Command Palette
Search for a command to run...
PhysisForcing: 用于机器人操作的物理增强世界模拟器
PhysisForcing: 用于机器人操作的物理增强世界模拟器
摘要
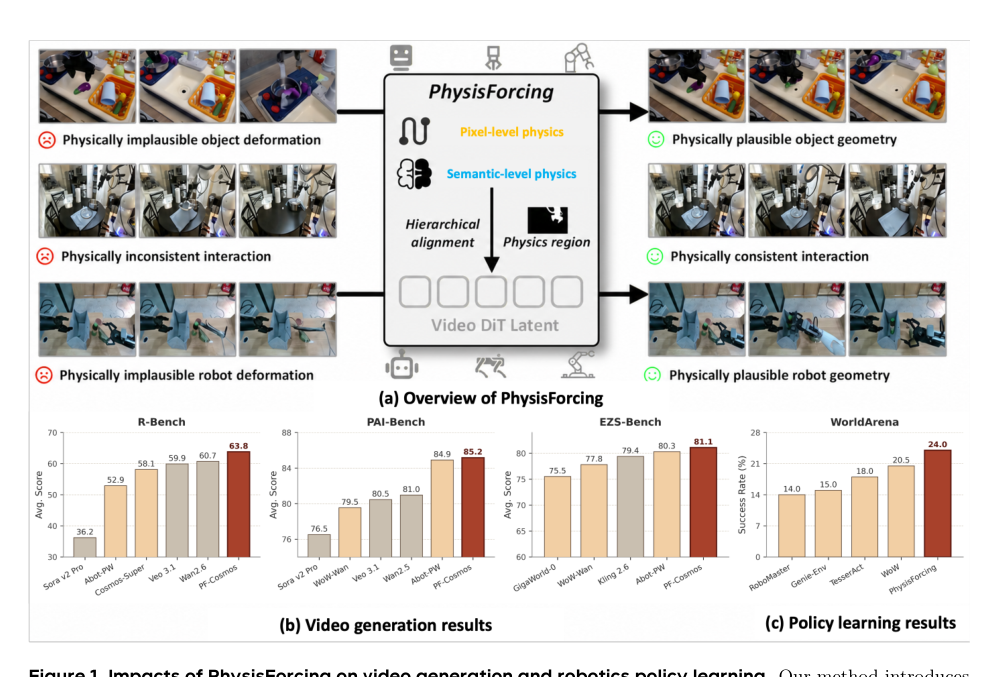
视频生成模型已成为具身世界模拟的一个有前景的范式。然而,无论是通用领域的视频生成器还是经过机器人特定数据微调的模型,仍可能产生物理上不可行的操作,包括不连续的运动轨迹和不一致的机器人-物体交互,这限制了它们作为世界模拟器的可靠性。通过大量实验,我们发现此类物理不稳定性主要源于两个因素:运动物体的形变以及交互实体间不合理的时空关联,尤其是在接触期间。基于这一观察,我们提出了 PhysisForcing,一个可扩展的训练框架,通过对物理信息区域进行重点监督,联合优化像素级和语义级特征,来增强物理一致性。该框架包含一个像素级轨迹对齐损失,利用参考点轨迹监督 DiT 特征;以及一个语义级关系对齐损失,将 DiT 特征与从冻结视频理解编码器中提取的区域间关系对齐。在 R-Bench、PAI-Bench 和 EZS-Bench 上的大量实验表明,PhysisForcing 在强大基线上持续提升具身视频生成性能,将 Wan2.2-I2V-A14B 和 Cosmos3-Nano 基模型在 R-Bench 上的性能分别提高了 22.3% 和 9.2%(相较于普通微调分别提高了 7.1% 和 3.7%),其中 Cosmos3-Nano 变体取得了最佳综合得分。除了生成之外,作为世界模型,在 WorldArena 动作规划协议下,它将闭环成功率从 16.0% 提升至 24.0%,并进一步提高了下游策略成功率,表明具有物理对齐的视频模型能为机器人操作提供更强的表征。代码及更多结果见 https://dagroup-pku.github.io/PhysisForcing.github.io/。
一句话总结
北京大学和英伟达的研究人员提出 PhysisForcing,一个在机器人操控的视频世界模拟器中强化物理一致性的训练框架,通过联合优化像素级轨迹对齐和语义级关系对齐损失,提升生成基准表现,包括在 R-Bench 上取得 +22.3% 的提升,并将闭环操控成功率从 16.0% 提高到 24.0%。
核心贡献
- PhysisForcing 是一个训练框架,通过在交互关键区域上联合优化像素级轨迹对齐损失和语义级关系对齐损失,在视频生成中强制执行物理一致性。
- 在 R-Bench、PAI-Bench 和 EZS-Bench 上的实验表明,PhysisForcing 能持续改善具身视频生成,在 R-Bench 上相对基线模型,Wan2.2-I2V-A14B 提升 22.3%,Cosmos3-Nano 提升 9.2%,并且 Cosmos3Nano 变体取得了最佳综合得分。
- 在 WorldArena 协议中作为世界模型使用时,PhysisForcing 将闭环操控成功率从 16.0% 提高到 24.0%,并改善下游策略成功率,证明物理对齐的视频生成为机器人操控产生更强的表征。
引言
视频生成模型作为具身智能的世界模拟器具有前景,能够实现机器人操控中可扩展的数据生成和策略学习。然而,这些模型常产生物理上不合理的动态,如物体穿透或不连续的运动,尤其是在接触密集型任务中。先前的方法要么缺乏对操控数据的充分接触,要么在训练时对所有像素一视同仁,或仅施加单一层次的、事后的物理约束,忽略了物理合理性的层次化本质。作者提出 PhysisForcing,一个区域聚焦、层次化对齐的框架,在训练过程中识别交互关键区域,并施加两个互补的损失:用于局部运动一致性的像素级点轨迹损失,以及用于正确全局物体交互的语义级token相似度对齐损失。
方法
作者提出 PhysisForcing,一种通过区域聚焦的层次化对齐框架将物理监督注入视频生成的方法。如下图所示:
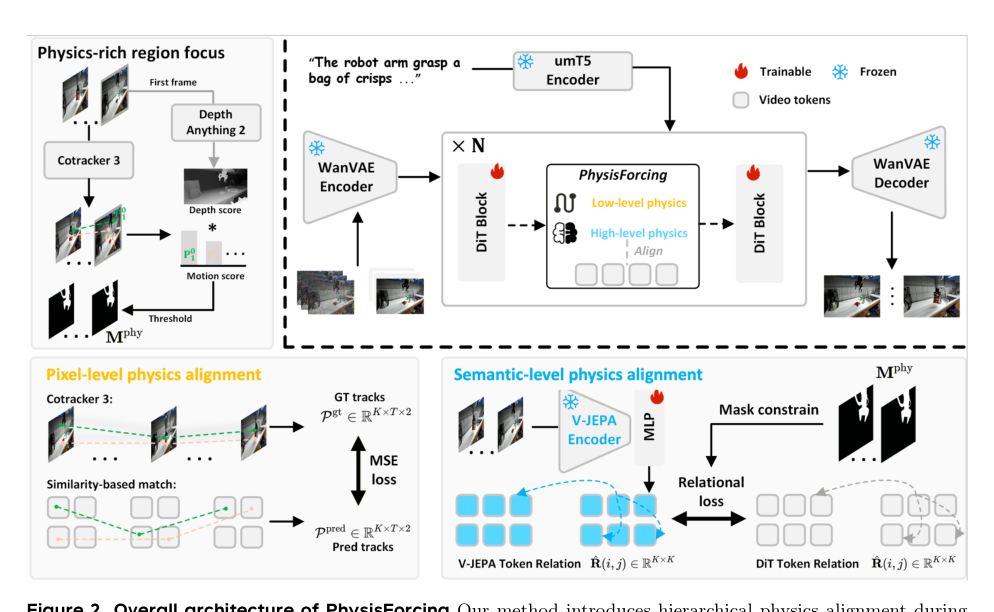
该流程首先识别机器人-物体交互发生的物理信息区域,随后施加两个互补的训练信号:用于局部运动一致性的像素级轨迹对齐和用于交互结果一致性的语义级关系对齐。
为了定位这些交互丰富的区域,作者首先利用现成的点跟踪器从输入视频 V∈RT×C×H×W 中提取密集的时间轨迹。计算每条轨迹的运动幅度 ai,注意到较大的局部运动通常指示接触密集的区域。然而,为了滤除背景抖动,引入了一个源自第一帧估计深度图 D0 的深度感知前景权重 ri。通过将运动幅度与此前景权重结合,为每条轨迹计算物理信息分数 qi=ai⋅ri。然后,基于平均分数的自适应阈值被用来生成轨迹级运动掩码,该掩码随后被投影到每一帧,形成时空物理掩码 Mphy。此掩码为后续的物理监督步骤提供空间引导。
对于像素级物理对齐,作者在机械臂和被操控物体上强制逐点轨迹连续性。从去噪Transformer (DiT) 的中间块提取隐藏特征 Hl,并使用轻量级 MLP ϕ(⋅) 对其进行精炼。精炼后的特征被重排为逐帧特征图 F^。以第一帧特征作为查询 Q=F^0,其余帧作为键 Kt=F^t,为每个查询点计算相似度图 sit。通过归一化此图并计算坐标期望,得到每一帧的预测点位置 p^it。然后,利用从真值视频中提取的参考轨迹,通过施加在先前识别的物理信息区域上的掩码均方误差损失 Lpixphy,监督这些预测轨迹。
虽然像素级对齐约束了点级运动,但操控合理性还依赖于不同区域之间的关系动态。为捕捉这一点,作者引入语义级物理对齐。利用一个冻结的自监督视频理解编码器从输入视频中提取目标表征 Fu。同时,使用另一个轻量级 MLP ψ(⋅) 将同一 DiT 中间块的隐藏特征投影到编码器表征空间,并调整其尺寸以匹配编码器的时空token布局 F^u。调整物理信息掩码的尺寸以从两种表征中选择对应的时空token。然后,为 DiT 侧和编码器侧的token计算成对关系矩阵 R^ 和 R,捕获选定的物理信息token之间的时空关系。语义级对齐损失定义为这两个关系矩阵之间的 L1 距离:
Lsemphy=K21∑i=1K∑j=1KR^(i,j)−R(i,j)
这有效地将编码器的关系结构迁移到 DiT 中。
PhysisForcing 在预训练的基于 DiT 的视频生成骨干网络微调期间应用。整体训练目标将标准的流匹配损失与像素级和语义级物理损失相结合:
L=LFM+λpixLpixphy+λsemLsemphy
所有辅助模型,包括点跟踪器、深度估计器和视频理解编码器,仅在训练期间使用,并在推理时丢弃,确保该方法在视频生成期间不引入额外的计算开销。
实验
在三个具身视频生成基准上的实验表明,PhysisForcing 改善了多个骨干网络,产生更物理合理的视频,并超越了强有力的基线。增强后的世界模型还提高了接触密集型任务上策略学习的成功率。消融实验验证了像素损失和语义损失是互补的,专注于交互的监督驱动了增益,并且中间块对齐层是最优的。
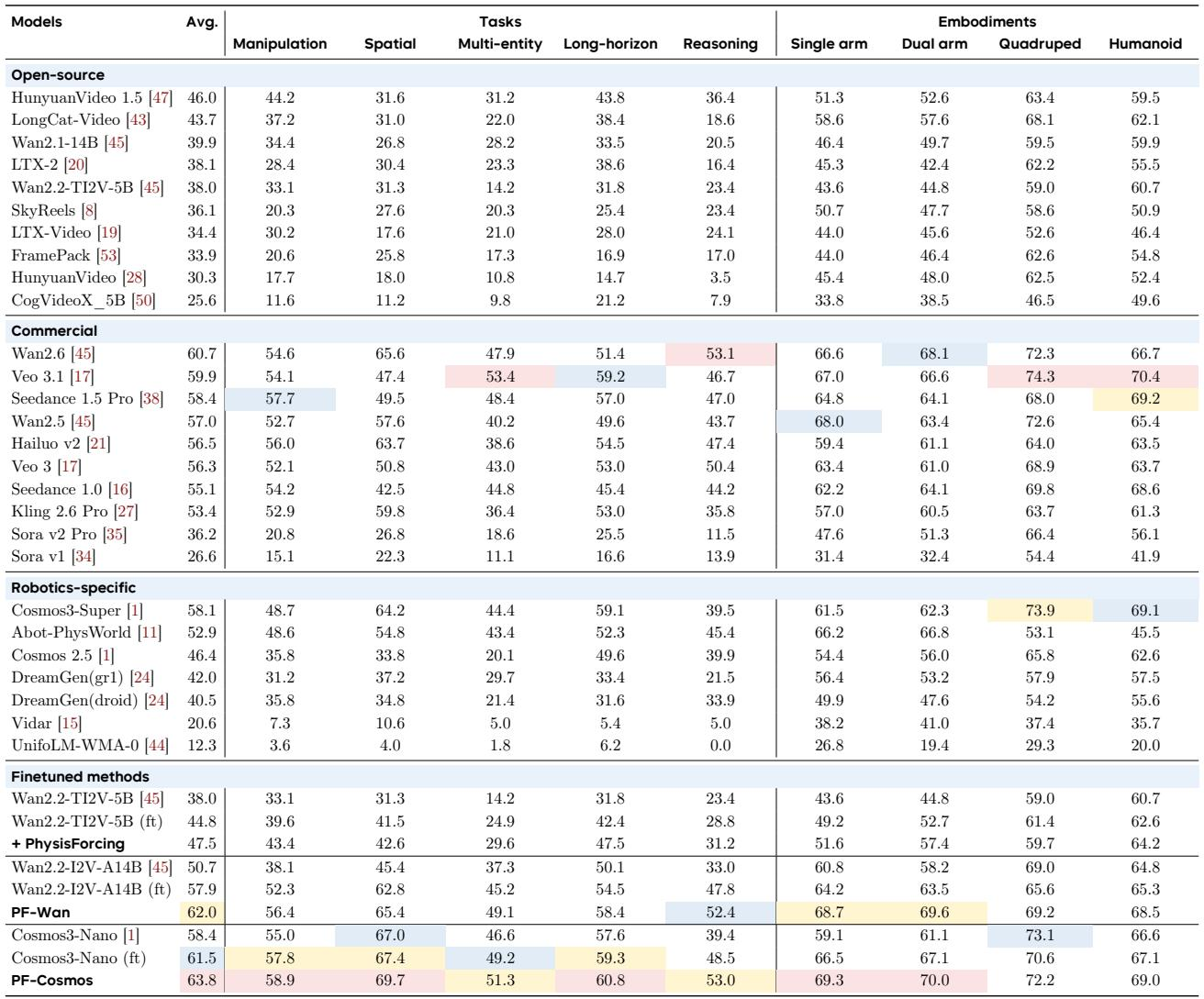
PhysisForcing 大幅提升了 R-Bench 上的视频生成性能,PF-Cosmos 取得了最高的总体平均分(63.8),PF-Wan 紧随其后(62.0),两者均超越了最佳的商业和开源基线。在没有使用 PhysisForcing 的骨干模型中,开源模型仅获得中等分数,其中 HunyuanVideo 1.5 以 46.0 的平均分领先。PF-Cosmos 取得了 63.8 的最高总体平均分,超越了最强的商业模型 Wan2.6(60.7)以及所有开源模型。PhysisForcing 将 Wan 骨干网络提升了 22.3%(达到 62.0),而未使用该方法时得分最高的开源模型 HunyuanVideo 1.5 仅达到 46.0。
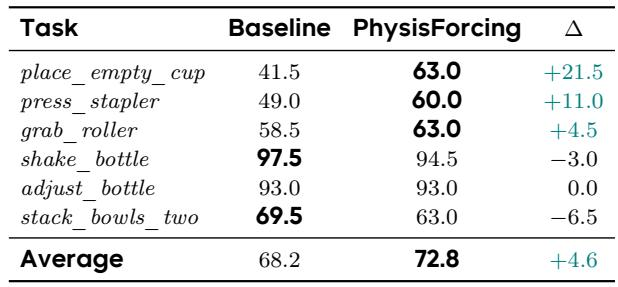
在 Fast-WAM 中使用 PhysisForcing 替换视频骨干网络,将六个 RoboTwin 2.0 任务上的平均成功率从 68.2% 提高到 72.8%。提升集中在接触密集的放置和按压任务上,而已经具有高成功率的任务则表现出持平或略有下降的性能。PhysisForcing 将 place_empty_cup 提升了 21.5 个百分点,将 press_stapler 提升了 11.0 个百分点,这是所有任务中增益最大的。具有高基线成功率的任务,如 shake_bottle 和 adjust_bottle,未见提升或略有下降,stack_bowls_two 下降了 6.5 个百分点。
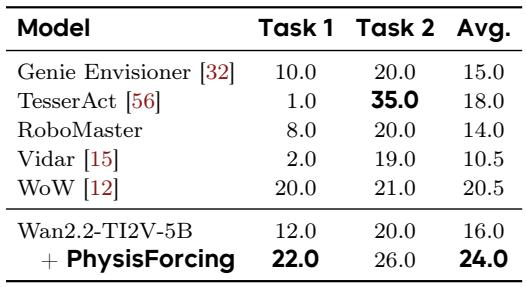
将 PhysisForcing 融入 Wan2.2-TI2V-5B 视频骨干网络,将平均闭环动作规划成功率从 16.0% 提高到 24.0%,超越了所有先前基于世界模型的规划器,包括先前最好的 WoW(20.5%)。在两个评估任务上均观察到增益,表明规划能力的稳健改善。PhysisForcing 相较于基础视频模型,在平均成功率上提供了 8 个百分点的绝对提升。以显著优势超越了先前最强的世界模型规划器 WoW。任务 1 的成功率几乎翻倍,任务 2 也实现了稳固的增长。
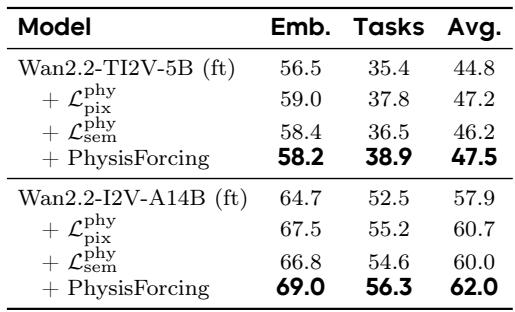
在 R-Bench 上消融两种物理损失表明它们是互补的:单独的像素级损失带来了更大的个体改善,尤其是在具身性指标上,而加入语义损失进一步提升了任务导向的性能。两者的结合,即 PhysisForcing,在 5B 模型上取得了最高的总体平均分和任务分数,并且在更大的 14B 模型上的一致增益证实了这种好处可跨骨干网络扩展。单独的像素级物理损失将 R-Bench 的平均分在微调基线上提高了 2.4 分,超过了语义损失的 1.4 分增益。将两种损失结合为 PhysisForcing,在 5B 模型上取得了最高的任务分数(38.9 对比 35.4)和最高的总体平均分(47.5 对比 44.8),尽管具身性分数略低于仅使用像素损失的设置。在更大的 14B 模型上,像素损失将平均分从 57.9 提升到 60.7,语义损失提升到 60.0,证明了这些改进不仅限于单一模型规模。
在所有视频token上均匀施物理损失能比基线提升平均性能,但将其限制在交互关键区域会带来进一步的提升,尤其是在任务导向指标上。这表明无关的背景区域稀释了物理信号,将监督集中在机器人-物体交互发生的区域才能驱动任务级别的正确性。均匀施加物理损失将平均分从 44.8 提升到 46.0,而聚焦于物理信息区域则将其推至 47.5。最大的增益在于任务导向性能,当监督集中在交互关键区域时,该指标从 35.4 上升到 38.9。嵌入指标也因区域聚焦而改善,从 56.5 提升到 58.2,显示出更好的物理一致性。背景和近乎静态的区域稀释了学习信号;将损失计算限制在机器人-物体交互区域显著改善了任务级别的结果。

PhysisForcing 在视频生成、机器人操控和世界模型规划任务上均大幅提升了性能。该方法将视频生成质量提升到超越商业和开源基线的水平,增强了接触密集型的操控策略,并提高了闭环规划的成功率。互补的像素级和语义级物理损失,结合在机器人-物体交互区域上的专注监督,驱动了这些增益,并且这些益处可扩展到更大的视频骨干网络。