Command Palette
Search for a command to run...
形式化潜在思维:大语言模型中思维表征的四项公理
形式化潜在思维:大语言模型中思维表征的四项公理
Fahd Seddik Fatemeh Fard
摘要
我们为大语言模型中的潜在思维表征引入一个公理化评估框架,包含独立于下游基准得分的度量指标,揭示被基准准确率掩盖的表征失效。现有评估将表征质量与模型能力混为一谈,因此失效无法归因于表征本身,而可能归因于处理该表征的模型。我们形式化四项功能性公理(因果性、最小性、可分离性、稳定性),并为每项定义量化指标,直接在表征上计算,不依赖下游准确率。我们在23项推理任务(如空间推理、事实问答)上审查开源大语言模型。我们发现,无任何候选模型同时满足全部四项公理;表征能可靠地区分任务类型,但无法区分同一任务内的两个问题;表征编码的信息极少超出输入嵌入中已有的内容。这一失效在稠密模型、推理蒸馏模型以及强化学习训练模型系列中普遍存在,表明差距是结构性的,而非模型规模或训练过程所致。
一句话总结
不列颠哥伦比亚大学的研究者形式化了四个功能公理——因果性、极小性、可分离性和稳定性——并配以相应的量化度量,以直接审计潜在思维表征。在23项推理任务(如空间推理、事实问答)上,他们发现没有一个开放权重模型能满足所有公理:表征能清晰地区分任务类型,但无法分离任务内的问题,并且几乎不编码输入嵌入之外的信息。这表明密集模型、推理蒸馏模型和强化学习训练模型家族之间存在结构性的鸿沟。
核心贡献
- 一个用于LLM潜在思维表征的公理评估框架,形式化了四条公理(因果性、极小性、可分离性、稳定性),并配以直接在表征上计算、独立于下游基准准确率的量化度量指标。
- 一项跨越23项推理任务与五个开放权重LLM的经验审计揭示:现有表征无一满足全部四条公理;能区分任务类型,但不能区分同一任务内的个体问题;所编码的信息极少超出输入嵌入所包含的范围。
- 这些表征性失败在密集模型、推理蒸馏模型和强化学习训练模型中均一致出现,表明存在结构性的能力缺口。该框架能将推理准确率的变化分解为具体的公理属性,从而支持有针对性的表征设计。
引言
大型语言模型越来越多地使用连续潜在向量而非显式的思维链token来进行推理,以追求效率和准确率的提升。然而,先前的工作仅通过下游任务准确率来评估这些连续思维表征,却缺少一种形式化定义,说明一个有效的思维表征应编码什么,以及如何独立于最终答案来度量其质量。作者提出了一个公理框架,定义了四个必要的功能属性:因果性、极小性、可分离性和稳定性。他们引入对应量化指标,这些指标可直接在源LLM上计算而无需重新训练,从而能够对思维表征进行有原则的审计。将这一协议应用于横跨多个LLM的若干候选方法后,审计揭示了一种下游准确率所掩盖的、在逐问题身份上的表征坍缩,为未来研究建立了新的诊断工具箱。
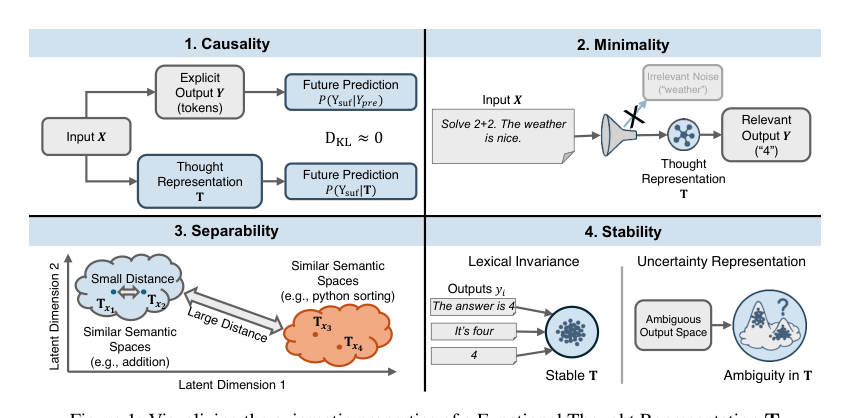
方法
作者提出了一个公理框架来刻画功能性思维表征 T。它并非可被传达的语言制品,而是一种潜在状态,在从输入空间 X 到语义输出空间 S 的转换过程中起中介作用。为严格评估这些表征,作者首先建立了语义等价的标准。两个序列 y,y′∈Y 被称为语义等价,记作 y∼semy′,当且仅当语义映射函数满足 Φ(y)=Φ(y′)。此语义流形 S 装备了一个度量 dS,计算上通过高维文本嵌入间的余弦相似度来近似。
一个稳健的思维表征必须满足四条公理化属性:因果性、极小性、可分离性与稳定性。
1. 因果性 将输出序列 y 划分为推理前缀 ypre 和答案后缀 ysuf。若要 T 成为由 ypre 导出的有效思维表征,它必须在模型的计算图中功能性地替代 ypre 的显式token。这意味着基于 T 的条件化所产生的关于 ysuf 的预测分布,应与基于 ypre 的条件化所产生的分布无法区分。作者通过因果性误差对此量化: Causality Error=DKL(P(ysuf∣ypre)∥P(ysuf∣T)) 较低的值表示 T 成功封装了推理前缀对后续生成过程的因果效应。
2. 极小性 与信息瓶颈原则一致,一个最优的 T 必须在压缩输入 X 的同时,保留与输出分布 Y 的最大相关性。它应滤除对生成高概率语义输出没有贡献的冗余变量。其理想目标是在 I(T;Y) 的约束下最小化 I(X;T)。由于互信息项难以处理,作者构造了一个交叉熵替代量,该量在 β=2 时能保持拉格朗日量的排序性质: ΔIB=CE(X∣Y,T)−CE(Y∣T) 更大的 ΔIB 表示该表征同时具备高相关性和极小性。
3. 可分离性 该公理定义了从语义内容到潜在空间的映射的函数单射性。表征必须包含足够的拓扑结构,以便使用一个容量有界的投射来区分语义上不等价的输出分布。对于诱导出不相交高概率语义空间的输入 x1,x2,其表征 Tx1 和 Tx2 必须能被一个最优语义投射 ϕ:T→S 所分辨,使得 dS(ϕ(Tx1),ϕ(Tx2))>δ。为量化这点,作者将 ϕ 实例化为一个学习的二元判别器 fdisc(T,Y),其具体形式是将 T 映射到冷冻LLM骨架的嵌入空间的一个可训练线性投影,后接一个分类头。分类准确率即作为可分离性的度量指标。
4. 稳定性 表征必须对表层词汇变化具有不变性,并对采样随机性具备鲁棒性。T 不应编码单一的实现结果,而应编码语义分布 P(S∣x) 的参数。这要求模式坍缩抵抗(T 能反映 P(Y∣x) 的熵)和词汇不变性(语义等价的同类输出会导出近似相同的表征)。作者通过语义熵 Hx 来量化分布不确定性,该熵由输出嵌入间成对余弦相似度的二值化来形成语义等价类。为测量 T 是否线性地编码了这一属性,他们采用均值差探针,并报告预测 Hx>0 的交叉验证AUROC,得出分布一致性分数。
实验
该研究使用跨五个开放权重LLM的共享冷冻模型探针及束搜索生成,从因果性、极小性、可分离性和稳定性方面评估了思维表征(最终输入token、软token、潜在思维)。在任何维度上,没有一个候选表征能始终超越简单的输入提示嵌入;随着迭代步数增加,迭代思维家族出现退化;任务内可分离性跌至接近随机水平,唯有输出嵌入例外。即使模型取得强大的基准准确率,这些表征层面的差距依然存在,揭示了当前推理时计算未能可靠地编码超出提示之外的额外任务相关信息。
跨越多个语言模型,没有任何思维表征候选在因果性、极小性、可分离性或稳定性上始终超越简单的输入嵌入参照。仅输出嵌入在任务内可分性上超越随机基线。迭代思维方法的结果优劣参半:通常能改善极小性,但随着步数增加性能退化。当对所有被测语言模型取均值时,没有任何思维表征家族能同时在四条公理上全面超越输入嵌入基线。仅输出嵌入在任务内可分性上超越随机基线;而随着推理步数增长,迭代思维方法的表现趋于回落。

在跨被测语言模型和推理任务的所有比较中,没有任何思维表征候选能在全部四个评估轴上始终超越简单的输入提示嵌入。输出嵌入获得了出色的任务内可分性,但在极小性上表现不佳。迭代思维方法改善了极小性,但随着额外步数增加而退化,并且无法在每个轴上都匹敌输入嵌入。该评估协议揭示了下游基准准确率与内部思维表征几何质量之间的脱节。仅输出嵌入在任务内可分性上超越随机基线。迭代思维家族在极小性上超越输入嵌入参照,而最终输入token则在此方面低于输入嵌入参照。向软token添加Gumbel噪声会降低稳定性,这与噪声在探索中所起的作用一致。当对模型取均值时,没有任何候选表征能在任何单轴上击败输入嵌入参照。随着思维步数的增加,迭代思维变体的表征质量一致地退化。

跨越涵盖密集、稀疏MoE、推理蒸馏和原生RL范式的五个源LLM,没有任何候选思维表征能在任何一个评估轴中始终超越输入提示嵌入。随着步数增长,迭代思维方法发生退化,并且无法同时具备强大的任务内聚类、宽广的任务可分离性以及高任务内稳定性。输出嵌入在可分离性上超越了随机基线,但由于其构造方式,不适合作为极小性的参照;最终输入token表征在极小性上不及迭代方法。当在LLM间对结果取均值时,没有任何表征在所有四个轴上超越输入嵌入。迭代思维家族(软token、潜在思维)在极小性上超越了最终输入token,但随思维步数增加性能下降。仅输出嵌入在任务内可分性上超越随机基线;其构造方式违背了极小性分解的假设。在稳定性上,带有Gumbel噪声的软token是唯一的离群点,落在输入嵌入参照及其他迭代方法之下。输出嵌入与输入嵌入对续写分布产生的扰动效应相当,因此在因果性轴上两者均不占优。
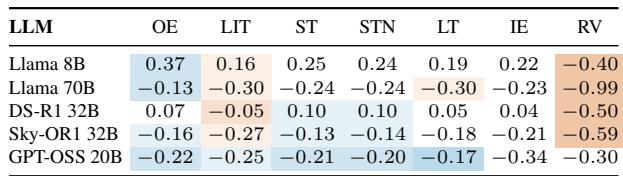
极小性指标衡量一个表征压缩输入特定细节并保留输出相关信息的能力,值越高表示压缩越好。输出嵌入取得了最高分,但由于其构造方式,在此轴上不具可解释性。在其余候选者中,没有任何表征能始终超越输入嵌入参照;最终输入token的得分通常低于它,而软思维变体和最终token变体的得分则接近或略高于它,且在源模型之间存在显著差异。输出嵌入获得了最高的极小性值,但由于其构造违背了分解假设,被排除在有效比较之外。在多数模型上,最终输入token得分低于输入嵌入,意味着它携带了对于输出预测不重要的输入特定信息。软思维变体(ST、STN)与最终token变体处于或略高于输入嵌入水平,但相对于提示表征并无一致优势。
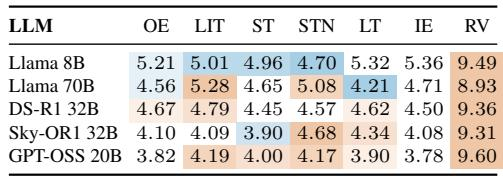
所有思维表征的因果性KL散度都远低于随机向量基线,确认它们编码了与续写相关的信息。然而,没有任何一个能始终超越输入嵌入参照,表明它们并未携带超过提示本身所包含的额外因果信息。不同模型中表现最佳的变体各异,且与输入嵌入的差异较小且不一致。每一个思维表征产生的KL散度都实质性低于随机向量基线(约4–5纳特 vs. 9.3–9.6纳特),证明它们捕捉到了续写相关的结构。没有任何表征家族能始终击败输入嵌入;某些变体偶尔得分略低,但排名在模型间发生翻转且差距很小,表明不存在可靠的因果优势。
跨多个语言模型,实验评估了思维表征候选者在四条公理(因果性、极小性、可分离性、稳定性)上的表现,并将其与输入嵌入基线进行比较。没有任何表征在所有轴上均超越基线;输出嵌入取得了强大的任务内可分性,但被排除在极小性比较之外;迭代思维方法可以改善极小性,但随步数增加而退化。所有表征都捕捉到与续写相关的结构,但从未在提示之上增添因果信息;添加Gumbel噪声会降低稳定性。总体而言,思维表征的几何质量并未始终超越简单的输入提示,且下游准确率高并不蕴含更好的表征属性。