Command Palette
Search for a command to run...
Qwen-Image-2.0-RL 技术报告
Qwen-Image-2.0-RL 技术报告
摘要
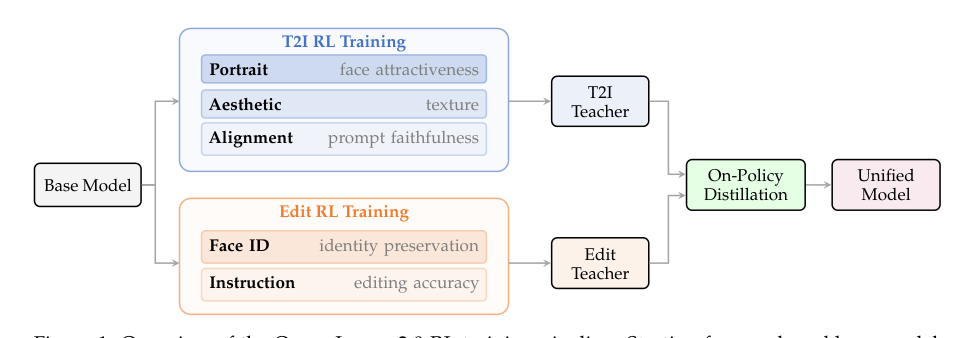
我们提出 Qwen-Image-2.0-RL,一个后训练流水线,应用基于人类反馈的强化学习 (RLHF) 和在线策略蒸馏 (OPD) 来提升 Qwen-Image-2.0 扩散模型的视觉质量和指令遵循能力。为了提供可靠的奖励信号,我们通过微调视觉语言模型构建了任务特定的复合奖励模型,采用点式评分范式和链式思维推理。对于文生图任务,奖励模型覆盖对齐度、美学和肖像保真度维度。对于图像编辑任务,奖励系统解决指令遵循准确性和面部身份保留问题。基于此奖励系统,我们开发了一个可扩展的基于 GRPO 的 RL 训练框架,结合混合无分类器引导 (CFG) 策略以保留预训练知识,通过组内奖励范围过滤进行提示词管理,以及按类别奖励权重校准。为了合并 T2I 和编辑的任务专用 RL 策略,我们提出在线策略蒸馏作为最终训练阶段,通过轨迹级速度匹配将多个教师模型融合到单个学生模型中。广泛评估显示,Qwen-Image-2.0-RL 在 Qwen-Image-Bench 上获得 57.84 总分(比基础模型提高 +2.61),在文生图竞技场 Elo 评分为 1193(+78),图像编辑竞技场为 1349(+93),展示了在美学质量、提示遵循和编辑准确性方面的持续提升。
一句话总结
作者提出了 Qwen-Image-2.0-RL,一个后训练流程,该流程应用基于人类反馈的强化学习(RLHF),使用通过逐点评分和思维链推理微调的复合奖励模型,并通过轨迹级速度匹配进行同策略蒸馏,统一了文本到图像和图像编辑的改进,在 Qwen-Image-Bench 上取得了 +2.61 的整体分数,文本到图像的 Elo 评分为 1193,图像编辑的 Elo 评分为 1349。
核心贡献
- 构建了一个基于 VLM 的复合奖励系统,用于文本到图像和图像编辑任务,通过使用逐点评分和思维链推理对视觉语言模型进行微调,涵盖美学质量、提示遵循度、人像保真度、指令遵循度和视觉一致性。
- 开发了一个可扩展的基于 GRPO 的强化学习训练框架,采用混合 CFG 策略(仅在 rollout 采样期间应用引导)、通过组内奖励范围过滤进行提示筛选,以及按类别进行奖励权重校准,以稳定大规模流匹配模型训练。
- 提出了同策略蒸馏,通过轨迹级速度匹配将任务专用的 RL 教师模型统一为单个部署模型,消除了奖励模型依赖和跨任务冲突;由此产生的 Qwen-Image-2.0-RL 超越了混合 RL 基线,在 Qwen-Image-Bench 上取得了 57.84 的整体分数(+2.61),T2I 竞技场的 Elo 评分为 1193(+78),图像编辑竞技场的 Elo 评分为 1349(+93)。
引言
作者解决了扩散模型强大的生成能力与人类审美偏好之间的差距,这一差距是由监督去噪目标留下的,该目标无法捕捉诸如构图、纹理或提示忠实度等细微品质。虽然基于人类反馈的强化学习(RLHF)提供了一条对齐路径,但将其应用于扩散模型面临三个关键挑战:设计跨越文本到图像和图像编辑任务的可靠、任务感知的奖励信号;将 RLHF 扩展到具有多个奖励的全参数训练;以及将任务专用策略整合到单一模型中而不损失质量。作者通过一个统一的后训练流程来解决这些问题,该流程建立在支持思维链的 VLM 奖励套件、具有混合无分类器引导和提示-奖励平衡的可扩展基于 GRPO 的强化学习框架,以及通过轨迹级速度匹配合并专用教师模型的同策略蒸馏方法之上,从而在部署时消除了奖励模型依赖。
数据集
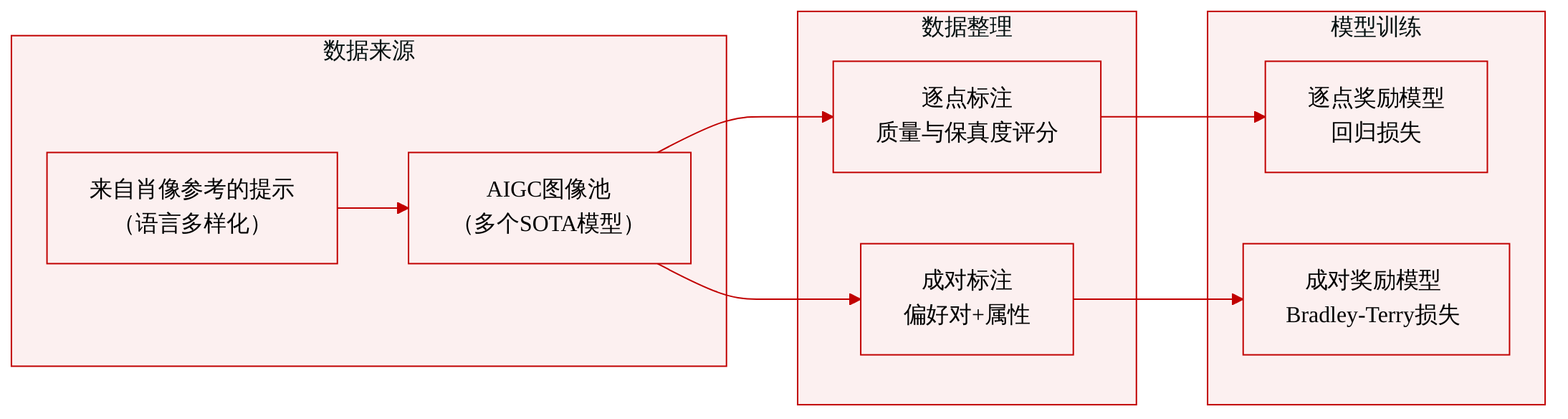
作者构建了两个带标注的数据集来比较奖励模型训练范式,特意共享相同的评估重点(美学质量和视觉纹理),仅在标注格式上有所不同。两个数据集都从最先进的 AIGC 模型的公共池中提取图像,这些图像根据源自高质量人像参考图像的提示生成,并经过语言多样化处理,以超出训练分布。
数据集构成与来源
- 所有图像都来自同一个 AIGC 生成输出的池,确保比较隔离了训练范式的影响,而非数据分布。
- 提示从高质量人像参考图像中随机采样,并重写以增加语言多样性。
- 本摘录中未报告明确的数据集大小;重点在于标注结构和训练用途。
逐点评分子集
- 每张图像由人类标注者独立评分,采用 5 点李克特量表,涵盖两个维度:质量(清晰度、光照、色彩平衡、风格连贯性、材质纹理)和保真度(结构正确性、物理一致性、无 AI 伪影)。
- 生成的数据集提供每张图像的绝对分数,用于通过逐点回归损失训练奖励模型(模型输出离散分数分布,奖励为期望值)。
成对比较子集
- 图像对由相同提示生成,并排呈现以供偏好判断。
- 标注遵循严格的优先级层次:图文一致性 > 结构失真 > 纹理质量 > 美学吸引力。当两张图像都没有失真且与提示一致时,比较实际上归结为纹理质量和美学吸引力。
- 每对图像还标注了辅助属性:样本有效性、是否存在文本失真以及是否存在人物失真,以支持细粒度分析。
- 生成的数据集提供偏好对,用于通过 Bradley-Terry 成对排序损失训练奖励模型。
数据使用方式
- 两个子集都用于将相同的 VLM 架构微调为奖励模型,一个使用成对损失,另一个使用逐点回归。
- 在下游基于 RL 的图像生成中,经过逐点训练的奖励模型始终产生更好的视觉质量和更少的伪影,因此作者在最终系统中对所有基于 VLM 的奖励模型采用了逐点范式。
处理细节
- 未提及裁剪策略或额外的图像预处理。
- 元数据构建:逐点数据存储每张图像的质量和保真度分数;成对数据存储偏好标签和上述辅助属性。
方法
作者利用一个全面的强化学习框架,使扩散模型与人类偏好对齐,该框架以稳健的奖励建模系统和专用的训练流程为中心。
奖励建模 为了捕捉人类偏好,作者构建了任务专用的复合奖励模型。他们研究了两种用于微调视觉语言模型(VLM)作为奖励评分器的训练范式:成对排序和逐点回归。在成对方法中,模型在偏好与非偏好图像对上最小化 Bradley-Terry 排序损失。相反,逐点范式训练模型直接回归到人类标注的绝对分数。作者确定,逐点训练提供了更丰富的监督信号,与成对方法相比,生成的图像具有始终更好的视觉质量、更精细的纹理细节和更少的伪影。

训练流程与混合 CFG 策略 训练过程将组相对策略优化(GRPO)扩展到流匹配模型。一个关键的架构决策涉及无分类器引导(CFG)的应用。作者系统地评估了三种策略:在 rollout 和训练中都应用 CFG,在两个阶段都移除 CFG,或采用混合方法。在训练期间应用 CFG 会导致严重的不稳定和图像崩溃,而完全省略 CFG 则会导致模型失去风格化能力和世界知识。因此,作者采用了一种混合策略,其中 CFG 仅在 rollout 阶段使用,以生成用于奖励评估的高质量候选样本,而策略优化目标保持无 CFG,以维持稳定的梯度更新。

该流程结合了异步奖励机制,将评分与训练解耦,有效地隐藏了网络延迟。组相对优势通过加权求和与每组提示归一化计算: A(x0(i),c)=∑k=1Kwk⋅σkRk(x0(i),c)−μk 这确保了复合奖励对各个奖励模型之间的绝对尺度差异具有不变性。任务特定的优化包括将训练信号限制在高噪声时间步,以防止奖励破解,并筛选出表现出足够奖励方差的提示,以确保有意义的策略改进。
同策略蒸馏 为了解决 RL 优化产生任务专用策略(例如,文本到图像生成和图像编辑的单独模型)的局限性,作者引入了同策略蒸馏(OPD)。该方法通过轨迹级速度匹配,将多个任务专用的教师模型统一到一个学生模型中。学生模型生成完整的去噪轨迹,并经过训练以匹配每个步骤中相应任务教师模型的速度预测: LOPD=Ec,x[1:N]∼πθ(⋅∣c)[∑n=1N∥vθ(xtn,tn,c)−vθ∗(xtn,tn,c)∥2] 这种分解策略避免了在混合任务(Mix-RL)上联合训练所固有的优化冲突。与预训练基础模型和 Mix-RL 基线相比,最终的统一模型在提示遵循度、美学质量和身份保持方面取得了更优的表现。
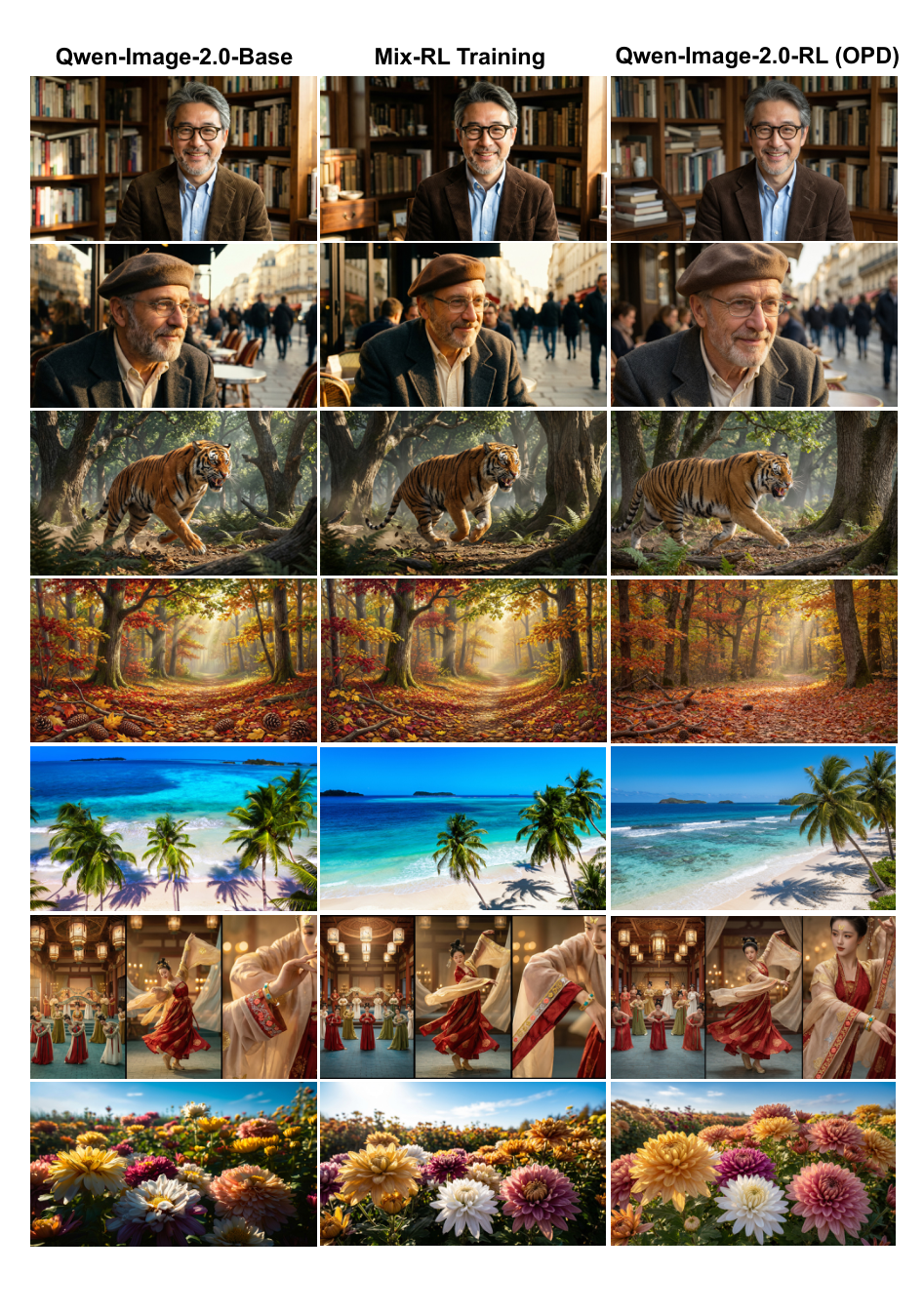
对于图像编辑任务,该框架集成了一个专用的基于模型的面部身份一致性评分器,以及基于 VLM 的指令遵循奖励。这确保了在复杂编辑(如风格迁移或属性修改)过程中保留细粒度的身份特征,使模型能够准确地执行指令,同时保持主体的原始特征。

实验
评估涵盖了自动化质量指标和人类偏好竞技场。RL 训练在 Qwen-Image-2.0 的所有维度上持续改进,其中创意生成、真实世界保真度、3D 建模和照片真实感的提升最大。图像编辑竞技场也显示出显著的增益,证实了编辑特定 RL 训练的有效性。
强化学习训练将 Qwen-Image-2.0 在 Qwen-Image-Bench 上的整体分数从 55.23 提升到 57.84,在所有五个评估支柱上都有持续的增益。最大的改进出现在创意生成和真实世界保真度方面,使经过 RL 训练的模型成为所有比较系统中最强的表现者。创意生成从 RL 中受益最多,提高了 6.72 分,凸显了增强的想象力能力。真实世界保真度提高了 4.29 分,反映了更好的结构一致性和精细细节渲染。
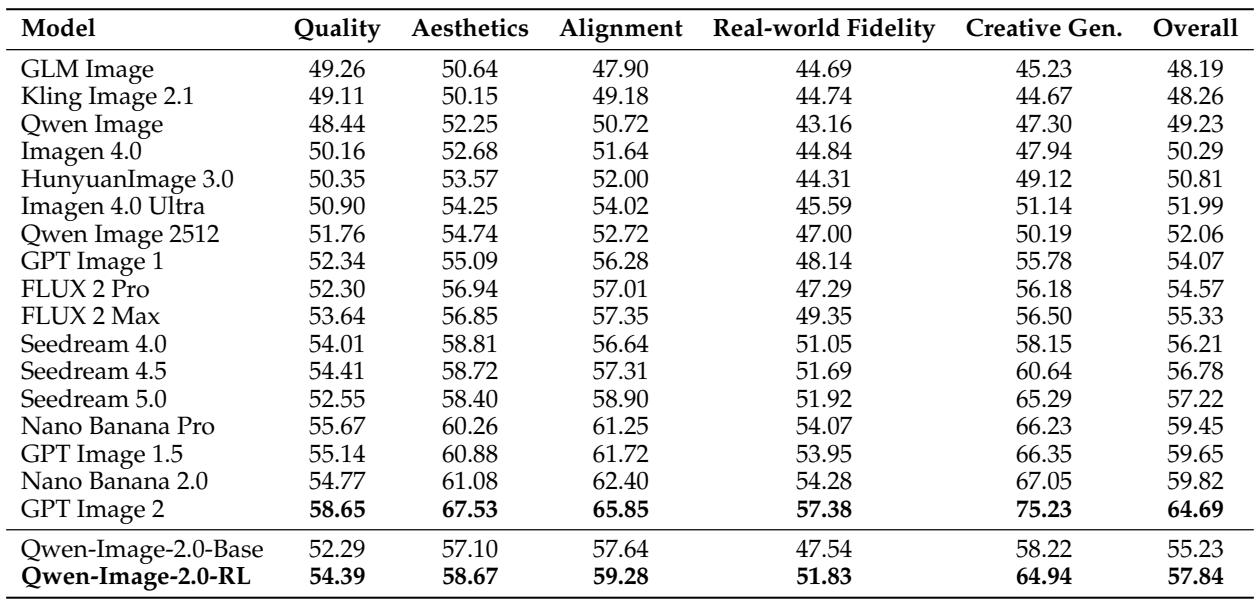
强化学习训练提高了 Qwen-Image-2.0 在 Qwen-Image-Bench 上的整体表现,在所有评估支柱上产生了持续的增益。最大的改进出现在创意生成和真实世界保真度方面,使经过 RL 训练的模型成为比较系统中最强的表现者。这些增益反映了增强的想象力能力、更好的结构一致性和更精细的细节渲染。