Command Palette
Search for a command to run...
基于意图感知场景表示的人群中机器人视觉导航学习
基于意图感知场景表示的人群中机器人视觉导航学习
Han Bao Bingyi Xia Hanjing Ye Yu Zhan Hao Cheng Baozhi Jia Wenjun Xu Jiankun Wang
摘要
机器人人群导航需要在考虑环境结构约束的同时,具备推断人类意图的能力。当前,深度强化学习(DRL)为学习能够理解人类意图的导航策略提供了一种极具前景的方法。然而,现有方法大多依赖于有限的场景表示,将行人简化为简单的二维点,并忽略了来自行人自身及环境的丰富视觉线索。为解决该问题,我们提出了iCrowdNav,这是一种具有意图感知场景表示的新型视觉人群导航方法,旨在从自我中心视觉观测中编码行为与结构上下文信息。该方法包含两个核心组件:一个用于提取场景占用特征的时空编码器,以及意图交互Former(I2 Former)。后者是一种基于注意力机制的模块,通过对人体姿态进行编码来推断行人的运动意图。这些特征被融合为一个紧凑的状态嵌入表示,以支持高效的深度强化学习策略训练。大量实验表明,本方法在性能上显著优于基线方法,且实地部署验证了基于视觉的人群导航的可行性。
一句话总结
iCrowdNav 通过利用意图感知的场景表示来增强用于人群导航的深度强化学习。该表示整合了用于环境占用情况的时空编码器,以及用于从第一人称视角推断行人姿态的 Intent-Interact Former (I^2Former)。在大量实验中,该方法取得了优于基线模型的性能,并成功实现了真实世界部署。
核心贡献
- iCrowdNav 是一种视觉导航框架,能够直接从第一人称相机观测中学习意图感知的场景表示。该架构结合了用于提取占用特征的时空编码器与 Intent-Interact Former 模块,用于处理人体姿态并推断行人运动意图。
- 该方法使用整合了行为视觉线索的 BEV 特征替代了简化的二维点表示,使深度强化学习策略能够穿梭于密集人群中。该设计在紧凑的状态嵌入中同时捕获了环境结构约束与人类行为上下文,从而实现有效的策略训练。
- 大量仿真基准测试与真实物理机器人部署表明,该框架相较于现有基线实现了更高的安全性与鲁棒性。这些结果验证了基于视觉的人群导航在动态、有人群环境中的实际可行性。
引言
在密集人群中实现自主机器人导航对于真实世界的应用至关重要,但这要求在受限空间中导航时能够预测人类行为。先前的深度强化学习方法通常通过将行人简化为低维二维点并依赖基础占用地图来过度简化场景表示。这种方法忽略了身体姿态和环境语义等关键视觉线索,从而限制了从受控仿真到非结构化真实环境的泛化能力。为了解决这些局限性,研究者在深度强化学习框架中采用了一种新型视觉编码器,直接从第一人称 RGB-D 相机中学习意图感知的场景表示。他们将提取密集占用特征的时空编码器与基于注意力机制的模块相结合,后者能够从 3D 人体姿态中推断行人的运动趋势。这些丰富的视觉线索被融合为一个紧凑的状态嵌入,使机器人能够在复杂人群中安全高效地导航,并成功实现了零样本仿真到现实的部署。
数据集

-
数据集组成与来源 数据集完全通过基于 Isaac Sim 构建的 SocNav-Gym 环境进行仿真生成。视觉数据由配备两台 Intel RealSense D435 RGB-D 相机的 Clearpath Dingo 机器人采集,两台相机提供约 140 度的组合视场角以及 0.3 至 10 米的深度范围。
-
各子集关键细节 训练场景包含走廊、转角、杂乱空间及密集开放区域。测试场景涵盖医院、办公室和仓库等专业室内环境。提供的文本未明确指定数据集确切大小、过滤阈值或子集混合比例。
-
论文对数据的使用方式 研究者利用仿真轨迹来训练和评估社交导航策略。每个回合随机化机器人的起始位置与目标位置,以促进其在不同导航任务中的适应能力。行人 agent 遵循 Social Force Model(社交力模型),并向完全随机化的目的地移动,以驱动策略学习。
-
处理与环境细节 通过 Isaac Sim 渲染自然的行人动画,以确保人群交互紧密贴合现实动力学。该仿真未提及明确的裁剪策略或元数据构建,而是依赖随机化的回合初始化与基于物理的行人建模来生成多样化的导航体验。
方法
研究者通过将任务建模为部分可观察马尔可夫决策过程,应对拥挤环境中基于视觉的机器人导航挑战。整体系统架构如图架构所示,展示了从系统输入到导航动作的流程。该方法包含三个核心组件:特征提取模块、特征融合模块以及深度强化学习网络。
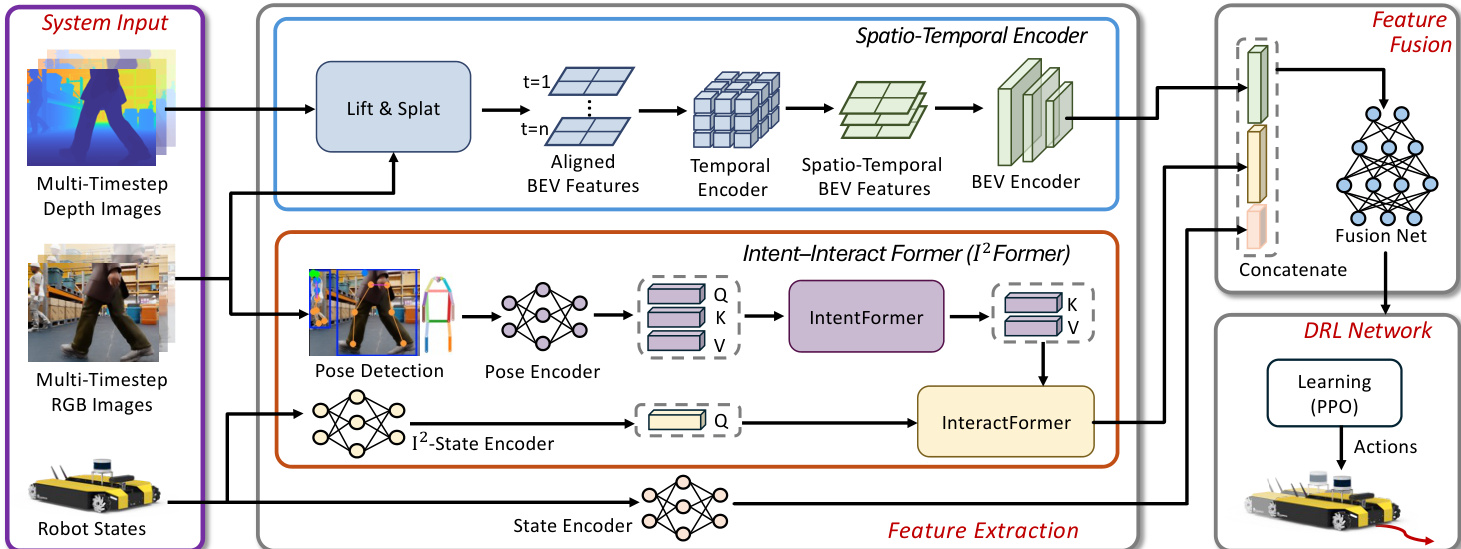
特征提取模块处理多时间步的 RGB-D 图像与行人姿态。如详细模块图所示,时空编码器负责处理视觉输入。它利用预训练的 RGB 骨干网络从图像中提取特征。随后,这些特征被映射到 3D 空间并投影至鸟瞰图(BEV)表示中。为了捕捉时间动态,编码器使用时序编码器对齐先前时间步(t−1 和 t−2)的 BEV 特征,从而生成鲁棒的时空 BEV 特征图。该编码器在训练过程中保持冻结,因其已在外部数据集上完成预训练。
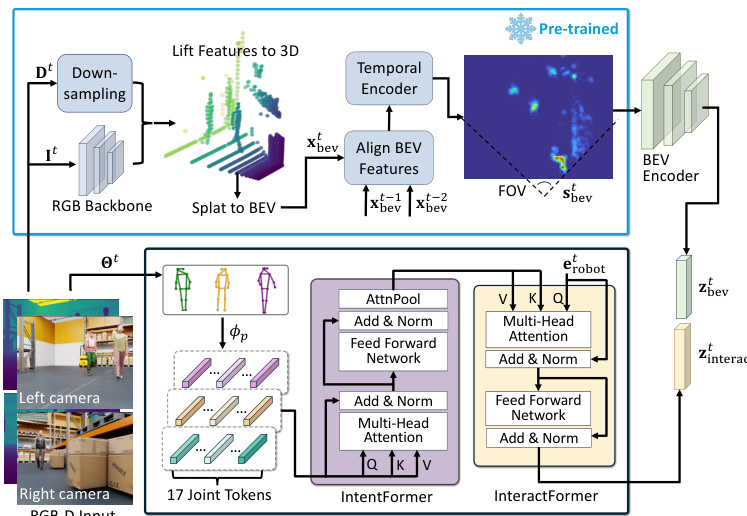
同时,Intent-Interact Former (I2Former) 从周围行人的姿态中提取意图感知特征。姿态检测模块识别行人并编码其 17 个关节 token。这些 token 由 IntentFormer 处理,以捕捉行人的意图。随后,InteractFormer 通过多头注意力机制将这些意图特征与机器人的内部状态嵌入(erobott)进行整合,生成交互感知特征。
提取的时空 BEV 特征(zbevt)与交互特征(zinteractt)与机器人状态嵌入拼接,形成综合状态表示。该状态嵌入被输入至基于近端策略优化(PPO)算法的 DRL 网络。网络经过训练以最大化期望累积奖励,定义如下:
L(θ)=Eπθ[t=0∑∞γtrt]其中 γ 为折扣率,rt 为时间 t 的奖励。奖励函数的设计旨在鼓励安全导航、避免碰撞及生成平滑轨迹。具体而言,导航奖励 rnavt 根据到目标的距离(dgt)与到障碍物或行人的最小距离(dot)提供密集反馈。奖励逻辑结构如下:
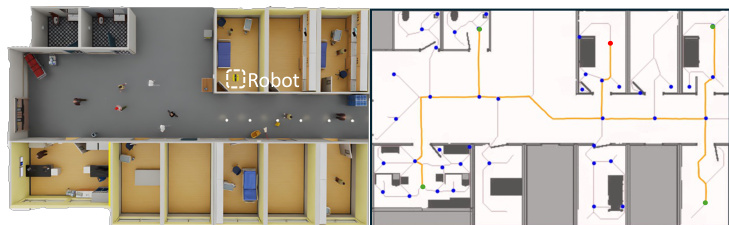
rnavt=⎩⎨⎧20,−20,0.5(dot−0.9),3.2(dqt−1−dqt),if dgt≤ρrobotelse if dot≤ρrobotelse if ρrobot<dot<0.9otherwise,其中 ρrobot 为机器人的半径。为应对策略中可能出现的抖动,还引入了轨迹平滑奖励 rωt,该奖励会对过大的角速度进行惩罚。该方法在复杂的室内场景中进行评估,如仿真可视化所示,机器人需在穿越走廊与房间的同时,与行人保持社交距离。
实验
所提方法通过模拟人群导航(涵盖不同空间约束与密度)、长视界拓扑映射任务以及复杂公共环境的真实部署进行了评估。这些实验验证了时空 BEV 编码器与意图感知 I²Former 模块的组合有效性,并与消融变体及成熟导航基线进行对比。定性结果表明,完整架构始终能生成更平滑的轨迹,提升空间感知能力,并显著减少对私人空间的侵入,尤其在密集或狭窄场景中。消融研究证实,同时整合环境占用特征与行人意图建模对于实现灵活导航至关重要,而真实世界测试进一步展示了该系统在动态、遮挡条件下的鲁棒性与社交合规性。
该实验在办公室与医院场景中,将所提导航方法与基线及消融变体进行了对比。完整方法始终取得最高的成功率与最低的行人私人区域停留时间,表明其具备更优的安全性与有效性。消融研究证实,意图感知模块与 BEV 表示均至关重要,因为移除任一项均会导致成功率与私人空间合规性下降。相较于所有基线方法,所提方法在办公室与医院环境中均取得了最高成功率。移除意图感知模块会导致成功率下降,并显著增加在行人私人区域的停留时间。完整方法通过在两种环境中保持最低的私人区域停留时间,展现出最安全的导航行为。
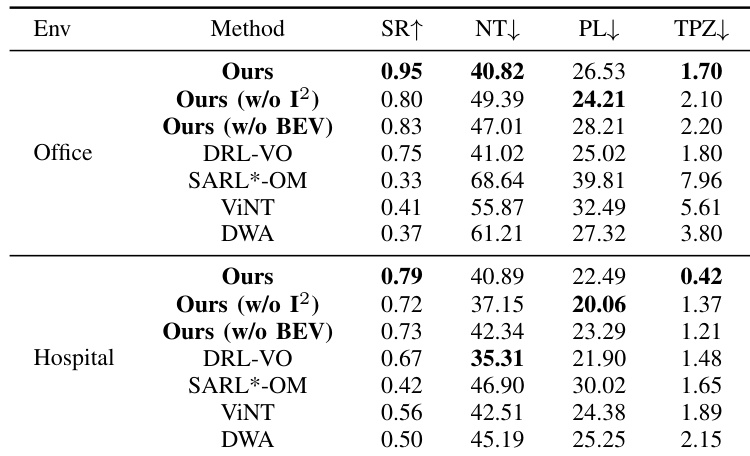
研究者在三种宽度与人群密度各异的独立环境中,将导航方法与多种基线及消融变体进行了评估。结果表明,完整方法在最小化侵入行人私人空间的同时,实现了最高成功率与最高效的导航。移除意图感知模块或 BEV 编码器关键组件会导致性能显著下降,尤其在成功率与社交合规性方面。所提方法在所有测试环境中,于成功率、导航效率与社交合规性方面均持续优于基线。消融研究证明,意图感知模块与 BEV 编码器对鲁棒性能至关重要,因为缺失它们会增加碰撞与社交违规行为。在狭窄与高密度场景中,相较于常表现出僵硬或低效导航行为的基线,该方法保持了更优的稳定性与安全性。
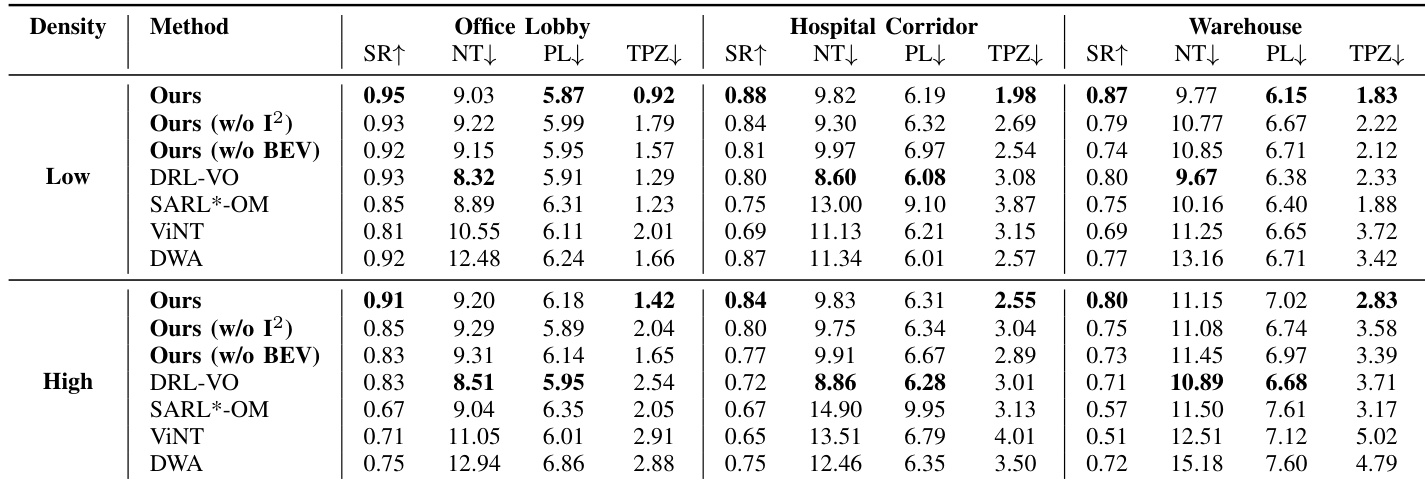
为评估整体有效性与社交合规性,所提导航方法在办公室、医院及其他多样化环境设置中,与标准基线及消融变体进行了对比评估。完整系统始终展现出更优的导航成功率与效率,并严格最小化对行人私人空间的侵入,尤其在基线方法表现出僵硬或不安全行为的狭窄或拥挤条件下。消融研究进一步验证,意图感知模块与 BEV 表示对鲁棒性能至关重要,因为移除它们会严重损害安全性,增加社交违规,并降低整体可靠性。