Command Palette
Search for a command to run...
ViQ:任意分辨率下的文本对齐视觉量化表征
ViQ:任意分辨率下的文本对齐视觉量化表征
Xumin Yu Zuyan Liu Zhenyu Yang Yuhao Dong Shengsheng Qian Jiwen Lu Han Hu Yongming Rao
摘要
文本与视觉的统一表示是一项自然追求,因为它能够实现更简单的多模态建模与更高效的训练。然而,将图像以与文本相同的方式表示为离散信号不可避免地会引入严重的信息损失。现有工作在离散表示中难以平衡低层细节与高层语义:以重建为导向的表示往往缺乏语义信息,而语义更强的特征通常面临严重的细节丢失问题。我们提出了ViQ(Visual Quantized Representations框架),该框架旨在平衡离散表示中的语义与细节,同时支持原生分辨率的输入,从而使其能够作为任意视觉输入的统一且通用的离散表示。我们的方法将量化学习结构化为两个阶段:文本对齐的预训练与特征离散化。借助文本对齐的预训练,我们利用预训练语言模型为视觉编码器提供更丰富的语义监督,并使其能够处理原生分辨率的视觉输入。在离散化过程中,我们提出了一种近端表示学习策略以逐步压缩特征空间,并配合一种位置感知的逐头量化机制,从而实现对任意分辨率的灵活处理。在多模态任务上的大量实验表明,与具有连续和高维视觉特征的最先进多模态视觉编码器相比,ViQ取得了具有竞争力的性能,同时在低层重建中保持了高精度。我们还表明,使用视觉量化表示进行多模态训练大幅提升了效率,在使用不同基础大语言模型(LLMs)和训练配置时,可实现高达20%-70%的加速。
一句话总结
ViQ 是一种视觉量化框架,通过结合用于原生分辨率处理的文本对齐预训练、近端表示学习策略以及位置感知的逐头量化方法,平衡了高级语义与低级细节,从而生成统一的离散表示,支持更简单的多模态建模,并在任意分辨率下实现更高效的训练。
核心贡献
- 本文提出了 ViQ,一种视觉量化表示框架,能够在离散格式中平衡低级细节与高级语义,同时原生支持任意输入分辨率。
- 该框架将量化学习结构化为文本对齐预训练和特征离散化两个阶段,采用近端表示学习策略压缩潜在空间,并利用位置感知的逐头量化机制保留分辨率灵活性。
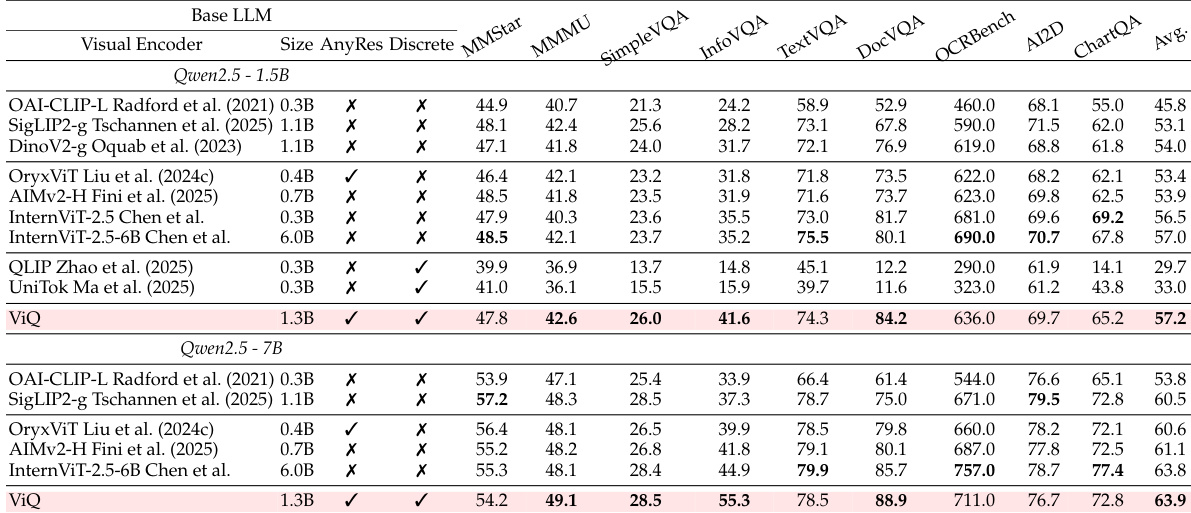
- 在九个多模态基准测试和图像重建任务中的评估表明,该框架优于现有的量化模型,性能可与 InternViT、AIMv2 和 SigLIP2 等连续编码器相媲美。在不同序列长度下,训练效率提升 20% 至 70%,同时重建保真度达到 PSNR 22.73 和 rFID 分数 0.62。
引言
多模态大语言模型受益于对齐视觉与文本的统一表示,这能够实现更简单的建模并提升训练效率。然而,连续的视觉特征与语言的离散 token 结构不匹配,且会带来高昂的计算成本;而现有的离散量化方法往往难以平衡高级语义与低级视觉细节。本文提出 ViQ,一种能够生成文本对齐视觉量化表示的框架,支持原生分辨率处理。通过结合文本对齐预训练、近端表示学习策略与位置感知的逐头量化方法,ViQ 在实现具有竞争力的多模态性能与重建保真度的同时,显著提升了训练速度。
方法
本文提出 ViQ,一种专为多模态学习设计的视觉量化框架,旨在连接原始像素与紧凑的潜在表示。该架构通过特定流水线处理任意分辨率的图像,将连续特征转换为离散编码。
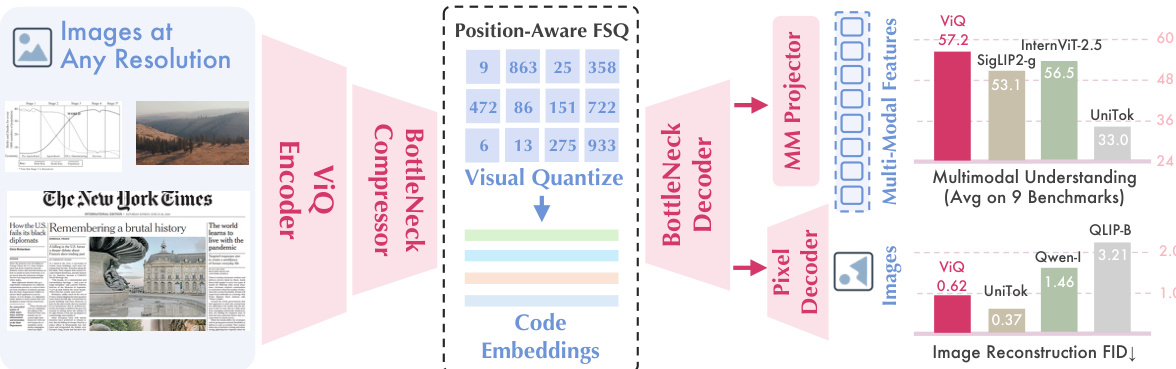
如架构图所示,输入图像首先经过 ViQ Encoder 提取高维特征。随后,这些特征通过瓶颈压缩器(Bottleneck Compressor)进行压缩。核心模块 Position-Aware FSQ 展示了量化过程,其中连续特征被映射为离散编码嵌入。瓶颈解码器(BottleNeck Decoder)随后重建这些嵌入。输出分支为两条路径:用于为语言模型生成多模态特征的 MM Projector,以及用于图像重建任务的 Pixel Decoder。
训练过程采用两阶段方法,以确保稳健的对齐与有效的量化。第一阶段,文本对齐预训练将视觉编码器与语言嵌入进行对齐。为支持原生分辨率输入,模型将固定的位置嵌入替换为可动态调整维度的缩放位置嵌入。优化目标结合了文本引导的交叉熵损失与自蒸馏损失。文本损失定义如下:
Ltext=Cross Entropy[LLM(ViQ(I), T), A]自蒸馏损失通过余弦相似度确保与固定分辨率教师模型的语义一致性:
Ldistill=1−cos(zsstudent,zsteacher)第二阶段涉及对连续特征的渐进式量化。
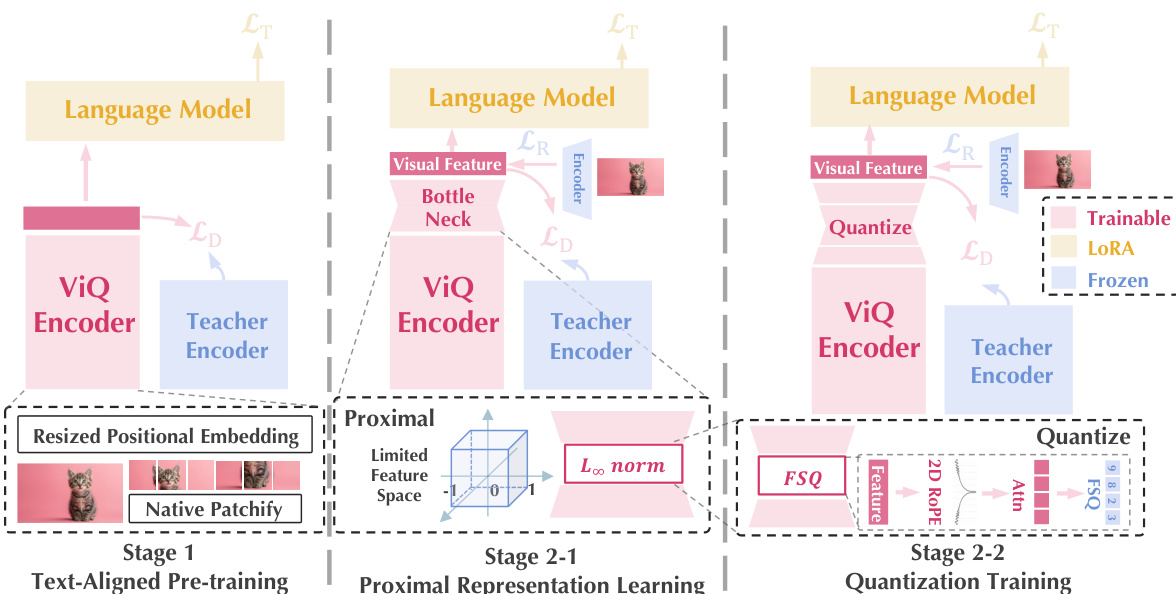
该阶段以近端表示学习开始。高维特征通过瓶颈层进行压缩,并使用 L∞ 范数约束至超立方体表面,以降低特征空间复杂度。特征变换公式如下:
f1=L∞(BN(f)),f^=BN′(f1)随后,模型采用多头有限标量量化(Multi-Head FSQ)。为增强表示能力,多头注意力机制将每个视觉图块扩展为 2×2 的编码网格。此外,应用二维旋转位置嵌入(RoPE)来编码空间分辨率信息:
f~m=fm⊙ei(hθh+wθw)为保留低级细节,训练过程引入了由预训练视觉自编码器监督的重建损失。总目标函数结合文本损失、蒸馏损失与重建损失:
Ltotal=λtextLtext+λdistillLdistill+λreconLrecon实验
评估将 ViQ 与不同规模的语言模型结合,并在综合理解任务、训练效率测试及图像重建流水线中,将其与通用、多模态专用及量化视觉编码器进行基准对比。实验验证了 ViQ 能够实现紧凑的视觉表示,在保持强大感知与语义能力的同时,尤其在以文本和文档为中心的任务中表现优异,并通过预计算的离散编码带来显著的训练加速。消融实验进一步证实,逐步正则化潜在空间、使用不可学习的码本以及结合针对性的重建损失,能够有效平衡低级保真度与高级对齐。总体而言,研究结果确立了 ViQ 作为一种高效的视觉编码器,成功在激进压缩与稳健的多模态理解之间取得平衡。
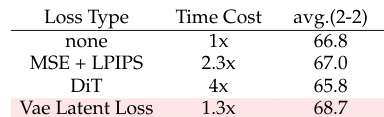
本文评估了不同的重建损失公式以优化训练过程。实验表明,VAE 潜在损失在性能上表现最佳,且比结合 MSE 与 LPIPS 的复杂替代方案更具计算效率。与其他损失类型相比,VAE 潜在损失取得了最高的平均性能。其所需的计算时间少于 MSE 与 LPIPS 的组合方案。其性能优于无特定损失的基线配置。
本文对比了 FSQ 与 SimVQ 量化方法在不同码本规模下的性能。结果表明,FSQ 始终优于 SimVQ,且减小码本规模能使两种方法均取得更好结果。FSQ 的平均性能高于 SimVQ。较小的码本规模提升了 FSQ 的性能。随着码本规模增大,SimVQ 的性能下降。

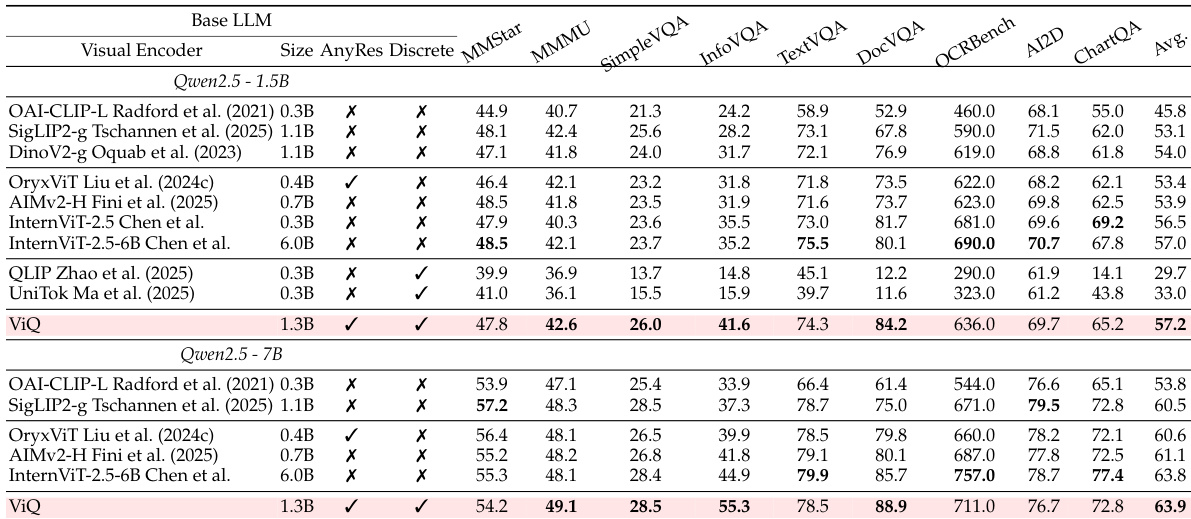
本文在多个多模态理解基准上评估 ViQ 与各类视觉编码器的对比,以检验其有效性。结果表明,ViQ 取得了具有竞争力的整体性能,经常持平或超越连续编码器,同时显著优于现有量化模型。其在文本与文档为中心的任务中表现出特别的优势,验证了其作为紧凑视觉表示的能力。在不同模型规模下,ViQ 的平均得分高于大多数连续视觉编码器。该模型在多模态理解基准上显著优于先前的量化基线。与其他编码器相比,ViQ 在文本与文档识别任务中展现出更优越的性能。
本文探讨了瓶颈宽度对模型在多个基准上平均性能的影响。结果表明,显著缩小的瓶颈宽度仍能达到与最宽配置相当的性能水平。这表明即使进行大幅降维,模型仍能保持稳健性与质量。较窄的瓶颈宽度可实现与最宽配置相似的性能。降低宽度不会导致显著的性能下降。尽管维度降低,模型仍保持较高的平均得分。

评估设置系统性地测试了关键训练与架构组件,验证了相较于复杂替代方案,VAE 潜在损失能同时优化重建质量与计算效率。量化分析显示,FSQ 始终优于 SimVQ,且较小的码本规模能进一步在两种方法中提升结果。在与标准视觉编码器进行基准对比时,提出的 ViQ 模型在多模态任务中持平或超越连续方法,同时显著优于先前的量化基线,尤其在文本与文档理解方面。最后,瓶颈宽度测试证实,大幅降维仍能保持整体性能,验证了该框架的稳健性与紧凑设计。