Command Palette
Search for a command to run...
Qwen-Image-Agent:弥合真实世界图像生成中的上下文差距
Qwen-Image-Agent:弥合真实世界图像生成中的上下文差距
摘要
尽管文本到图像(T2I)模型取得了显著进展,但在处理现实世界中通常表述不明确、隐含或依赖最新知识的请求时,仍面临挑战。我们将这一挑战定义为“上下文差距”(Context Gap):即用户上下文与T2I模型生成所需充分上下文之间的不匹配。为弥合这一差距,我们提出了Qwen-Image-Agent,这是一种统一的agent框架,以上下文为中心整合了规划、推理、搜索、记忆与反馈。Qwen-Image-Agent将用户输入视为部分上下文,并通过上下文感知规划(Context-Aware Planning)与上下文锚定(Context Grounding)逐步构建生成所需的上下文。具体而言,上下文感知规划负责识别缺失的上下文并规划其获取与使用方式,而上下文锚定则从推理、搜索、记忆与反馈中收集该上下文。为评估agent图像生成能力,我们进一步引入了Image Agent Bench(IA-Bench),该基准涵盖了四个核心image agent能力:规划、推理、搜索与记忆。在IA-Bench、Mindbench和WISE-Verified上的实验表明,Qwen-Image-Agent优于强大的基线模型,并达到了最先进的性能。
一句话总结
Qwen-Image-Agent 通过统一的 Agent 框架弥合了现实世界文本到图像生成中的上下文缺口。该框架结合上下文感知规划与上下文锚定,逐步融合推理、搜索、记忆与反馈机制,从而在 IA-Bench、Mindbench 和 WISE-Verified 基准测试中取得最先进的性能。
核心贡献
- Qwen-Image-Agent 是一种免训练的 Agent 框架,通过整合规划、推理、搜索、记忆与反馈机制,弥合了文本到图像生成中的上下文缺口。该系统借助上下文感知规划与上下文锚定,逐步构建充足的生成上下文,以应对未明确指定或隐含的用户需求。
- IA-Bench 利用 17 项真实任务、730 个测试实例和 1801 项细粒度检查清单,系统性地评估了 Agent 图像生成在规划、推理、搜索与记忆方面的能力。结构化的视觉语言模型评估协议确保了这些核心 Agent 功能的可靠评估。
- 在 IA-Bench、MindBench 和 WISE-Verified 上的实验表明,Qwen-Image-Agent 显著优于强大的 Agent 基线模型,并达到最先进的性能。消融实验证实,整合多种锚定上下文来源可在生成质量与任务完成度上带来互补性提升。
引言
文本到图像模型发展迅速,但其在营销与产品设计等实际领域的应用仍受限于根本性错配:模型训练使用的显式提示词与用户实际提交的未明确指定、依赖知识的请求之间存在差异。先前研究曾探索规划、推理或网络搜索等独立的 Agent 能力,但这些努力仍较为零散,未能系统性地获取并整合现实世界生成所需的缺失上下文。本文通过 Qwen-Image-Agent 弥合了这一鸿沟。该统一框架通过上下文感知规划与多源锚定,逐步构建完整的生成上下文。该框架利用推理、网络搜索、记忆与迭代反馈,将不完整的用户输入转化为完全指定的生成条件。为验证该方法的有效性,研究团队同时推出了 IA-Bench,用于系统评估 Agent 能力,并在多项基准测试中展示了最先进的性能。
数据集
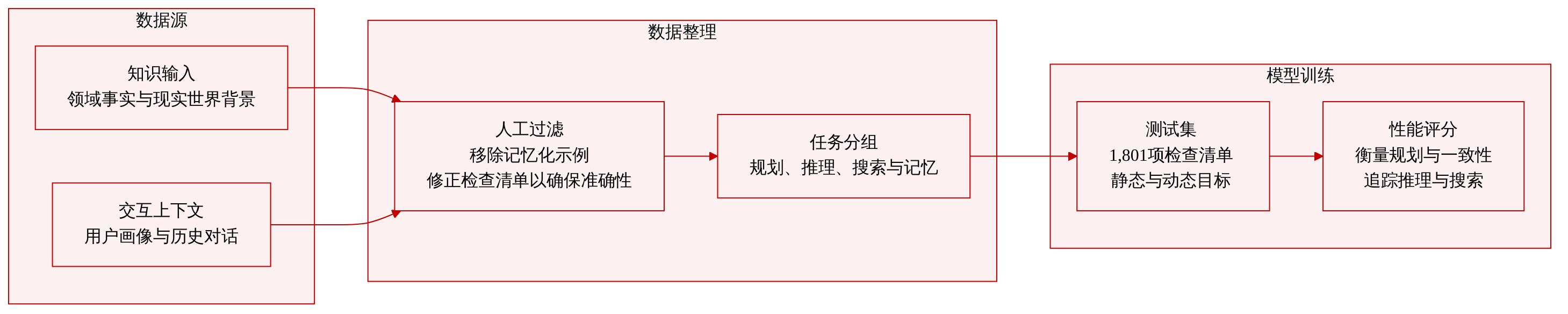
- 数据集构成与来源: 研究团队推出了 IA-Bench,这是一个旨在全面评估图像生成中 Agent 能力的基准测试。该数据集包含 730 个实例,划分为四项主任务与十七项子任务,并配有 1801 项评估检查清单。数据来源于领域知识、物理常识、逻辑与时空推理、外部世界知识以及交互式对话上下文。
- 各子集关键细节:
- 规划任务(组合、枚举、多面板)侧重于将高层目标分解为结构化布局,并满足多对象约束。
- 推理任务(数学、科学、常识、迷宫、地图、几何)测试逻辑、常识与视觉推理能力,以便在渲染前推断潜在约束。
- 搜索任务(IP 实体如游戏与名人,以及信息如股票与天气)评估检索与锚定外部或实时知识的能力。
- 记忆任务(用户画像与对话历史)评估跨轮次一致性以及对持久用户属性或历史对话的保留能力。
- 数据使用方式: 本文仅将 IA-Bench 作为评估框架,用于衡量规划、推理、搜索与记忆能力。该数据集未用于模型训练、微调或数据混合,也未使用任何训练集划分或混合比例。
- 处理与构建细节: 该基准测试依赖细致的人工标注以平衡质量与难度。研究团队过滤掉了可通过记忆或预训练视觉先验解决的实例,例如移除那些模型无需外部搜索即可生成的高度标志性角色。评估检查清单最初由 LLMs 生成,随后经过人工校对以确保准确性与必要性。针对记忆导向任务,研究团队实施了动态评估检查清单,其参考目标会根据先前生成的图像动态调整,而非依赖静态真实标签。所有子任务均经过可行性验证,并最大程度降低了评估歧义。
方法
研究团队采用条件渲染公式,明确处理不完整用户输入与图像生成器所需完整上下文之间的差异。为解决这一上下文缺口,该框架将图像生成器视为渲染器,并引入迭代式上下文构建流程。在每一步中,agent 维护一个状态 st=(ct,Ot−1),表示当前上下文与累积观测值,从定义的操作空间中选择一个动作 at,并接收观测值 ot。该交互过程形成一条轨迹 τ={(st,at,ot)}t=1T。整体生成过程的数学表达如下:
pagent(y∣cu)=τ∑p(τ∣cu)pgen(y∣cg=c(τ))在此框架下,agent 在执行最终渲染步骤前逐步构建生成上下文。
该架构围绕两个核心模块构建:上下文感知规划与上下文锚定。上下文感知规划在三个层级上运行,以系统化管理信息流。信息级规划识别缺失的上下文元素,并将特定查询路由至合适的锚定策略。内容级规划整合检索到的信号,并将初始提示词重写为详细规范,明确界定主体、属性、布局、风格与文本元素。生成级规划处理多轮次与多图像工作流的上下文分配,通过过滤相关历史信息并在依赖图像间分配上下文,缓解内容漂移问题。
上下文锚定通过四种独立机制收集并结构化缺失信息。推理锚定利用视觉语言模型,通过常识、逻辑与视觉推理推断隐含意图,将未明确指定的请求转化为具体上下文项。搜索锚定通过提取关键词、执行网络查询,并利用视觉语言模型对结果进行排序与保留,从而检索外部事实知识或视觉参考。记忆锚定通过整合对话历史、更新用户画像,并使用专用检索器查询外部多模态知识库,在长程交互中保持连续性。反馈锚定通过依据预定义属性检查清单评估生成输出,从而闭合迭代循环。视觉语言模型对每项结果进行评估,任何差异均被转化为反馈信号,并与现有上下文合并,以优化后续生成轮次的提示词。
实验
评估采用基于检查清单的 VLM 协议,在三个独立基准测试上系统评估规划、推理、搜索与记忆能力,并与大量专有及开源基线模型进行对比。定量与定性分析表明,所提出的 Agent 框架通过渐进式信息锚定与迭代优化,有效弥合上下文缺口,显著优于直接生成模型。消融实验进一步验证了持续的性能表现依赖于强大的多模态语言主干、精心构建的上下文输入以及高效的图像渲染器。最终,研究结果强调了智能上下文管理在复杂图像合成中的必要性,同时指出了处理隐含需求、多轮上下文限制与计算效率方面仍面临的挑战。
研究团队在 IA-Bench 基准上对图像生成模型进行评估,对比了闭源、开源及 Agent 方法。结果表明,提出的 Qwen-Image-Agent 取得了最高的整体 IA 得分,显著优于 Qwen-Image-2.0 等直接生成基线及其他 Agent 模型。该 Agent 框架在规划、推理与搜索能力上展现出显著提升,而闭源模型在记忆性能方面仍保持明显优势。在所有评估模型中,Qwen-Image-Agent 的整体 IA 得分最高。与直接生成基线 Qwen-Image-2.0 相比,该 Agent 框架大幅提升了性能。Agent 模型在规划、推理与搜索维度上普遍优于直接生成模型。
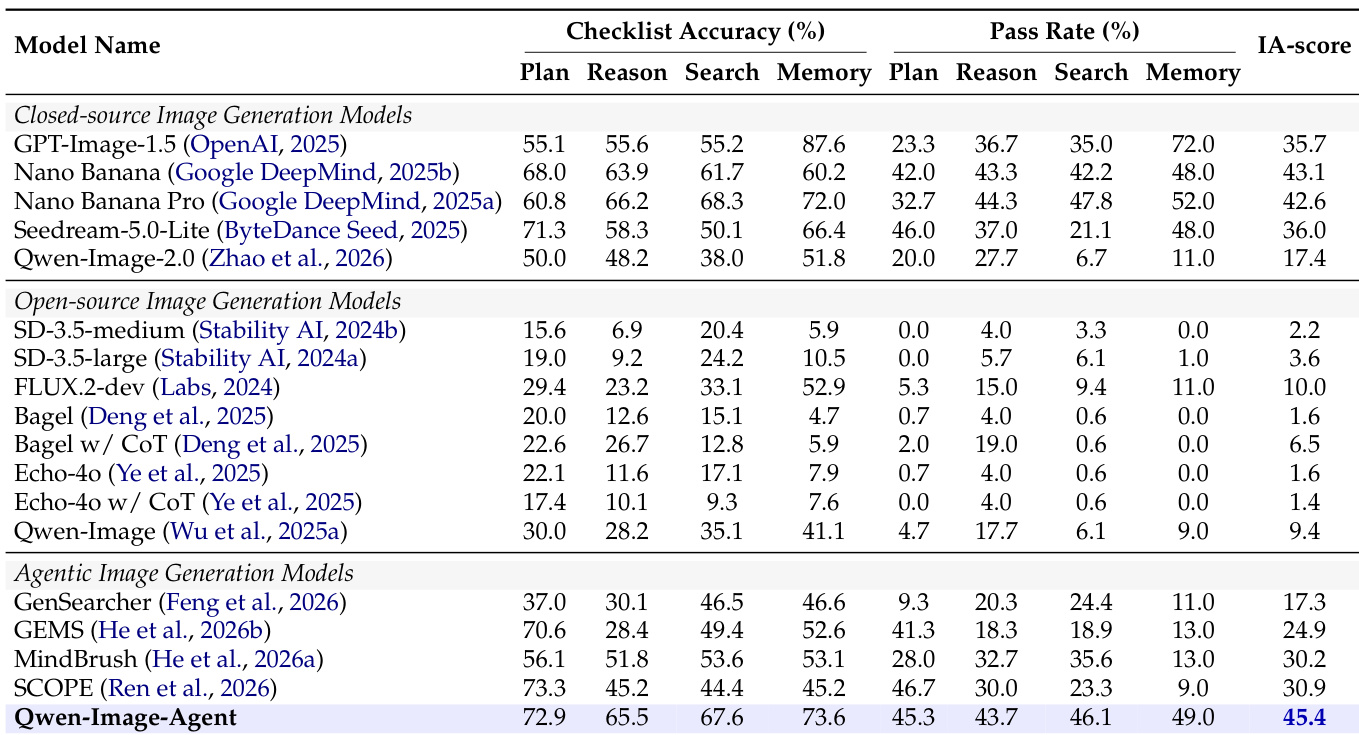
在 IA-Bench 上的评估结果展示了 Qwen-Image-Agent 相较于大量专有与开源基线模型的优越性能。该模型取得了最高的整体得分,在知识驱动与推理驱动任务中均显著优于 Nano Banana Pro 和 GPT-Image-1.5 等强大的闭源模型。Qwen-Image-Agent 的整体 IA 得分最高,超越了领先的专有模型。该模型在知识驱动与推理驱动能力上展现出显著提升。Agent 框架相比直接生成基线 Qwen-Image-2.0 大幅提升了性能。
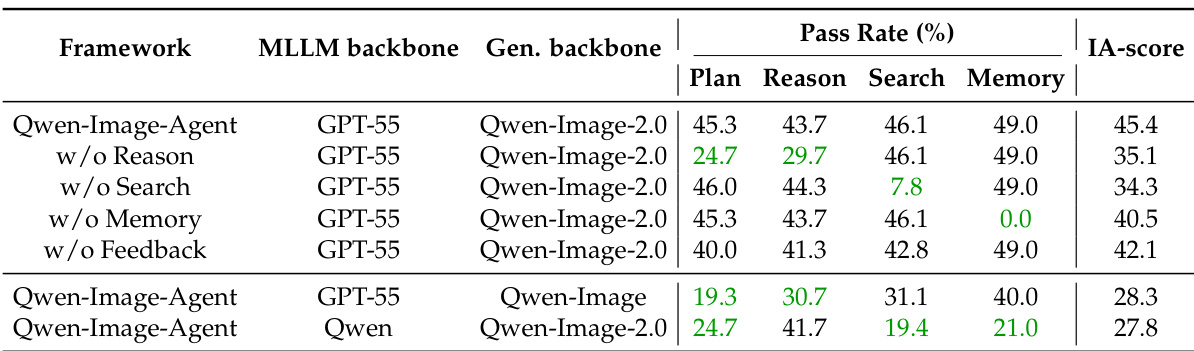
研究团队开展了消融实验,以验证 Qwen-Image-Agent 框架中各特定组件的贡献。结果表明,完整系统显著优于消融版本,移除任意锚定上下文均会导致对应评估维度的明显下降。此外,使用较弱的替代模型替换 MLLM 或生成主干会一致地降低各项指标的性能。移除记忆上下文会导致记忆维度性能完全崩溃。搜索组件对搜索能力至关重要,移除该组件会导致特定指标急剧下降。使用较弱模型替换 MLLM 或生成主干会导致所有评估能力的一致性性能衰退。
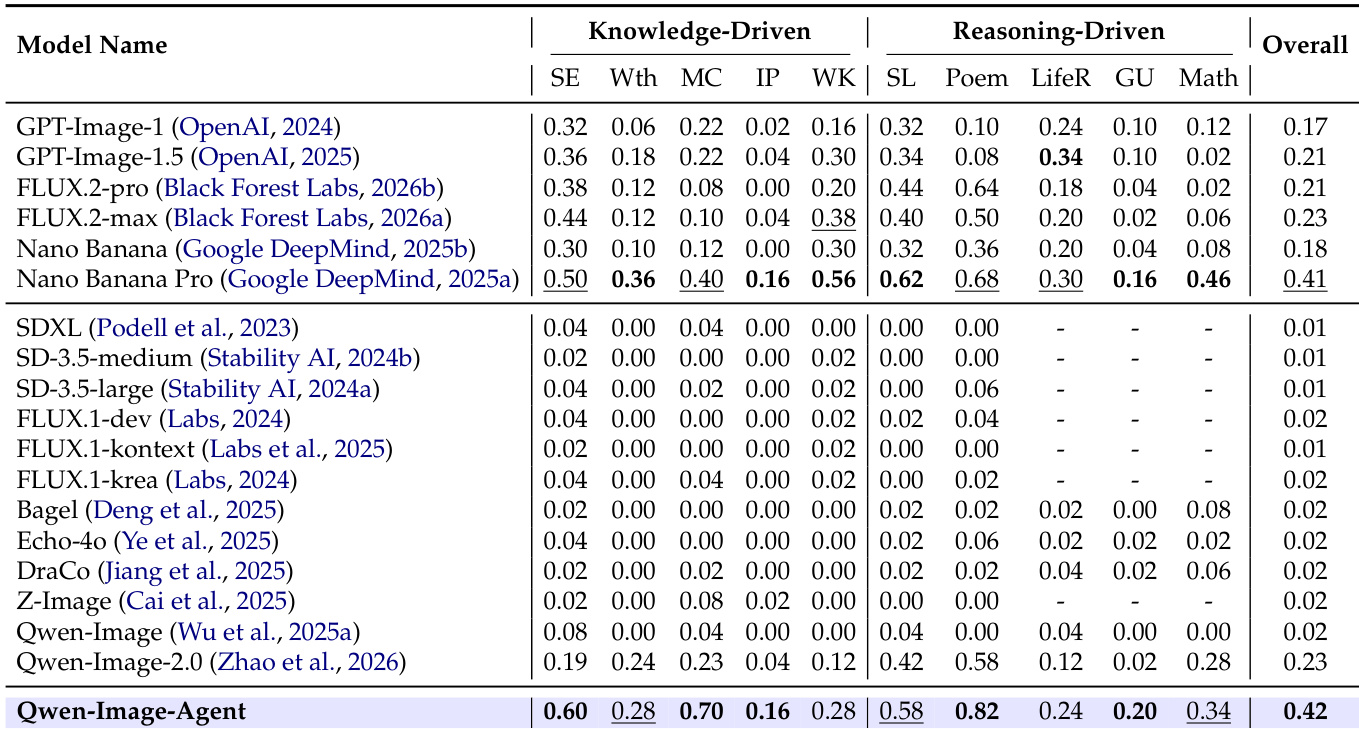
研究团队对 Qwen-Image-Agent 与各类专有及开源基线模型进行了对比评估,以衡量其语义理解与世界知识能力。结果表明,Qwen-Image-Agent 在文化、时间、空间、生物、物理与化学等所有类别中均取得最高性能。该模型显著优于 Nano Banana Pro 和 GPT-Image-1.5 等强大的闭源模型,验证了所提出 Agent 框架的有效性。Qwen-Image-Agent 取得最高整体得分,超越包括 Nano Banana Pro 和 GPT-Image-1.5 在内的所有其他模型。该模型在生物、物理与化学等具体知识领域均展现出一致的优势。Agent 框架相比 Qwen-Image-2.0 等直接生成基线实现了显著提升。
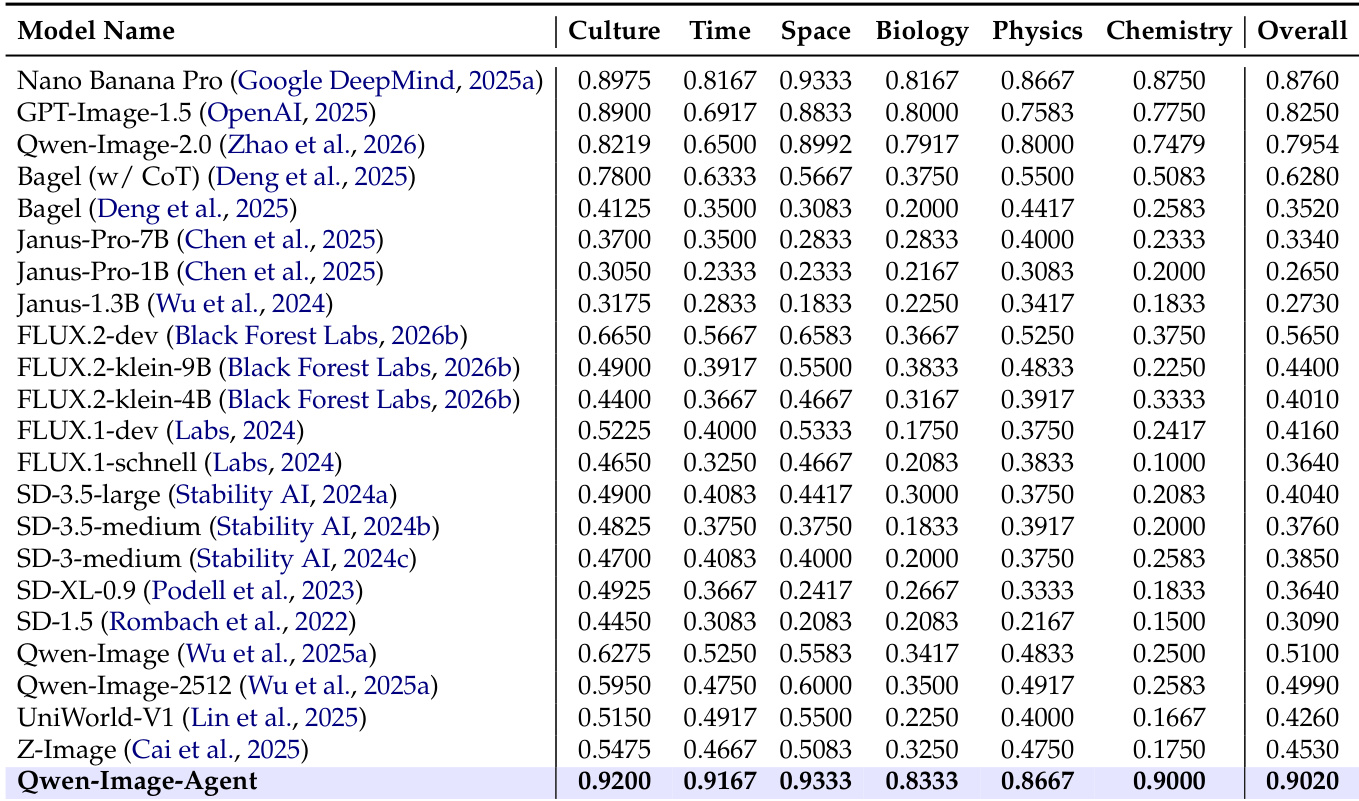
在 IA-Bench 基准测试中,Qwen-Image-Agent 与直接生成基线、其他 Agent 方法及领先专有模型进行对比,同时消融实验验证了其核心架构组件的必要性。基准评估表明,Agent 框架显著增强了规划、推理、搜索与领域专业知识能力,在定性上确立了相对于直接生成方法的明显优势。组件分析证实,每个模块对于在所有评估维度上维持稳健性能均不可或缺。最终,该模型在知识与推理任务中实现了持续的优势,尽管专有基线在记忆保留方面仍保有相对优势。