Command Palette
Search for a command to run...
DanceOPD:同策略生成场蒸馏
DanceOPD:同策略生成场蒸馏
摘要
现代图像生成需要一个能够统一多种能力的单一模型,涵盖文本到图像(T2I)、局部编辑与全局编辑。然而,这些能力极少能够自然对齐,且经常相互冲突。例如,编辑操作往往会损害T2I性能,而全局编辑与局部编辑会彼此干扰。因此,有效组合这些能力已成为图像生成模型训练的关键挑战。为此,我们提出了DanceOPD,这是一种面向流匹配模型的同策略生成场蒸馏框架。该框架将每个样本路由至单一能力场,查询一个低噪声的学生诱导状态,并采用简单的速度均方误差(MSE)目标进行训练。通过将每个能力源定义为定义在共享流状态空间上的速度场,学生模型从其自身rollout状态上查询的场中学习,从而组合出专家级能力。该公式化方法还能够吸收由算子定义的场,例如无分类器引导(CFG)。在T2I生成、图像编辑、真实感场吸收以及CFG吸收方面的综合实验表明,我们的方法有效提升了多能力组合效果,在维持锚点生成质量的同时显著增强了目标能力。我们认为,本研究为流匹配模型中的生成场蒸馏提供了一条切实可行的路径。
一句话总结
DanceOPD 是一种面向流匹配模型的在线策略生成场蒸馏框架。该框架将每个样本路由至特定的能力速度场,在 rollout 过程中查询学生模型生成的状态,并通过速度均方误差目标进行训练,从而在保持锚点生成质量的同时,统一文本到图像生成与局部/全局编辑功能。该框架的有效性已在 T2I、编辑、真实感场及无分类器引导等实验中得到验证。
核心贡献
- 本文提出 DanceOPD,一种面向流匹配模型的在线策略生成场蒸馏框架。该框架将各项能力视为共享状态空间上的冻结速度场,从而在单一模型中统一文本到图像生成、局部编辑与全局编辑功能。
- 通过硬路由机制与学生 rollout 上的单次语义侧低噪声查询,解决跨能力冲突。该方法采用速度均方误差(MSE)目标进行优化,提供直接监督信号,无需依赖密集奖励优化或参数融合。
- 在文本到图像生成、编辑、真实感场吸收及无分类器引导吸收等方面的综合实验表明,该框架能够组合多项能力,在保持基线生成质量的同时提升目标性能,并超越单一教师模型。
引言
现代图像生成日益依赖流匹配模型,这些模型必须在单一部署系统中同时处理文本到图像合成、局部编辑和全局风格转换等多种能力。这种统一方法的重要性在于,它消除了对专用工具的需求,并简化了复杂的创意工作流。然而,这些任务在本质上存在对齐偏差,且经常相互干扰。以往依赖联合训练、参数融合或适配器组合的方法,通常面临梯度冲突、监督信号稀释或生成质量下降等问题。本文作者利用在线策略生成场蒸馏技术来解决这一问题,通过将样本路由至专用速度场,并使用简单的速度均方误差目标训练统一的学生模型。该框架使模型能够组合专家级能力、吸收外部引导算子,并在避免传统多任务训练典型干扰的同时,维持强劲的基线性能。
数据集
- 数据集构成与来源:所提供的摘录仅列出作者姓名与机构隶属关系,未提供数据集构成或来源信息。
- 各子集关键细节:文中未描述任何子集的大小、来源或过滤规则。
- 论文数据使用方式:所提供内容中未明确训练集划分、混合比例或处理流程。
- 裁剪策略与处理细节:摘录内容未提及任何裁剪策略、元数据构建或其他处理步骤。
方法
作者将多能力图像生成问题构建为一种在线策略生成场蒸馏框架。该方法并非通过静态参数插值或数据比例调优来融合冻结的能力源,而是将每个源视为共享生成状态空间上的确定性速度场。因此,能力组合被简化为场查询问题,需要在给定样本由哪个场监督、在状态空间的何处查询该场,以及利用多少个轨迹状态进行监督等方面做出协调决策。
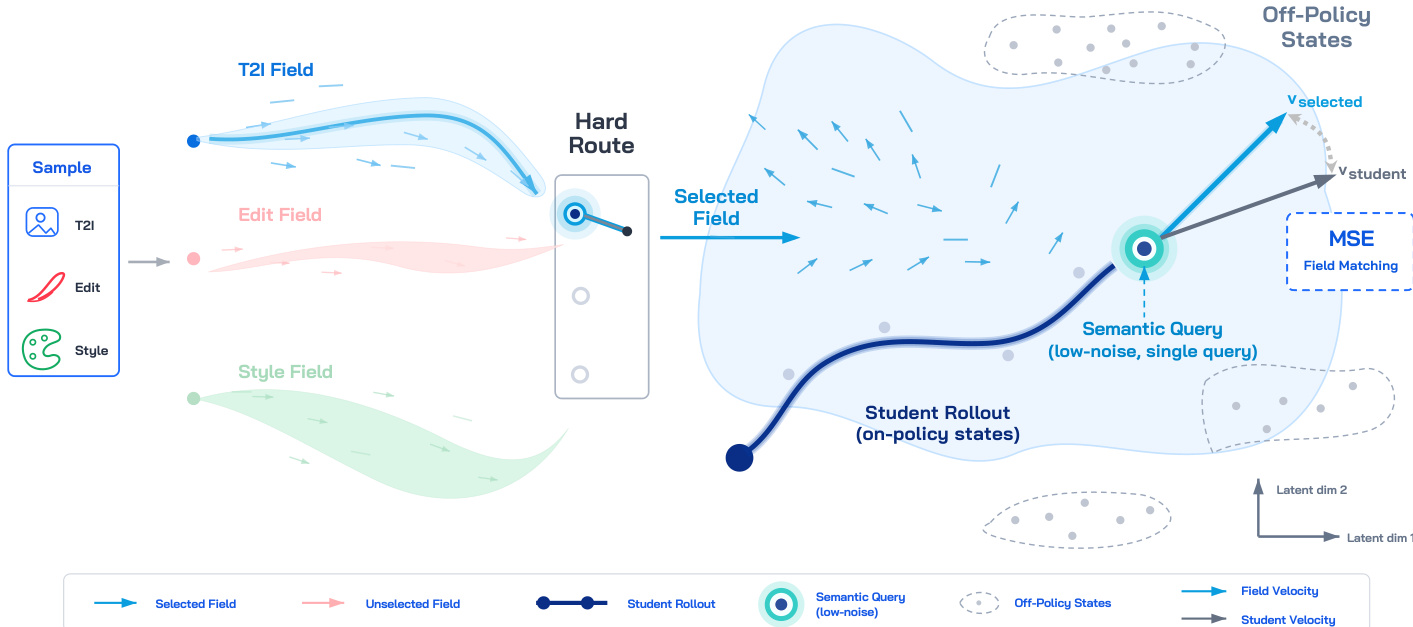
如图所示,训练过程始于采样一个能力源,并将对应的训练数据路由至特定的冻结速度场。为保持各能力的语义独立性并避免目标场歧义,该方法采用硬路由的样本级场匹配机制。每个样本仅被分配至单一能力场,确保监督信号对应明确定义的任务,而非多个场之间可能冲突的平均值。该路由策略保持了不同生成行为之间清晰的语义边界。
选定场后,框架通过在当前学生 rollout 上查询冻结场来解决状态分布不匹配问题。学生模型不依赖固定的离策略数据状态或教师诱导轨迹,而是从初始噪声自行生成轨迹。从该 rollout 轨迹中选取特定状态,并经过停止梯度(stop-gradient)操作,以防止梯度反向传播至整个求解器。这种在线策略查询使监督分布与学生推理过程中实际访问的状态对齐,有效缓解了协变量偏移问题。
为解决轨迹与查询的相关性问题,该方法避免在同一 rollout 的多个状态上进行密集监督。单条轨迹上的状态共享相同的条件、噪声种子与路径历史,导致梯度信号高度相关,从而可能使优化过程产生偏差。相反,框架在轨迹的低噪声区域采样单次语义侧查询。该区域集中了风格或编辑属性等能力特定信息,在保持计算效率的同时提供高信噪比的监督信号。
随后,学生模型通过最小化其预测速度与在停止梯度查询状态下评估的路由冻结场之间的基础速度均方误差(MSE)损失进行更新:
LDanceOPD=Em∼π,(x,c)∼Dm,zT∼pT,s∼qsem[∥vθ(zˉt,t,c)−vm(zˉt,t,c)∥22],t=t(s).该局部回归目标与流匹配模型生成的确定性速度场自然契合。从局部高斯转移视角来看,KL 风格的场匹配可简化为该加权 MSE 形式,使其成为速度蒸馏中稳定且具备理论依据的选择。相同的公式也可用于吸收算子定义的场(如无分类器引导),即将引导速度视为额外的能力场,并应用相同的匹配目标。
实验
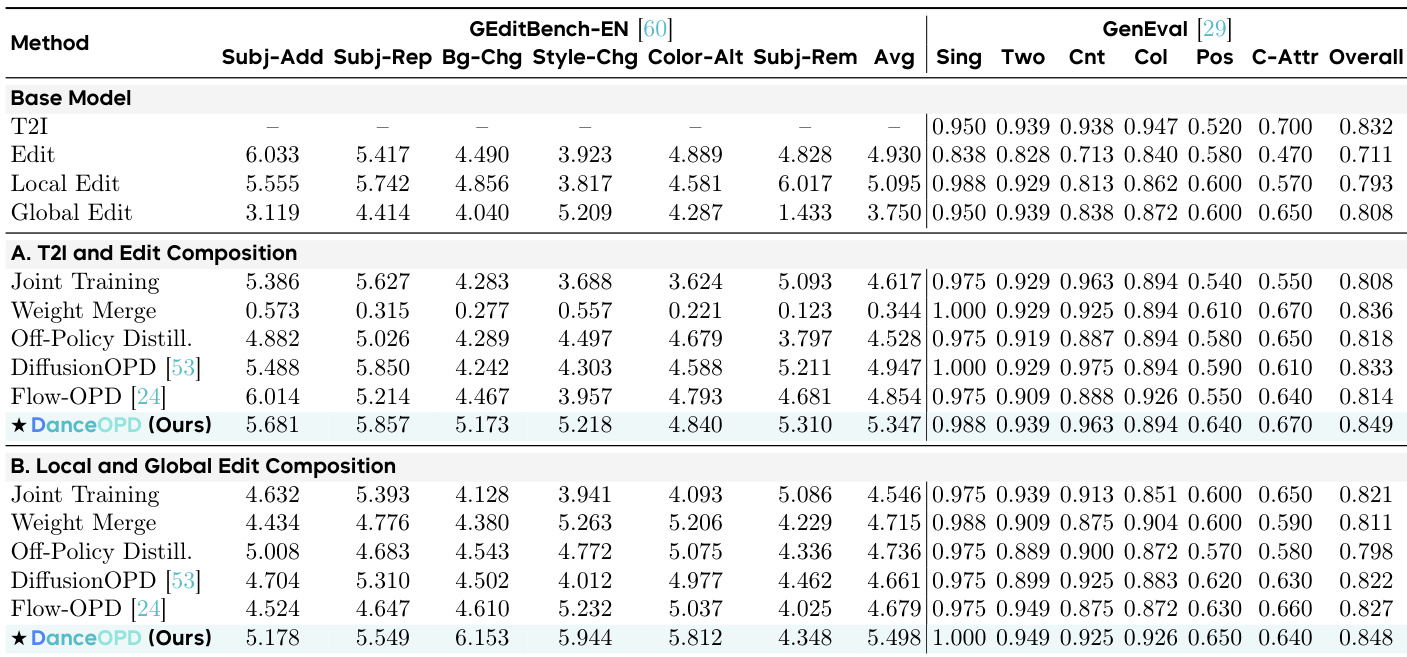
实验在文本到图像组合、编辑及场吸收设置下评估 DanceOPD,以验证单一学生模型能否在不陷入能力干扰的情况下整合异构生成能力。诊断性与定性分析表明,硬场路由、单次语义侧轨迹查询与针对性初始化成功保留了锚点能力并强化了目标技能;而软教师混合、密集同步监督及相关状态查询则持续导致性能下降。最终,该框架证明在查询级别隔离语义身份,为多能力模型蒸馏提供了一种稳定且高效的替代方案,优于传统的联合训练或权重融合方法。
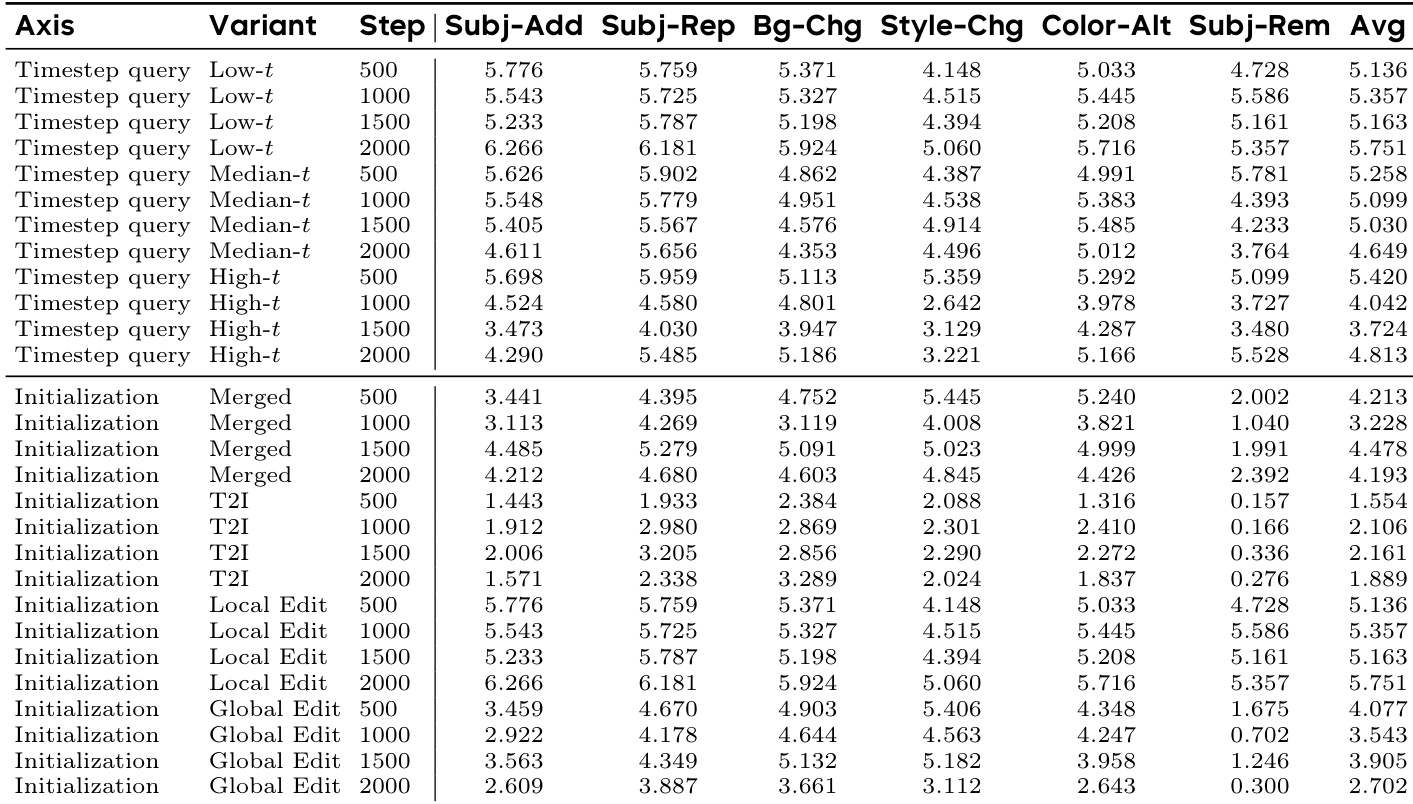
作者分析了查询时机与初始化方法对生成能力组合的影响。数据表明,与中步长或高步长相比,在较低时间步查询教师场始终能在各项编辑任务中产生更高的平均性能。此外,使用局部编辑检查点作为初始化策略,其结果显著优于融合策略或其他基线初始化方法。低时间步查询相较于中步长和高步长替代方案,实现了更优的性能。局部编辑初始化在性能上超越融合、文本到图像及全局编辑初始化基线。最优配置在训练后期步骤展现出稳健的性能,尤其在主体移除与背景更换任务中表现突出。
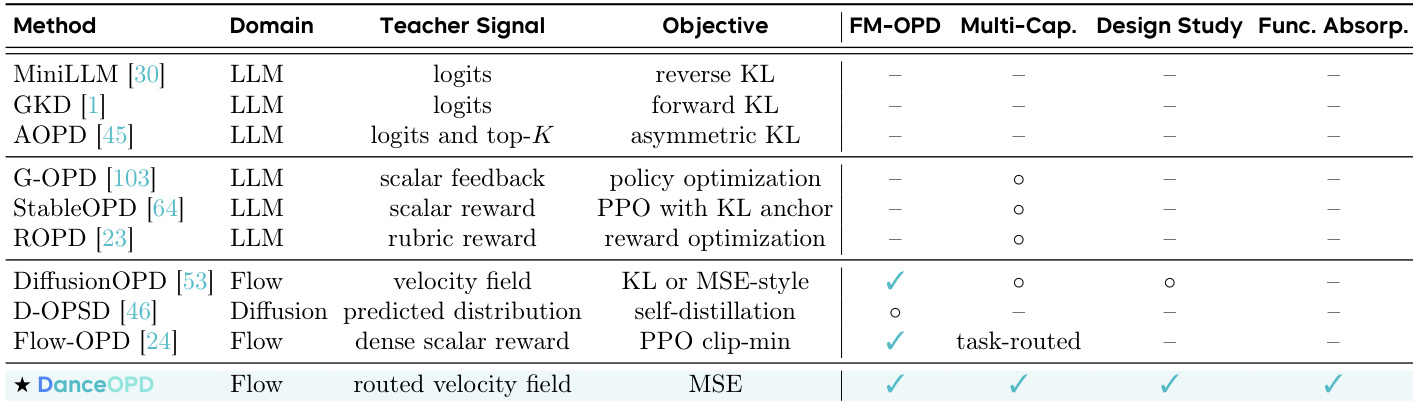
该表格将 DanceOPD 归类为基于流的方法,采用路由速度场与 MSE 目标,从而将其与聚焦大语言模型的方法及其他扩散技术区分开来。该方法支持流匹配在线策略蒸馏、多能力组合、设计研究及功能吸收。实验结果证实,DanceOPD 在保留锚点模型原始生成行为的同时,成功组合了异构能力并吸收了目标场。DanceOPD 在维持锚点能力的同时提升了目标能力性能,避免了联合训练或权重融合方法中常见的干扰现象。教师场的硬路由对于保留样本级语义身份至关重要,而软教师混合则会导致性能下降。每次 rollout 的单次语义侧查询比密集轨迹查询更有效,因为密集查询中的相关状态会放大冲突梯度。
作者评估了 DanceOPD 在组合异构能力场方面的表现,具体包括将文本到图像生成与图像编辑任务结合,以及合并局部与全局编辑能力。结果表明,该方法在保留锚点能力的同时有效强化了目标能力,其性能优于联合训练和权重融合等基线方法,后者往往重新引入能力干扰。DanceOPD 展现出卓越的能力组合能力,在保持基础生成质量的同时强化目标编辑技能,尤其在风格与背景更换等需要大幅视觉变换的类别中表现突出。在组合局部与全局编辑能力时,该方法相较于竞争基线获得了更高的平均编辑得分,表明其能在不牺牲整体生成性能的前提下有效处理冲突的编辑需求。实验强调,硬路由与单步查询对训练稳定性至关重要,因为软教师混合与密集轨迹监督会因能力冲突和相关查询噪声而导致性能下降。
实验分析了将吸收的引导与外部评估引导相结合对模型性能的影响。结果表明,适度组合这些比例可产生最佳的整体编辑能力,而过高的有效引导强度则会导致显著的性能下降。吸收引导与外部引导的适度组合取得了最高的平均得分。高有效引导强度导致各项编辑类别的性能大幅下滑。仅进行训练吸收的表现低于最优的适度组合设置。

作者评估了将多个能力场组合至单一学生模型的过程,重点关注不同的教师调度、目标函数与查询策略对性能的影响。结果表明,将教师信号硬路由至特定语义查询优于软混合,后者倾向于模糊各能力之间的独立身份。此外,每步 rollout 使用单次查询更新学生模型,其整体效果优于累积多次查询或使用密集轨迹监督,后者会引入相关噪声与能力干扰。教师场的硬路由比软混合更好地保留了语义身份,从而在各项编辑任务中获得更高的平均性能。每步单次查询更新优于同步累积,因为累积多个能力场会重新引入干扰。增加每次 rollout 的轨迹查询数量会导致性能下降,这表明相关状态会放大冲突梯度,而非使其稳定。
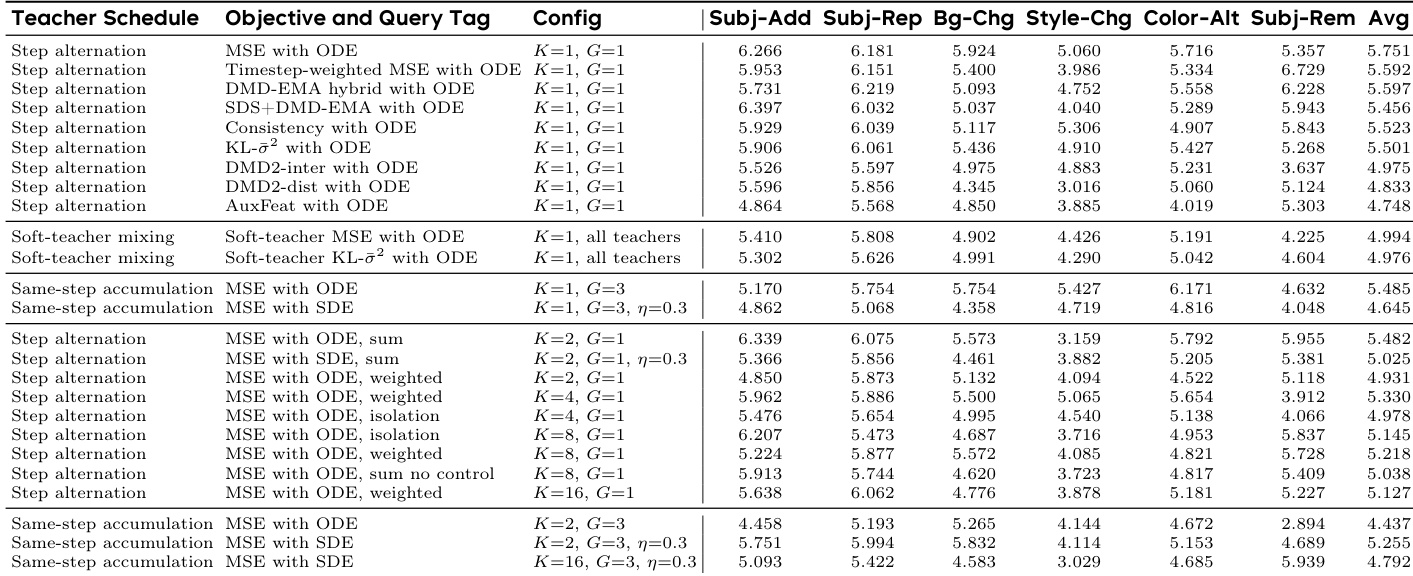
实验通过系统测试查询时机、初始化策略、路由机制与引导缩放,验证了 DanceOPD 框架组合异构能力场的能力。结果一致表明,教师信号的硬路由与每次 rollout 的单步查询能有效保留语义身份并防止能力干扰,而软混合与密集轨迹监督则通过冲突梯度导致性能下降。此外,使用局部编辑检查点以及吸收引导与外部引导的适度组合,能够产生最稳定的编辑结果,证实该方法在保留锚点模型原始生成行为的同时成功整合了多样化功能。