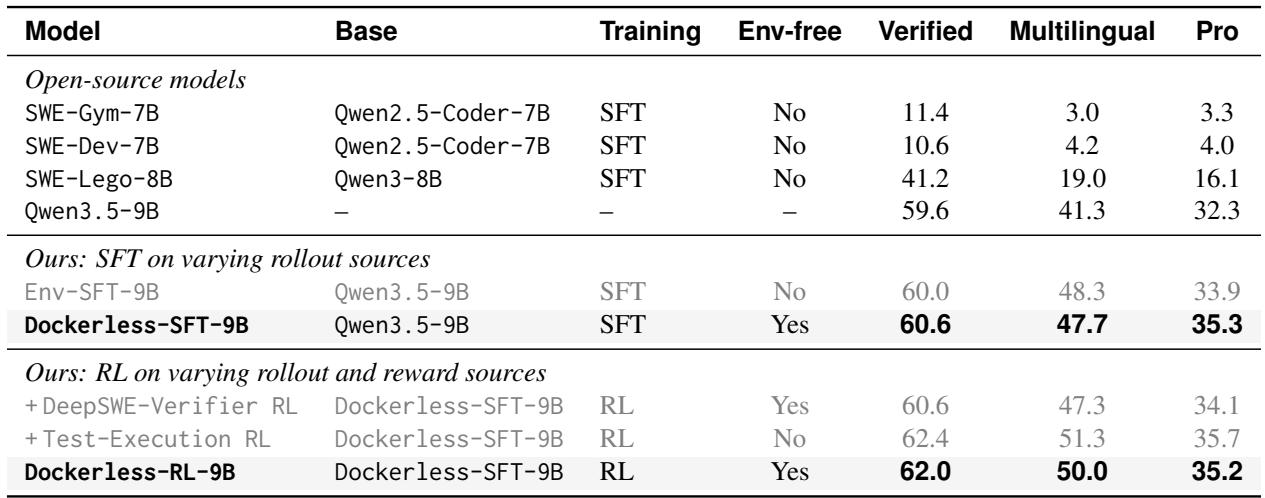
Dockerless 在两个评估分割上均取得了最高的验证器 AUC,超越了前沿的大语言模型评判器和训练后的开源验证器。其使用少量验证问题进行的 Agent 式探索提升了补丁判断准确率,但扩大问题数量至四个以上时,性能提升趋于平稳甚至出现波动,因此选择在推理时使用两到四个问题以平衡准确率与开销。尽管奖励评估时间较长,但额外延迟在 RL 轨迹总时间中所占比例很小。Dockerless 在 Verified 分割上取得了 81.0 AUC,在 Multi-SWE-bench Flash 分割上取得了 72.1 AUC,优于所有基线。随着验证问题从零个增加到四个,AUC 从 78.3 提升至 81.0,但超过该阈值后性能停滞或下降。基于 Dockerless 的奖励评估仅使每条轨迹的总挂钟时间增加 7.2%,因此相对于 agent 轨迹生成,探索开销是较低的。
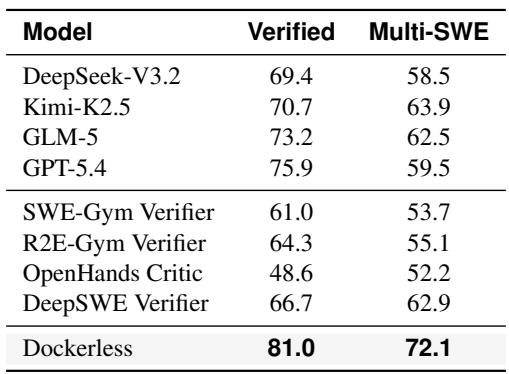
对所有未经过滤的无环境轨迹进行监督微调,结果相较于基础模型要么性能下降,要么没有提升,这表明不能直接使用原始轨迹。使用 Dockerless 过滤轨迹后,其性能可与基于环境的数据相媲美,且显著优于随机选择,这验证了其轨迹质量筛选的有效性。使用全部 16K 条未过滤轨迹并未提高解决率,甚至在某些基准上略有下降。Dockerless 4K 在所有基准上都以明显优势胜过 Random 4K,表明 Dockerless 验证器相比均匀采样能提供更好的选择信号。Dockerless 4K 在三个基准上的表现均与 Env-based 4K 相当,这说明无环境轨迹收集结合强有力的过滤机制,可以取代为每个仓库单独搭建环境的流程。
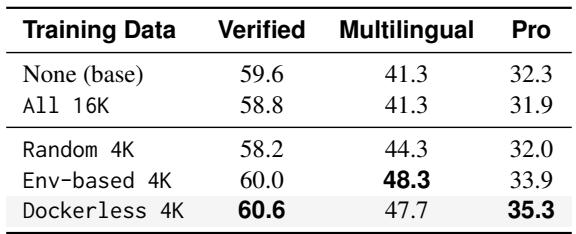
在 SWE-bench 基准上对一条完全无环境的后训练管线进行了评估,结果表明,无环境 SFT 可媲美基于环境的 SFT,而无环境 RL 的性能接近理想测试执行 RL,同时 Agent 式奖励计算在轨迹总挂钟时间中仅增加了极小的一部分。使用 Dockerless 验证器过滤 SFT 轨迹是至关重要的,能获得与基于环境的数据相当的性能,并远远优于随机选择。Dockerless 验证器也取得了最高的验证器 AUC,且通过少量验证问题即可提升补丁判断准确率,而整体管线相较基础模型有显著改善,尤其在多语言分割上提升明显。