Command Palette
Search for a command to run...
OPID:面向智能体强化学习的同策略技能蒸馏
OPID:面向智能体强化学习的同策略技能蒸馏
摘要
基于结果的强化学习为语言agent提供了稳定的优化骨干,但其稀疏的轨迹级奖励对应当强化或抑制哪些中间决策提供的指导十分有限。在线自蒸馏提供了密集的token级监督,然而现有的技能条件变体通常依赖外部技能记忆或检索到的特权上下文,这些内容不仅维护成本高昂,且可能与多轮交互中当前策略所诱导的状态分布不匹配。我们提出了OPID(在线技能蒸馏),该框架直接从已完成的在线轨迹中提取技能监督信号。OPID将轨迹后验信息表示为分层技能:回合级技能捕捉全局工作流或避错规则,而步级技能捕捉关键时间步的局部决策知识。关键优先路由机制在识别出关键决策时调用步级技能,否则回退至回合级技能作为默认指导。选定的技能被注入交互历史中,使旧策略能够在原始上下文与技能增强上下文两种条件下对同一采样响应重新进行评分。由此产生的对数概率偏移形成token级自蒸馏优势,该优势与结果优势相结合用于策略优化。因此,OPID在将强化学习(RL)保留为主要训练目标的同时,引入了密集且与分布匹配的后验监督信号。在ALFWorld、WebShop及基于搜索的问答任务上的实验表明,相较于仅基于结果的强化学习与现有的技能蒸馏基线方法,OPID普遍提升了agent的性能、样本效率与鲁棒性。我们的代码已开源,地址为:https://github.com/jinyangwu/OPID/tree/main。
一句话总结
作者提出了OPID,一个on-policy技能蒸馏框架,从已完成的on-policy轨迹中提取episode-level和step-level技能,并使用关键优先路由机制将适当的技能注入交互历史,使得旧策略能够在原始和技能增强的上下文中重新评分同一响应,从而在没有外部技能记忆的情况下提供密集的token级监督,并指导多轮强化学习中的中间决策。
核心贡献
- On-policy后见之明技能提取从当前策略采样的已完成轨迹中获取技能监督,消除了对外部技能记忆的需求,并保持指导分布匹配。
- 分层技能表示编码了episode-level的全局工作流或失败避免规则,以及step-level的关键局部决策,并结合关键优先路由机制,为每个轨迹步骤选择最具体的技能。
- 基于技能的自蒸馏被集成到结果驱动的强化学习中,将路由后的后见之明技能转换为密集的token级塑造信号,同时保留主要的结果奖励目标;在ALFWorld、WebShop和基于搜索的QA上的评估显示,与仅结果RL和技能蒸馏基线相比,持续取得收益,同时提高了样本效率,减少了重复或无效行为。
引言
大型语言模型越来越多地被部署为交互式Agent,它们必须对长序列的工具调用和环境观察进行推理,这使得使用基于结果的强化学习(例如GRPO)进行后训练具有吸引力,因为它直接优化任务成功。然而,这种结果奖励是稀疏且延迟的,只提供粗粒度的轨迹级反馈,而没有对单个决策的细粒度归因。先前的工作通过从技能或特权上下文中蒸馏token级指导来解决这一问题,但现有的技能条件方法依赖于需要仔细维护的外部技能库,并且经常检索到与当前策略状态分布不匹配的技能。作者提出了OPID(On-Policy Skill Distillation),这是一个直接从当前策略产生的轨迹中提取分层后见之明技能(episode-level工作流和step-level关键指导)的框架。它使用关键优先路由机制将最相关的技能注入Agent的上下文,从产生的对数概率偏移中计算token级自蒸馏优势,并将其与结果奖励结合进行优化,从而在推理时无需任何外部检索或特权上下文的情况下密集化监督。
数据集
作者在三个Agentic领域使用独立的数据集进行评估,每个数据集都有自己的训练划分。对于具身推理,使用ALFWorld,一个基于文本的家庭环境。对于网页导航,依赖WebShop,一个模拟的电子商务设置。对于搜索增强的问答,整合了多个知识密集型QA基准到一个统一的检索增强设置下。
每个子集的关键细节:
- ALFWorld:从六种任务类型(Pick, Look, Clean, Heat, Cool, Pick2)中采样的2,400个训练示例。Agent接收自然语言目标和文本观察,并必须产生可接受的动作序列。
- WebShop:从产品搜索和购买环境中采样的2,400个训练示例。性能通过归一化的任务完成分数和二值精确匹配成功信号来衡量。
- 搜索增强的QA:从Natural Questions、TriviaQA、PopQA、HotpotQA、2WikiMultiHopQA、MuSiQue和Bamboogle中抽取的19,200个训练示例。Agent在生成最终答案之前与搜索环境交互,遵循Search-R1协议。
训练设置与数据处理:
- 训练是针对每个基准设置单独进行的,这意味着模型不在跨领域混合数据上训练。
- 除了采样步骤外,没有描述额外的裁剪策略、元数据构建或过滤;原始数据集结构被保留,采样大小直接决定了每个领域的训练语料库。
方法
作者提出了OPID(On-Policy Skill Distillation),一个将已完成的on-policy轨迹转换为分层技能,并将其行为效应蒸馏回策略的框架。整体流程如下图所示。
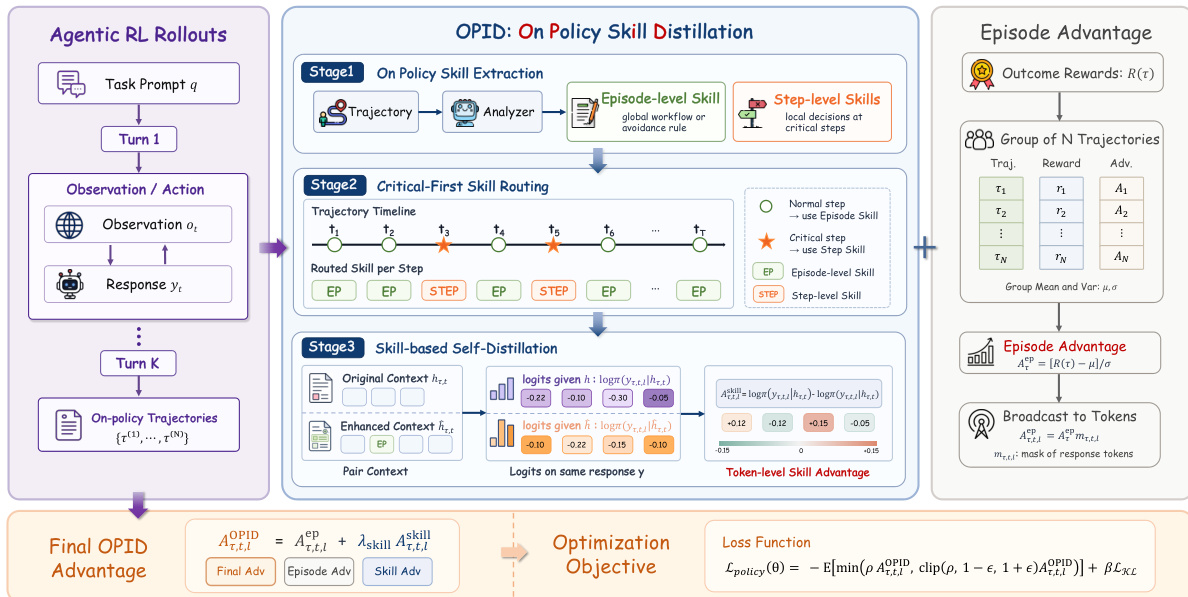
OPID在三个主要阶段执行on-policy技能蒸馏。首先,从已完成的on-policy轨迹中提取分层技能。其次,将适当的技能路由到每个决策步骤,并将技能效应转换为token级自蒸馏信号。第三,将这些token级技能优势与组相对结果优势结合,用于策略优化。
问题表述 作者将一个Agentic任务建模为由(S,A,O,T,R,γ)定义的部分可观测马尔可夫决策过程。在时间步t,Agent维护一个交互历史ht=(o0,y0,o1,y1,…,ot),其中yi表示在第i步生成的文本响应或可执行动作。策略πθ生成下一个响应为yt∼πθ(⋅∣ht)。一个完整的轨迹表示为τ={(ot,yt,rt)}t=0T−1。遵循GRPO风格的训练,对于每个任务提示q,从当前策略中采样一组N个轨迹:Gq={τ(1),τ(2),…,τ(N)}。
On-Policy技能提取 结果奖励揭示了轨迹是否成功,但未揭示原因。OPID将事后轨迹知识表示为从已完成的on-policy rollout中提取的分层技能。该层次结构包含两个互补的级别:
- Episode-level技能(sτep):总结完整轨迹的全局行为模式。对于成功轨迹,它们捕获可重用工作流;对于失败轨迹,它们捕获失败避免规则。
- Step-level技能(sτ,tstep):捕获在关键时间步的局部决策知识,在这些时间步最终结果强烈依赖于特定选择。
给定一个完整的轨迹τ,一个基于LLM的分析器A将轨迹记录映射到结构化的自然语言技能。该分析器使用的提示如下图所示。

分析器输出A(τ)=(sτep,{sτ,tstep}t∈Cτ),其中Cτ是由分析器识别的关键时间步的稀疏集合。
关键优先技能路由 将相同技能应用于每一步是次优的。Episode-level技能稳健但在决定性状态下可能过于粗糙,而step-level技能精确但稀疏。OPID引入了关键优先技能路由机制。对于轨迹τ和时间步t,路由的技能为:
sτ,t={sτ,tstep,sτep,if t∈Cτ,otherwise.这确保了在关键状态下优先使用step-level技能,而在其他情况下episode-level技能作为默认指导。
基于技能的自蒸馏 路由后,OPID将选定的技能转换为token级自蒸馏监督。令H(⋅,⋅)表示一个确定性技能注入函数,它将路由的技能追加或预置到交互历史中。技能增强的历史为h~τ,t=H(hτ,t,sτ,t)。
旧策略πθold在原始和技能增强的两种历史下对相同的采样响应yτ,t进行评分。对于响应yτ,t中的token ℓ,对数概率为:
ℓτ,t,ℓold=logπθold(yτ,t,ℓ∣hτ,t,yτ,t,<ℓ) ℓτ,t,ℓskill=logπθold(yτ,t,ℓ∣h~τ,t,yτ,t,<ℓ)基于技能的自教师优势定义为:
Aτ,t,ℓskill=(ℓτ,t,ℓskill−ℓτ,t,ℓold)mτ,t,ℓ其中mτ,t,ℓ∈{0,1}是有效响应token掩码。如果Aτ,t,ℓskill>0,则选定的技能使该token更可能被生成,表明与技能一致。
结合技能优势的策略优化 对于每个rollout组Gq,组相对结果优势通过在其提示组内归一化轨迹结果奖励R(τ)来计算:
Aτep=σqR(τ)−μq,τ∈Gq其中μq和σq是组奖励的均值和标准差。该标量被广播到所有有效响应token:Aτ,t,ℓep=Aτepmτ,t,ℓ。
最终的OPID优势将组相对结果反馈与token级技能监督相结合:
Aτ,t,ℓOPID=Aτ,t,ℓep+λskillAτ,t,ℓskill作者优化标准的裁剪策略目标:
Lpolicy(θ)=−Eτ,t,ℓ[min(ρτ,t,ℓ(θ)Aτ,t,ℓOPID,clip(ρτ,t,ℓ(θ),1−ϵ,1+ϵ)Aτ,t,ℓOPID)]+βLKL(θ)其中ρτ,t,ℓ(θ)表示token级重要性比率。该公式保持结果奖励作为主要的RL信号,同时添加token级塑造。在推理时,学习到的策略仅从普通交互历史中行动,无需分析器调用或技能检索。
实验
在ALFWorld、WebShop和基于搜索的QA上,与提示、仅结果RL和混合基线相比,OPID一致地改进了GRPO,并匹配或超过了最强的蒸馏方法,同时将后见之明技能内部化,使得策略在推理时不再依赖于技能提示。训练动态揭示了加速的策略精炼,动作轨迹更短、更直接,并且该方法通过学习可重用的行为结构,带来了显著的样本效率提升和跨领域泛化。消融实验证实,结合episode-level和step-level技能与关键优先路由有效地将监督瞄准决策点,优于均匀指导,并验证了分层技能粒度的互补作用。
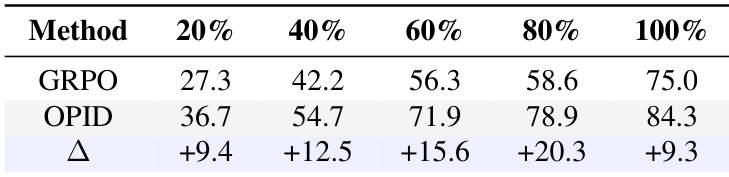
作者通过在ALFWorld基准上比较OPID和GRPO在不同训练数据比例下的表现来评估样本效率。结果显示,OPID在所有数据规模下都一致地优于GRPO,性能差距在中等数据区域显著扩大。值得注意的是,在数据子集上训练的OPID达到了与在全数据集上训练的GRPO相当或更好的性能,证明了通过技能监督提高了数据效率。OPID在所有测试的训练数据比例下都一致地实现了比GRPO基线更高的成功率。OPID相对于GRPO的性能优势在中等数据区域最为明显。OPID通过在使用减少的数据集训练时匹配或超过GRPO的全数据性能,展示了强大的样本效率。
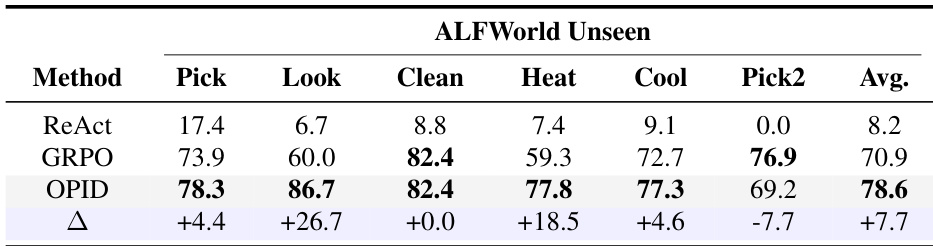
作者在ALFWorld基准的一个未见过的划分上评估跨领域泛化,以证明所提出的方法捕获了可重用的行为结构,而不仅仅是记忆训练轨迹。结果显示,该方法在平均情况下一致地优于仅结果强化学习基线,在特定任务类型如Look和Heat上有特别显著的改进。所提出的方法在所有未见过的任务类型上实现了最高的平均成功率,显著优于强化学习基线。相对于基线的性能提升在Look和Heat任务中最为明显,表明高级任务工作流和局部决策规则的强迁移。虽然该方法在大多数任务类别上提高了性能,但在Pick2任务上显示出混合结果,表明在泛化方面存在一些任务特定的局限性。
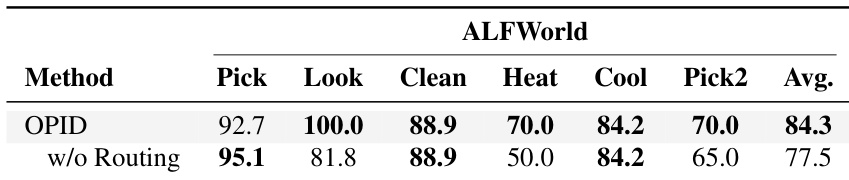
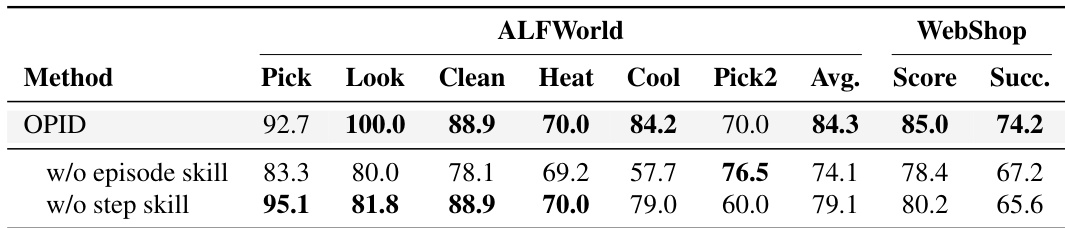
作者进行了一项消融研究,以评估关键优先技能路由对ALFWorld基准的影响。结果表明,具有路由的完整模型相比于没有路由的变体实现了更高的平均成功率。这证明了选择性地应用最合适的技能粒度的比简单地在所有步骤组合全局和局部指导更有效。完整模型在ALFWorld任务的整体平均成功率上优于无路由变体。路由机制在特定任务类型如Look和Heat上提供了显著的收益,而无路由变体在Pick任务上表现略好。选择性地路由技能被证明比在每个时间步叠加episode-level和step-level指导更有效。
作者进行了一项消融研究,以评估分层技能粒度的对Agent性能的影响。结果显示,完整的episode-level和step-level技能层次在ALFWorld和WebShop两个基准上都取得了最佳的总体性能。移除任一技能级别都会导致成功率明显下降,证明了全局工作流和局部决策指导的互补性。完整的分层技能设置优于缺少episode-level或step-level技能的变体。移除episode-level技能导致性能显著下降,表明全局工作流提供了重要的默认信号。移除step-level技能也会降低性能,证实了在关键决策点的精确指导对于最佳结果是必要的。
作者在多个Agentic基准和模型规模上评估OPID,证明它一致地加强了仅结果强化学习。结果显示,OPID通过将后见之明技能内部化到策略中,而不是在推理时依赖它们,匹配或超过了强大的混合和自蒸馏基线。OPID在大多数模型和领域组合中一致地优于仅结果GRPO基线,在长时程具身和网页购物任务上取得了特别大的收益。该方法在几个基准上取得了最高的总体性能,与使用辅助token级或技能条件监督的混合训练方法有效竞争。与在验证期间依赖技能提示的方法不同,OPID成功地将轨迹衍生的知识转移到模型参数中,在没有外部技能上下文的情况下保持强大性能。
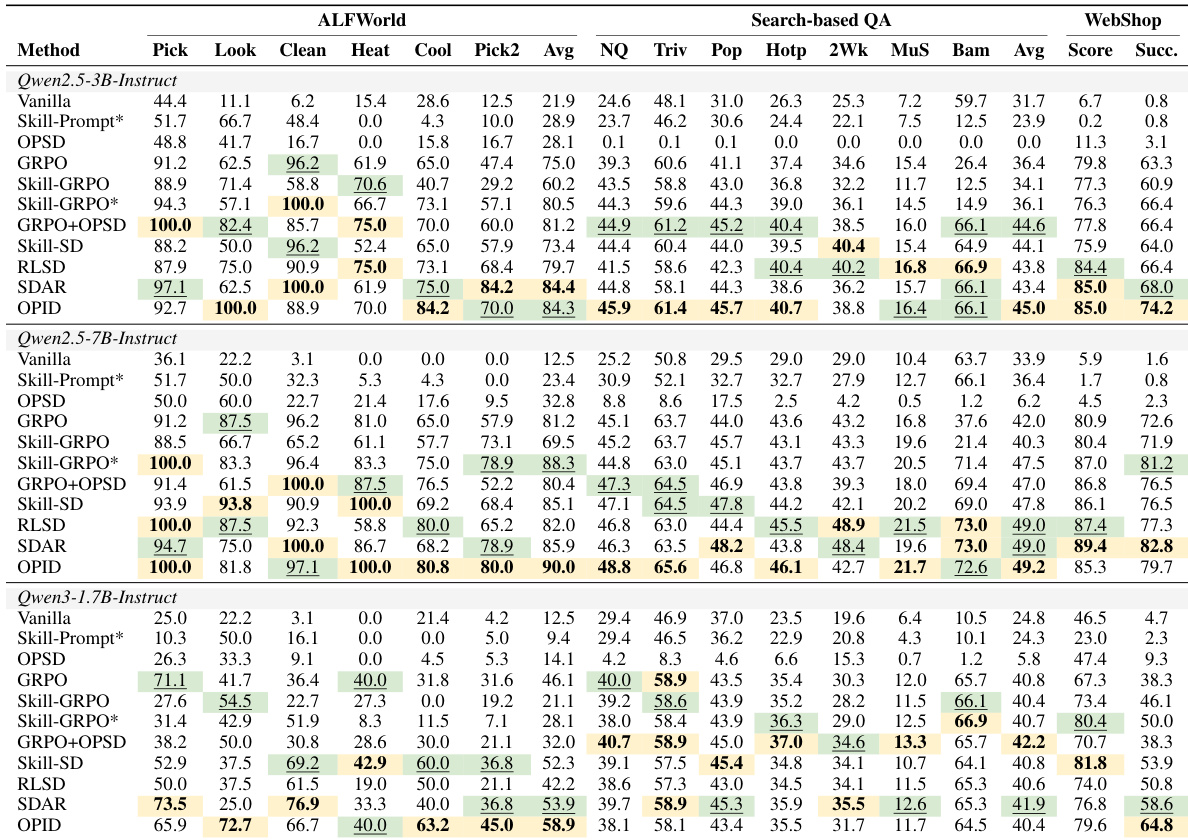
在ALFWorld和WebShop基准上,OPID一致地优于像GRPO这样的仅结果RL基线,通过学习可重用的行为结构,展示了改进的样本效率和跨领域泛化。消融研究表明,分层技能粒度的和关键优先路由都对性能有贡献,完整模型取得了最佳结果。当在多个基准和模型规模上评估时,OPID匹配或超过了混合和自蒸馏基线,有效地将后见之明技能内部化到策略中,而在推理时不需要外部技能上下文。