Command Palette
Search for a command to run...
寻找思考的时间:实时强化学习中的规划预算学习
寻找思考的时间:实时强化学习中的规划预算学习
Aneesh Muppidi Firas Darwish Dylan Cope João F. Henriques Jakob Nicolaus Foerster
摘要
深思熟虑需要时间。在实时环境中,这段时间并非免费。标准强化学习回避了这一点,因为环境会无限期等待智能体的决策。相反,我们研究实时强化学习环境,其中环境在等待智能体行动时仍在推进。基于先前的实时形式化工作,我们引入了可变延迟实时强化学习,智能体在每个决策点选择思考的时长,而环境在此期间持续演进。对于我们所使用的规划智能体,合适的延迟取决于状态,而天真地规划“规划多长时间”可能会使智能体陷入瘫痪。我们转而通过在规划器之上训练一个轻量级门控策略来处理这一设定,以选择依赖状态的规划预算。在实时吃豆人、俄罗斯方块、贪吃蛇、极速六角棋和极速围棋中,我们的门控策略优于固定预算和启发式基线,并能迁移到环境和智能体在两个不同GPU上运行的实时设置中。
一句话总结
牛津大学的研究人员(BOLD、VGG和统计系)提出了一种可变延迟实时强化学习框架,其中一个轻量级门控策略为规划器学习状态依赖的规划预算,在实时Pac-Man、Tetris、Snake、Speed Hex和Speed Go游戏中优于固定预算和启发式基线,并迁移到环境和agent运行在两个不同GPU上的实时设置中。
核心贡献
- 本文引入可变延迟实时强化学习,其中agent可以在每一步选择思考的时间长度,思考的成本直接由环境的前进而非人为奖励惩罚来支付。
- 在冻结的AlphaZero规划器之上用PPO训练的轻量级门控策略选择状态依赖的规划预算,在五个实时游戏(Pac-Man、Tetris、Snake、Speed Hex、Speed Go)中优于固定预算和启发式基线。
- 同一门控策略无需架构更改即可迁移到真正的异步双GPU部署,这得益于一个捕获实时交互动态并将思考成本在学习期间呈现出来的训练协议。
引言
在实时决策中,环境在agent思考时前进,打破了标准RL中世界无限耐心的假设。先前的工作通过固定一步动作延迟来解决此问题,但这阻止了agent在关键状态上分配更多思考时间,而在琐碎状态上减少思考时间。作者将其推广为可变延迟设置,其中agent是一个随时间运行的程序,思考成本由世界推进来支付。他们引入了一个在冻结的AlphaZero式规划器之上训练的轻量级门控策略,该策略学习选择状态依赖的规划预算,优于固定预算基线,并在无需重新训练的情况下迁移到真实硬件。
数据集
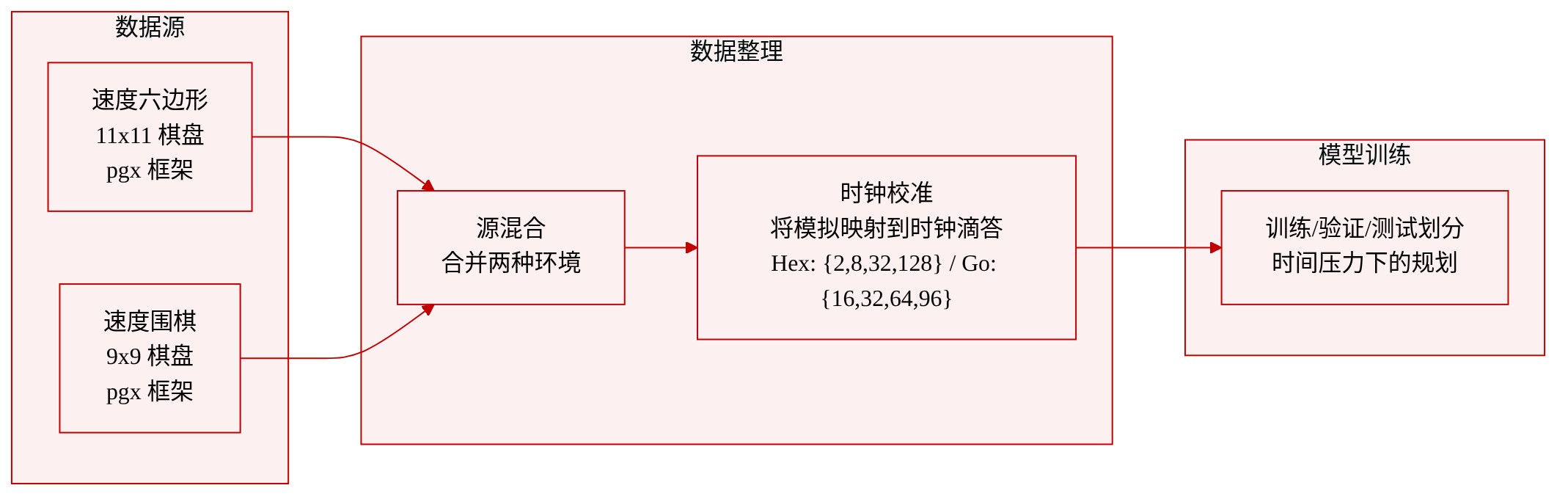
以下是基于所提供文本的简洁数据集描述。
作者使用两个自定义棋盘游戏环境Speed Hex和Speed Go来研究时间压力下的规划。这些环境基于pgx框架构建,并通过移除所有其他动态元素来隔离时钟滴答的影响。
-
数据集组成与来源
-
环境是Speed Hex(11×11棋盘)和Speed Go(9×9棋盘)。
-
它们通过一个退化的反射策略实例化,该策略确定性地执行无操作动作,这意味着棋盘状态在agent思考时保持固定。
-
每个子集的关键细节
-
时钟是唯一的动态元素;它随思考时间减少,而棋盘等待移动。
-
MCTS模拟与时钟滴答之间采用一一映射,每次模拟使玩家的时钟增加一个单位。
-
模拟选项被校准以代表推理延迟和规划质量之间的不同权衡。得到的选项集为:
-
Speed Hex: {2, 8, 32, 128}
-
Speed Go: {16, 32, 64, 96}
-
论文如何使用这些数据
-
这些环境用于模拟快速国际象棋中的压力,即玩家的有限时钟在他们思考时持续运行。
-
等计算每帧的约束在此设置中不适用,因此模拟预算针对每个环境单独校准,以创建具有不同含义的规划策略。
方法
作者解决了实时马尔可夫决策过程(MDPs)的问题,在该问题中环境以固定间隔前进,无论agent的计算速度如何。在此设置中,思考具有直接成本:世界在agent思考时前进。为了管理这种权衡,作者利用基于预算化选项的半马尔可夫决策过程(SMDP)的解决方案。
该框架从三个主要组成部分构建agent的程序:快速反射策略、一组随时行动细化计算以及学习到的门控策略。
反射策略与随时计算 作者承诺使用一个快速的反射策略 πreflex(a∣s),其在不到一帧的时间内执行。该策略在实时协议下提供agent逐帧输出,确保环境始终接收到动作。在像Pac-Man、实时Tetris或Snake这样的承诺动作环境中,这被实例化为规划器的无搜索评估的策略网络。在像Speed Hex或Speed Go这样的时钟环境中,它充当确定性的无操作。
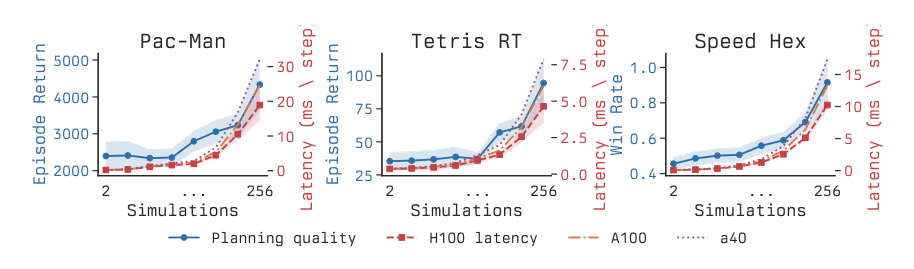
补充反射策略的是一个有限的随时行动细化计算族 {ck}k∈K,按离散时长 k 索引。每个计算 ck 恰好运行 k 帧以细化动作选择,通常实例化为蒙特卡洛树搜索(MCTS)。推动该方法的核心观察是规划质量与推理成本一同增长。
如下图所示:
更长时间运行的计算产生了预期更好的动作,但延长的推理时间在细化动作到达之前使环境更进一步。
预算化选项与元级SMDP 这些组件组合成时间扩展的预算化选项 ok。当选项 ok 在状态 st 启动时,它包裹计算 ck。在中间帧 j=0,…,k−2 期间,agent发出从反射策略中抽取的承诺动作: at+j∼πreflex(⋅∣st+j) 在最终帧,由 ck 产生的细化动作分布 πk 被应用: at+k−1∼πk(⋅∣st) 该公式定义了一个转移核 Pk(s′∣s) 和选项级奖励 Rk(s)。
门控策略 πgate(k∣st) 作为这些选项的元策略运行。在每个元决策状态 st,agent采样一个预算 k,执行选项 ok,并在 k 个原始帧后返回到状态 st+k 的元级别。由此产生的控制问题是一个持有时间 τ(k)=k 的SMDP。元贝尔曼方程为: V(st)=Ek∼πgate(⋅∣st)[∑j=0k−1γjrt+j+γkV(st+k)] 这将对原始动作的选择转变为对时间扩展的计算与控制例程的选择。
门控策略架构与行为 门控策略在每个元步骤中接收三个输入:原始游戏观察、从其冻结主干中提取的规划器中间空间特征,以及规划器的标量值估计 V(st)。在时钟环境中,剩余时间预算也被包括在内。一个轻量级网络处理这些输入,生成关于 k 的分布。
此设计使门控能够响应有意义的决策难度。在承诺动作环境中,策略在状态危险或受约束时分配更深的规划(更高的 k)。
如下图所示:
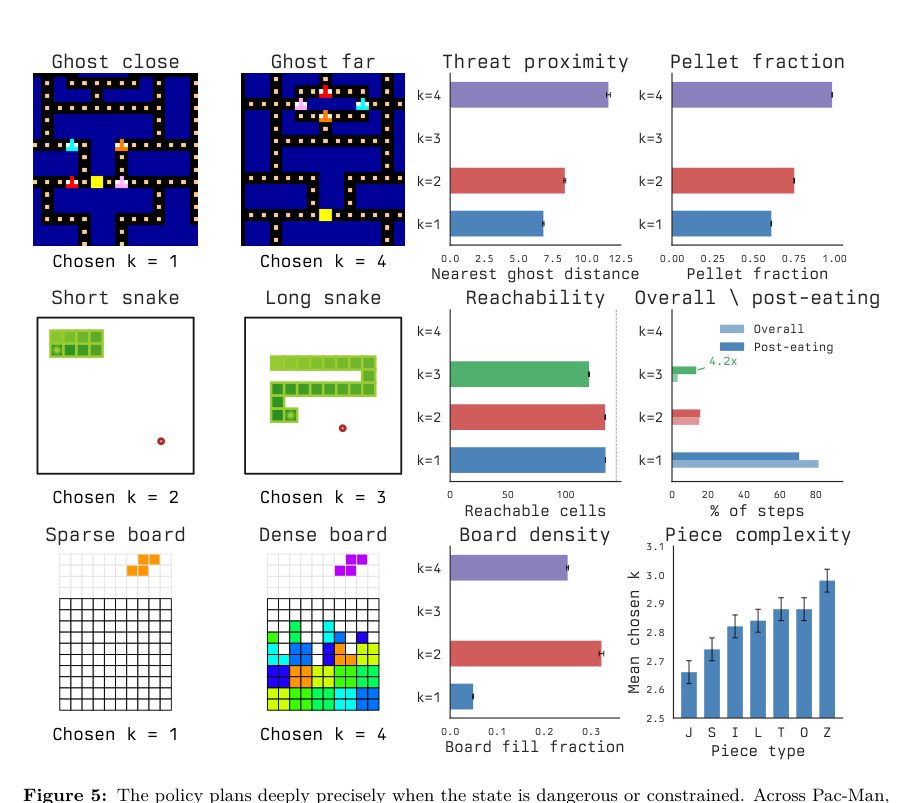
例如,在Pac-Man中,当最近的幽灵很远时选择更大的预算,允许更深的规划,而近处的威胁则触发反应性的 k=1 响应。在实时Tetris中,密集的棋盘相比近乎空的棋盘触发更深的搜索。
在时钟环境中,分配策略根据棋盘状态和剩余时间之间的交互而改变。
如下图所示:

在时钟预算较小时,由于高机会成本,策略强烈偏好最便宜的选项;而较大的预算允许在更深搜索选项之间更均匀地分配。
训练过程 作者采用两阶段训练过程。首先,他们为每个环境训练AlphaZero风格的基础规划器。对于时钟环境,这些通过自我对弈进行训练。一旦基础规划器选定,它便被冻结。然后在冻结的规划器之上使用近端策略优化(PPO)训练门控策略。为了适应元步骤的可变持续时间 k,作者将广义优势估计(GAE)调整为在优势计算中携带每个元步骤的折扣 γk。
实验
评估涵盖经典实时游戏(Pac-Man、Tetris、Snake)和受时钟约束的棋盘游戏(Speed Hex、Speed Go),将学习到的门控策略与固定预算和启发式基线进行比较,以显示动态计算分配始终优于静态策略。门控策略学会根据状态特征(如幽灵距离、棋盘密度或空间约束)触发更深的规划,并能在时钟预算之间泛化,根据剩余时间改变分配。使用异步双GPU执行的实时部署验证了承诺动作训练协议,策略干净地迁移并保持回报和预算分布,支持将模拟的承诺步骤抽象为硬件分离规划的模型。