Command Palette
Search for a command to run...
用于三维线缆驱动软机械臂的深度强化学习增强事件触发数据驱动预测控制
用于三维线缆驱动软机械臂的深度强化学习增强事件触发数据驱动预测控制
Cheng Ouyang Moeen Ul Islam Kaixiang Zhang Zhaojian Li Xiaobo Tan Dong Chen
摘要
软体机器人因其非线性和时变动力学特性而面临控制难题。数据驱动预测控制(DeePC)提供了一种无需模型的替代方案,通过直接利用实测的输入输出轨迹来构建预测控制器。然而,其滚动时域形式需要在每个采样时刻求解一个约束优化问题,这在资源受限的机器人平台上进行实时部署时可能带来较高的计算负担。为克服这一局限,本文提出了一种用于软体机器人控制的自适应基于强化学习的事件触发DeePC(RL-ET-DeePC)框架。通过训练一种无模型强化学习(RL)策略,根据当前系统状态表征来决定何时调用DeePC优化器,从而在保持闭环性能的同时减少不必要的优化调用。仿真结果表明,与周期性DeePC相比,RL-ET-DeePC可将优化频率降低高达66%,同时保持相当的跟踪精度。在三维线驱动软体机械臂上开展的硬件实验验证了零样本迁移能力,该框架使优化频率降低了34%,其跟踪精度与周期性DeePC相当,且性能表现优于基于静态阈值的事件触发基线方法,具有更高的一致性。
一句话总结
本文提出 RL-ET-DeePC,一种基于事件触发机制的数据驱动预测控制框架。该框架采用无模型强化学习策略动态激活优化器,在仿真中将优化频率降低了 66%,在零样本迁移至 3D 线驱动软体机械臂时降低了 34%,同时保持了与周期性方法相当的跟踪精度。
核心贡献
- 提出一种基于自适应强化学习的事件触发 DeePC(RL-ET-DeePC)框架,通过自适应调度预测优化器,满足软体机器人实时控制的计算需求。
- 开发无模型强化学习策略,通过评估当前系统状态仅在必要时动态触发优化器,从而消除冗余计算,同时保持闭环跟踪性能。
- 在三维线驱动软体机械臂上进行仿真与硬件实验以验证该框架,结果表明仿真中优化频率最高降低 66%,零样本硬件部署时降低 34%,同时保持与周期性方法相当的跟踪精度,且在一致性方面优于静态阈值基线。
引言
软体机器人的控制 inherently 具有挑战性,因其高度非线性和时变动力学特性,使得传统基于模型的方法在实际部署中难以应用。数据驱动预测控制(DeePC)提供了一种极具潜力的无模型替代方案,通过直接使用测量的输入输出轨迹构建预测控制器,但其滚动时域设计要求在每次采样时刻求解约束优化问题。这种计算负担为对低延迟控制有需求的资源受限机器人平台带来了显著瓶颈。为解决这一问题,本文提出一种基于自适应强化学习的事件触发 DeePC 框架,根据实时系统状态动态调度优化器调用。通过训练无模型强化学习策略仅在必要时激活控制器,大幅降低了计算开销并保持了跟踪精度,这一点已通过三维线驱动软体机械臂的仿真与零样本硬件实验得到验证。
方法
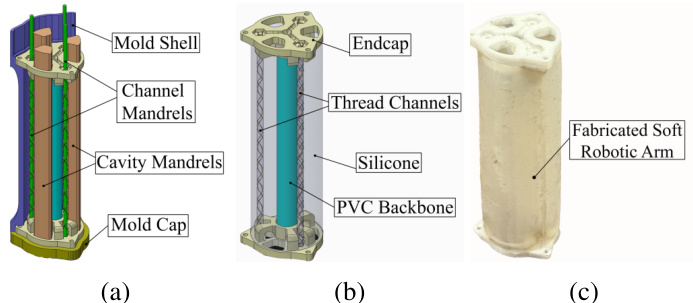
本文提出一种专为线驱动软体机械臂设计的控制框架,如下方图片所示的制造结构。
核心方法论为 RL-ET-DeePC(强化学习事件触发数据驱动预测控制)架构。如框架图所示,系统分为两个主要阶段:数据预处理与基于强化学习的事件触发控制循环。
数据预处理与 SVD-DeePC 该方法采用数据驱动方式对系统动力学进行建模,无需显式识别状态空间矩阵。研究人员收集离线输入输出轨迹,记为 ud 和 yd,并将其排列为深度为 L 的分块 Hankel 矩阵。根据 Willems 基本引理,该 Hankel 矩阵的列空间刻画了底层线性时不变系统的所有可行轨迹。
HL=[HL(yd)][HL(ud)]然而,软体机器人需要大量数据收集,导致生成的 Hankel 矩阵维度较高,实时处理计算成本高昂。为缓解此问题,研究人员应用奇异值分解(SVD)对数据进行压缩。对拼接后的 Hankel 矩阵进行分解,并将矩阵截断至秩 r,仅保留主导奇异值。此过程在保留主要动力学模态的同时,显著降低了决策变量的维度。得到的降维 Hankel 矩阵 HˉL 允许将任意有效轨迹近似表示为:
[u[1,L]y[1,L]]=HˉLgˉ其中 gˉ 为低维决策向量。
基于强化学习的事件触发控制循环 控制循环(如框架图下部所示)将该压缩数据表示与强化学习 Agent 相结合,以管理计算成本。在每个时间步 t,系统状态由跟踪误差 et 及其变化量 Δet 推导得出。该状态被输入至 RL Agent,输出二元动作 at∈{0,1}。
若动作值为 1,系统触发 SVD-DeePC 优化器。该模块求解正则化优化问题,在满足数据驱动约束的前提下最小化跟踪误差与控制代价。优化问题包含松弛变量以处理测量噪声,并加入正则化项以防止过拟合。
gˉ,u,y,σyminsubject to∥y−yr∥Q2+∥u∥R2+λy∥σy∥22+λg∥gˉ∥22HˉLgˉ=uiniuyiniy+00σy0优化器生成最优控制序列,其第一个元素被应用于机器人,其余元素存储在控制序列缓冲区中。
若动作值为 0,则跳过优化以节省计算资源。控制器改为从控制序列缓冲区中获取下一个控制输入。这使得系统能够利用上一次优化步骤的预测时域,将传统的滚动时域控制转化为事件驱动机制。
监督覆盖机制 为确保鲁棒性,监督模块在控制架构中充当安全保护机制。该模块监控控制序列缓冲区以及距上次更新经过的时间。若缓冲区为空或距上次优化的时间超过预测时域减一(t−tlast≥N−1),监督模块将强制触发(δt=1),覆盖 RL agent 的决策。这确保了控制器始终拥有有效的控制序列可用,并防止过多的开环执行。有效触发信号 δt 决定是运行 SVD-DeePC 优化器还是使用缓冲区中的输入。
训练与交互 RL agent 的训练旨在平衡跟踪精度与计算效率。奖励函数对跟踪误差和触发优化器的计算成本均进行惩罚。奖励函数中的参数 ρ 控制权衡关系,促使 agent 学习依赖状态的策略,仅在必要时触发优化。agent 通过回合与环境交互,根据观测到的状态、动作和奖励更新其策略。该框架与算法无关,允许集成 DQN、PPO 或 A2C 等多种强化学习方法。
实验
评估工作结合了高保真仿真与线驱动软体机械臂的物理实验,以检验所提出的 RL-ET-DeePC 框架。仿真测试验证了控制器在泛化至未见轨迹时,平衡跟踪精度与计算效率的能力。硬件实验进一步证实,所学策略成功迁移至真实环境条件,在无需依赖固定误差阈值的情况下,维持了稳定控制与上下文感知触发。总体而言,该框架通过在动态过渡期优先更新来有效降低优化频率,在智能适应运动上下文的同时,保持了与周期性控制相当的跟踪保真度。
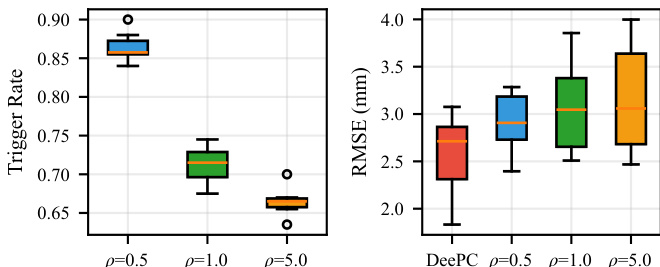
研究人员在物理软体机械臂上对 RL-ET-DeePC 框架进行评估,并与周期性 DeePC 基线进行对比。结果表明,惩罚参数控制着明确的权衡关系:增加惩罚值会显著降低控制器更新频率,同时保持可接受的跟踪精度。周期性 DeePC 控制器作为高精度基线,而基于强化学习的方法通过自适应调整重新优化的时机,有效降低了计算负担。增加惩罚参数会导致触发率大幅下降,与周期性基线相比减少了优化调用次数。即使在更新频率降低的情况下,RL-ET-DeePC 方法仍保持与周期性 DeePC 控制器相当的跟踪精度。所学策略成功实现从仿真到硬件的迁移,在真实条件下保持了预期的精度与效率权衡。
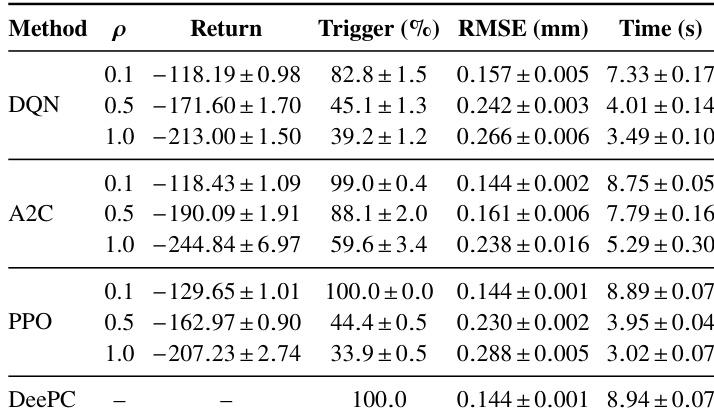
研究人员将包括 DQN、A2C 和 PPO 在内的基于强化学习的事件触发 DeePC 方法与周期性 DeePC 基线进行对比。增加惩罚参数 rho 会一致性地降低所有强化学习算法的触发频率与总计算时间,同时略微增加跟踪误差。PPO 展现出最高效的性能,在保持可接受跟踪精度的前提下,实现了决策时间的大幅缩减。增加惩罚参数 rho 会导致所有强化学习算法的触发率降低并减少计算时间。在强化学习方法中,PPO 实现了最低的总决策时间,在效率上优于 DQN 和 A2C。周期性 DeePC 基线保持了最高的触发率与精度,作为性能上限,强化学习方法在降低计算成本的前提下逼近该上限。
实验在物理软体机械臂上评估了基于强化学习的事件触发 DeePC 框架,并以周期性 DeePC 基线为基准,检验其计算效率与跟踪性能。通过调整惩罚参数,研究证实强化学习方法成功平衡了降低优化频率与保持跟踪精度之间的关系,在确保控制质量不受影响的前提下有效降低了计算需求。在测试算法中,PPO 被证明最为高效,而整体框架验证了稳健的仿真到硬件迁移能力,在真实条件下保持了预期的精度与效率权衡。