Command Palette
Search for a command to run...
MultiHashFormer:基于哈希的生成式语言模型
MultiHashFormer:基于哈希的生成式语言模型
Huiyin Xue Atsuki Yamaguchi Nikolaos Aletras
摘要
语言模型(LM)使用嵌入矩阵表示标记,其规模与词汇量大小成线性关系。为了限制参数量,先前的工作提出在仅编码器模型中将多个标记哈希到单个向量中。虽然这提供了参数效率,但多对一的冲突阻碍了其在因果语言模型中的应用。本文提出了MultiHashFormer,一个允许基于哈希的自回归生成的新框架。每个标记被表示为一个唯一的哈希签名,即由多个独立哈希函数生成的离散哈希ID短序列。哈希编码器将此签名压缩为单个潜在向量,供Transformer解码器处理。然后,哈希解码器生成下一个标记的哈希签名,再将其映射回文本。我们在1亿、10亿和30亿参数规模上评估了该方法,证明MultiHashFormer在多个基准测试上始终优于标准Transformer语言模型。此外,我们展示了该模型在无需任何修改的情况下,以恒定的参数量处理多语言词汇扩展。
一句话总结
谢菲尔德大学的研究人员提出了 MULTIHASHFORMER,一种基于哈希的自回归语言模型,通过多个独立的哈希函数将 token 表示为独特的无冲突哈希签名,在 100M、1B 和 3B 参数规模下,该模型在多个基准测试中优于标准 Transformer,同时支持在参数规模恒定的情况下扩展多语言词汇表。
核心贡献
- 本文首次提出用于因果语言建模的哈希框架,通过多个独立哈希 ID 为每个 token 生成唯一签名,防止 token 冲突,实现确定性自回归文本生成。
- 在 100M、1B 和 3B 参数规模上的实证评估表明,MULTIHASHFORMER 在 10 项任务中始终优于标准 Transformer 语言模型,并为罕见词产生更强的表示。
- 该方法支持在不改变架构或增加参数数量的情况下扩展词汇表,从 32K 扩展到 48K token 时仍能保持性能。
引言
语言模型依赖于随词汇量线性增长的大型嵌入矩阵,这限制了它们在不重新训练的情况下适应新领域或语言的能力。先前的工作引入了基于哈希的嵌入来固定参数规模,但这些多对一的映射导致 token 冲突,使得自回归解码无法进行,因为解码器无法从共享的哈希索引中唯一地恢复特定 token。作者提出了 MULTIHASHFORMER,一个生成式框架,用多个独立的哈希函数取代单一的嵌入矩阵,为每个 token 赋予唯一的多元 ID 签名。这种无冲突设计支持因果语言建模,参数增长呈亚线性,在多个规模上优于标准 Transformer,并能在不增加参数的情况下扩展词汇表。
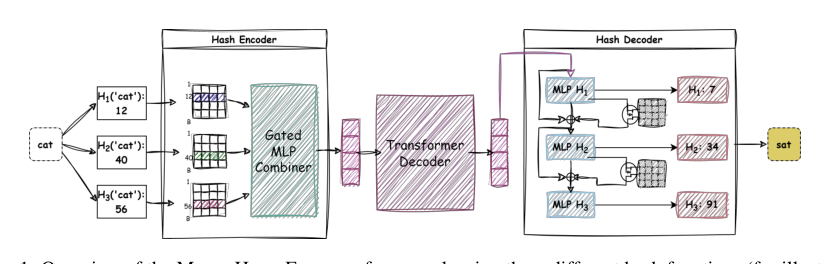
方法
作者提出了 MultiHashFormer,一个旨在绕过基于解码器的语言模型词汇瓶颈的框架。该架构包含三个主要模块:哈希编码器、序列处理主干和哈希解码器。
哈希编码器将离散输入 token 映射为分布式的多元 ID 签名,并将其压缩为稠密嵌入。对于多元哈希索引,作者使用 H 个独立的哈希函数,具体为 MurmurHash3 算法,来计算签名坐标。为确保词汇表中每个 token 的无冲突映射,采用了迭代重哈希策略。如果新 token 的签名与现有条目冲突,则逐步修改最后一个哈希函数的种子,直到找到未使用的签名。为解决全局共享哈希桶带来的歧义,作者引入了门控组合嵌入。每个哈希坐标通过一个压缩维度为 dz≪d 的前馈瓶颈网络,然后进行 softmax 归一化,以确定每个桶的贡献。然后,线性适配矩阵 Ws 将组合表示投影到序列处理主干的潜在空间中:
e=(∑i=1Hα~iE[Hi(w),:](i))Ws
其中门控权重 α~i 通过瓶颈投影计算。
序列处理主干将这些嵌入转换为上下文表示。哈希嵌入序列 X=[e1,e2,…,en]⊤ 通过 L 个标准 Transformer 层的堆叠。在每个时间步 t,最后一层输出一个上下文潜在向量 ht,随后输入到哈希解码器。
哈希解码器使用自回归级联预测器自回归地重建下一个 token 的多元 ID 签名。该模块迭代地细化索引预测,起到结构化纠错系统的作用。预测循环从当前时间步 t 的主干最终隐藏状态初始化,设置根状态 c(1)=ht。对于每个顺序哈希头 i∈{1,…,H},解码器使用专用的权重矩阵 Wo(i) 将当前潜在哈希状态 c(i) 投影,以计算物理桶分配上的 logit 分布 o(i),其中输入和输出嵌入权重是绑定的。对于非终端头,解码器计算软桶嵌入 e(i),作为由 logit 概率加权的共享嵌入矩阵的期望值,以保持可微性。为了将上下文化轨迹传播到下一个签名头,递归级联混合器通过将现有状态与检索到的软嵌入连接,并通过带有结构残差连接的瓶颈层路由,来更新内部哈希状态:
c(i+1)=c(i)+Wup(i)⊤σ(Wdn(i)⊤[c(i)e(i)])
最后,作者详细介绍了训练和推理的概率建模。在训练期间,模型在虚拟词汇空间上优化独立坐标概率的乘积,允许对可能不映射到实际词汇条目的坐标组合进行预测,以简化优化目标。在推理期间,为防止生成无效签名,概率分布被显式地严格重新归一化到真实 token 词汇表上,通过累加各个哈希 ID 的对数概率并在有效 token 空间上应用标准 softmax 归一化。
实验
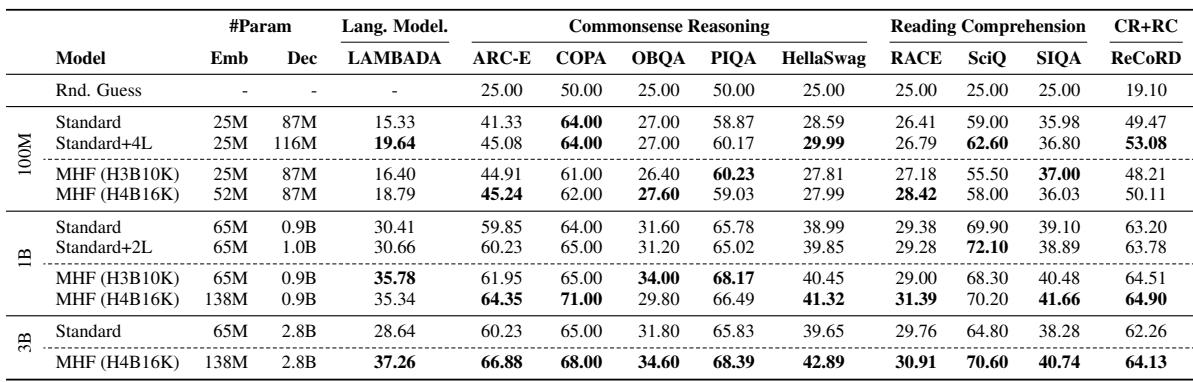
评估将使用多元哈希签名构建 token 嵌入的 MULTIHASHFORMER 模型与标准及深度增强的仅解码器 Transformer 在 100M、1B 和 3B 参数规模下进行比较,测试语言建模、常识推理、阅读理解、罕见词相似度以及零参数多语言词汇扩展。在 1B 和 3B 规模下,MULTIHASHFORMER 始终优于参数匹配的基线,特别是在 LAMBADA 等上下文敏感预测任务上,同时产生更好的罕见词语义表示,并在不增加额外参数的情况下添加 15K 新语言 token 后保持英语性能。多元哈希签名被证明对于避免表示冲突至关重要,H4B16K 配置提供了嵌入容量和准确性的最佳平衡,随机哈希已足够,而局部敏感哈希未带来持续增益。
MultiHashFormer 将词汇分配与模型深度解耦,在跨规模的语言建模和常识推理上始终优于标准基线。H4B16K 配置实现了最佳平衡,随着参数数量从 100M 增长到 3B,增益更加显著,而严格的参数匹配表明基于哈希的变体比增加层数更有效。在 1B 规模下,MultiHashFormer 变体在 10 项任务中的 8 项上超越标准对应模型,MHF (H4B16K) 在 ReCoRD 上达到 64.90,而 Standard+2L 基线为 63.78。将模型容量从 1B 增加到 3B,MHF (H4B16K) 在 LAMBADA 上比标准模型提高了 8.62%,展示了扩展效能。
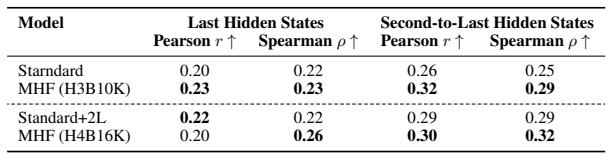
在 Card-660 数据集上,MULTIHASHFORMER 模型在相同参数数量下与人类语义相似度判断的相关性高于标准模型。这种改进在倒数第二个解码器隐藏状态中最为明显,那里的表示对训练任务的偏差较小,证实了多元 ID 哈希更好地捕捉了罕见词语义。MULTIHASHFORMER 变体在 Pearson 和 Spearman 相关指标上始终优于 Standard 和 Standard+2L 模型。当从倒数第二个隐藏状态测量时,MULTIHASHFORMER 与标准模型之间的性能差距比从最后一个隐藏状态测量时更大。MHF (H4B16K) 配置在倒数第二层产生了最高的 Spearman 相关性 (0.32),表明与人类相似度评分更一致。
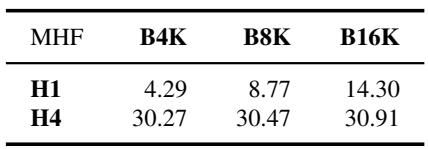
从单 ID 切换到多元 ID 签名显著提高了 LAMBADA 准确率,多元 ID (H4) 在所有桶大小下均达到约 30%,而单 ID (H1) 最高仅为 14.30%。在最小的桶大小下,这种优势尤为明显,多元 ID 将准确率从 4.29% 提高到 30.27%,表明防止哈希冲突远比简单增加桶容量更有效。多元 ID 签名始终达到接近 30% 的 LAMBADA 准确率,而单 ID 签名即使有 16K 桶也无法超过 15%。多元 ID 与单 ID 之间的差距在最小桶大小时最大,多元 ID 在 B4K 时将准确率从 4.29% 提高到 30.27%,说明避免冲突比增加桶数量更有影响力。
在多元哈希嵌入模型中将标准随机哈希函数替换为局部敏感哈希并未带来 LAMBADA 准确率的持续提升。在所有比例下,性能徘徊在 31% 左右,即使完全使用 LSH 也没有明显优势。这表明,鉴于基础哈希方案的数据驱动灵活性,LSH 带来的形态学偏差是不必要的。从全 MMH3 (30.91) 切换到全 LSH (31.36) 时,LAMBADA 准确率保持在 31% 附近,中间混合没有显示出单调趋势。最高准确率 (31.40) 出现在三个 LSH 和一个 MMH3 函数时,但相对于全 MMH3 基线的改进微乎其微。标准确定性哈希 (MMH3) 已经提供了足够的表示自由度,使得 LSH 的显式形态学先验对于子词学习是多余的。

MultiHashFormer 将词汇分配与模型深度解耦,并采用多元 ID 哈希来缓解冲突,评估涵盖语言建模、常识推理和语义相似度任务。该方法始终优于标准 transformer,H4B16K 配置有效扩展,随着模型规模从 100M 增加到 3B 参数,增益更大。多元 ID 哈希通过避免冲突而非仅仅扩大容量,显著提高了相对于单 ID 的准确率,并且模型的表示更贴近人类语义判断,尤其是在中间层,而局部敏感哈希相对于标准随机哈希没有优势。