Command Palette
Search for a command to run...
RoboAtlas:上下文主动SLAM
RoboAtlas:上下文主动SLAM
Alexander Schperberg Shivam K. Panda Abraham P. Vinod M. K. Jawed Stefano Di Cairano
摘要
我们提出了RoboAtlas,这是一种上下文感知的主动SLAM框架,它利用可扩展的3D语义映射系统OpenRoboVox,自适应地平衡几何探索与语义推理。RoboAtlas通过上下文多臂老虎机机制,将前沿探索、全局语义地图推理与基于以自身为中心的视觉语言模型(VLM)推理相融合。随着场景理解能力的提升,该机制能够从探索阶段自然过渡至语义引导的导航阶段。我们在仿真环境以及Unitree Go2机器人上对该系统进行了评估,测试场景为面积超过1800平方米、包含约3万个映射语义实例的大规模真实世界环境,任务成功率达到100%。在GOAT-Bench“Val Unseen”基准测试中,RoboAtlas在使用GPT-4o的情况下取得了最先进的性能,报告的最高成功率(SR)为90.6%,较此前最强的基线方法在SR上提升了17.8个百分点。在使用规模小得多的Qwen2.5-VL-7B模型时,其SR仍达到88.8%,在SR指标上超越了所有使用GPT-4o的基线方法,这揭示了通过我们的语义映射框架所获取信息的重要性,其价值远超过单纯替换底层基础模型。结果表明,利用大规模3D语义地图对基础模型进行锚定,能够实现鲁棒且高效的上下文感知主动SLAM。
一句话总结
RoboAtlas 是一个上下文感知的主动 SLAM 框架,它采用上下文多臂老虎机机制,结合 OpenRoboVox 3D 语义映射系统,将前沿探索转化为语义引导的导航。该框架在 Unitree Go2 机器人上实现了 100% 的任务成功率,环境面积超过 1800 m²,包含约 30,000 个语义实例,并在 GOAT-Bench "Val Unseen" 基准测试中取得了 90.6%(GPT-4o)和 88.8%(Qwen2.5-VL-7B)的最先进成功率,证明了大规模语义地图接地能够显著提升自主导航的鲁棒性。
核心贡献
- RoboAtlas 是一个上下文感知的主动 SLAM 框架,集成了 OpenRoboVox。OpenRoboVox 是一套重新设计的 3D 语义映射系统,专为在物理机器人上进行可扩展的实时部署而打造。OpenRoboVox 通过内存高效的 TSDF 管理、异步语义处理以及用于快速推理的低阶 2D 柱状图表示,对原始 OpenVox 架构进行了增强。
- 该系统采用上下文多臂老虎机策略,动态融合前沿探索、全局语义地图推理与自我中心视觉语言模型线索。这种自适应决策机制使得系统能够随着上下文证据的积累,从广泛的几何探索过渡到目标明确的语义搜索。
- 在面积超过 1800m2 的环境中的 Unitree Go2 机器人上进行的评估,以及在 GOAT-Bench "Val Unseen" 基准测试中的表现,均确立了最先进的导航性能。该框架在使用 GPT-4o 时取得了 90.6% 的成功率,比最强的先前基线高出 17.8 个百分点;而在使用 Qwen2.5-VL-7B 时达到 88.8% 的成功率,证明了语义映射架构的作用超越了单纯的基础模型选择。
引言
主动同步定位与建图(Active SLAM)使机器人能够通过优化以获取信息增益的轨迹,在未知环境中实现自主导航。上下文主动 SLAM 通过集成基础模型来支持语义搜索和物体目标导航等高级推理任务,从而扩展了这一能力,解决了纯几何方法无法处理复杂语言条件指令的问题。然而,先前的工作面临显著局限。许多流程依赖保真度较低的几何表示或限制高级推理的启发式目标;而最近的零样本视觉语言方法通常将语义推理与度量定位解耦,忽略了地图保真度和规划可行性等平台特定约束。此外,可扩展的语义映射框架通常缺乏在物理硬件上实时部署的能力,往往假设理想化条件或依赖离线评估。为克服这些挑战,本文提出 RoboAtlas,这是一种上下文主动 SLAM 框架,通过上下文多臂老虎机自适应地平衡几何探索与语义推理。该系统利用 OpenRoboVox 这一可扩展的 3D 语义映射引擎,在混合专家架构内融合前沿探索、全局语义地图推理与自我中心视觉语言线索。该设计使机器人能够随着上下文证据的积累,平滑地从粗略探索过渡到目标明确的语义导航。RoboAtlas 在基准测试中实现了最先进的性能,证明使用大规模实时 3D 语义地图对基础模型进行接地可显著提升导航的鲁棒性与效率。
方法
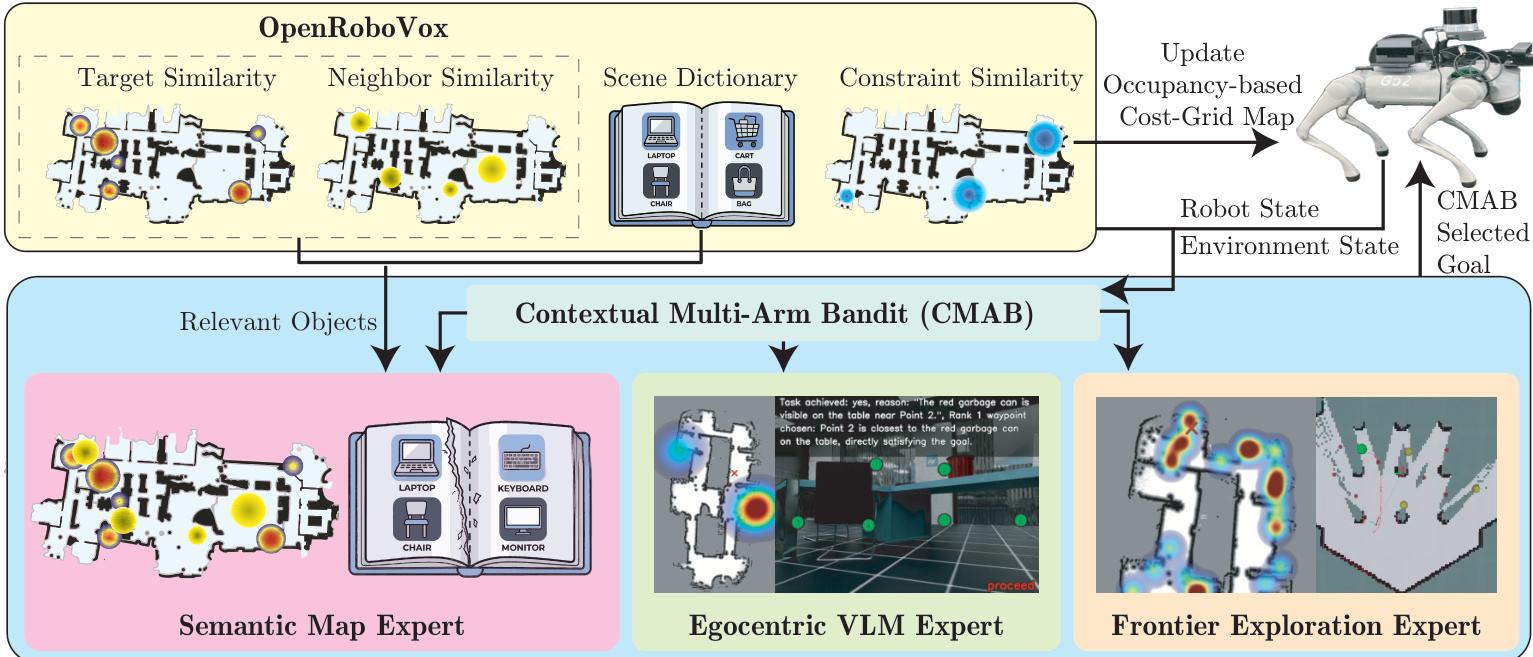
本文提出 RoboAtlas,这是一种上下文主动 SLAM 框架,将实时语义映射与自适应目标选择策略相结合。完整系统架构请参阅框架图。该流水线以异步方式运行,将几何跟踪与语义推理解耦,以确保在资源受限的硬件上实现实时性能。在每个决策周期,系统构建上下文状态向量,并采用上下文多臂老虎机(CMAB)在三种导航专家中动态选择:基于前沿的探索器、语义地图推理器和自我中心视觉语言模型(VLM)专家。

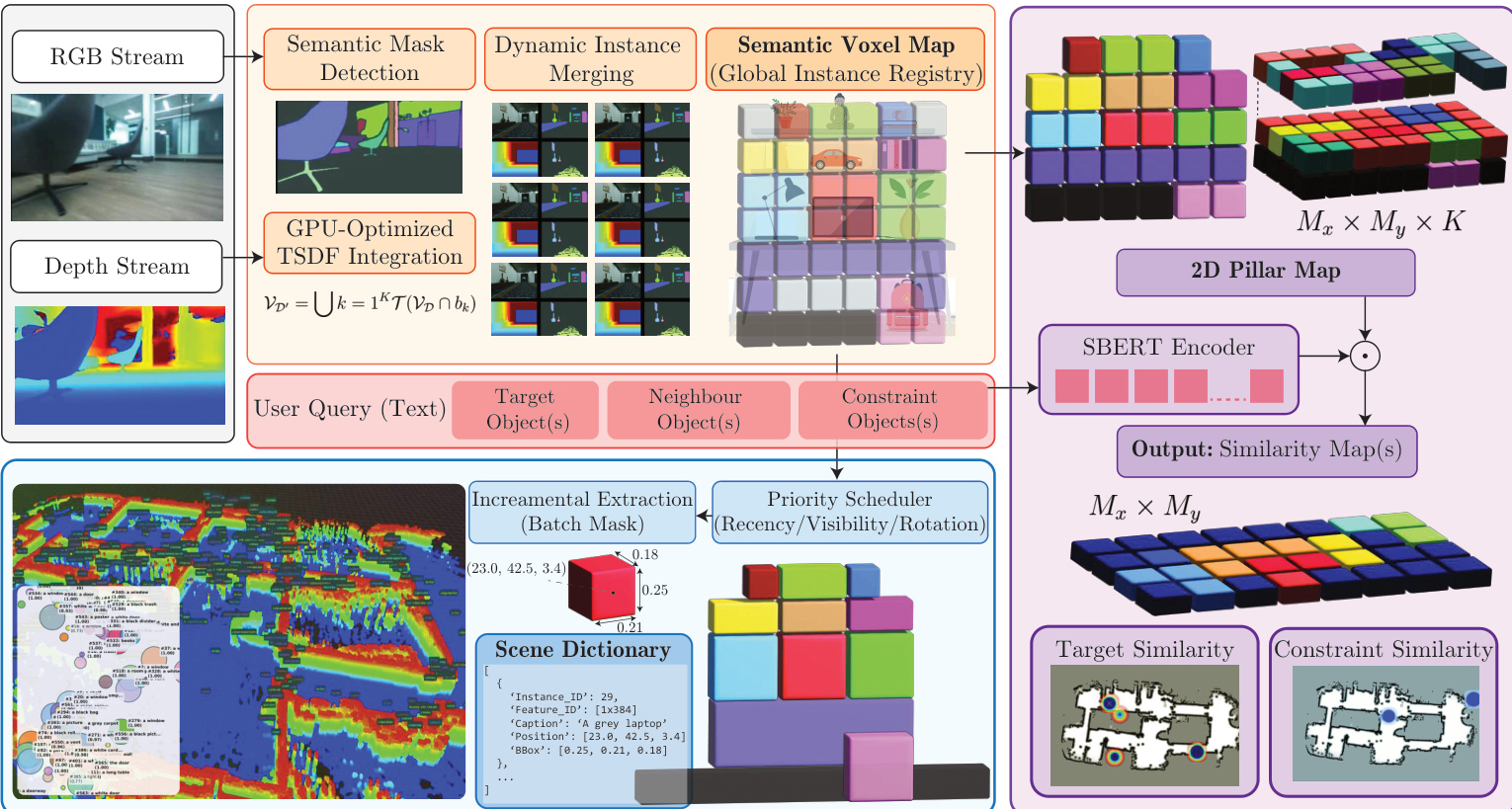
OpenRoboVox 语义映射模块 为支持语言引导的导航,本文引入 OpenRoboVox,这是一种硬件高效、实例级别的语义映射框架。感知流水线接收 RGB 和深度流,以执行语义掩码检测与 GPU 优化的截断符号距离场(TSDF)融合。系统维护一个全局实例注册表,其中每个体素保留对象身份的概率表示。为解决大规模映射期间的内存限制,OpenRoboVox 实现了基于块的体素传输协议,通过顺序传输不相交的立方体块而非复制整个张量,从而限制峰值显存使用。此外,该框架通过异步并行架构将语义处理与几何跟踪解耦。场景字典管理器作为后台进程运行,从体素地图中增量提取对象质心、边界框和占用概率。该管理器采用基于优先级的调度算法,根据时间新鲜度、活跃观测视锥和旋转一致性,选择有界批次的实例进行更新。生成的场景字典 St 提供了一种紧凑且可查询的表示形式,连接了原始体素数据与高层规划。
上下文多臂老虎机与奖励公式 导航决策层使用上下文多臂老虎机将目标选择构建为自适应问题。该老虎机维护一组对应于专家策略的臂 E={EFrontier,ESemanticMap,EEgoVLM}。在每次重规划步骤 t,agent 观察到上下文向量 ct,该向量汇总了占用覆盖率、语义相似度指标、回溯指示器以及近期位移。该老虎机利用线性上置信界(LinUCB)策略来平衡探索与利用。每个臂提出一个候选目标 gt(a),策略根据乐观奖励估计选择最优臂 at。奖励函数被构建为地图覆盖率扩展、语义相关性、VLM 置信度的加权组合,以及对回溯或重复空选的惩罚:
rt=w1m˙tocc−w2Bt+w3Vtvlm+w4Vtsim+wsucc该奖励结构鼓励增加地图覆盖率并提高语义相关性的动作,同时避免对已探索区域的不必要重复访问。
专家架构 前沿专家通过在已探索与未探索空间的边界评估候选目标,优先考虑几何信息增益。它在预期传感器足迹覆盖范围与移动成本之间优化权衡,并受限于能量可行性约束,以确保机器人能够安全返回充电站。
语义地图专家利用场景字典 St 与大语言模型(LLM)后端执行开放词汇推理。系统将字典序列化为文本上下文,并应用预过滤阶段,仅保留相对于任务查询余弦相似度超过阈值的实例。LLM 根据语义匹配度和空间合理性对这些过滤后的候选项进行排序,输出结构化置信度分数 ΦLLM(Oi)。该专家从 Top-N 候选项中选择得分最高的实例对应的导航目标。
自我中心 VLM 专家直接在机器人的当前第一人称观测上运行。它处理用户指令与带注释的 RGB 图像,其中空间注释根据交互范围约束进行剪枝。VLM 输出离散的动作基元,包括向候选目标前进、原地旋转或执行 180 度转弯。当选择导航动作时,目标被设置为置信度最高的注释实例的空间位置。系统在有限规划视界内展开 VLM 决策,以确保行为稳定。此外,VLM 生成文本场景描述,并将其累积到上下文字典中,以丰富语义地图专家的推理能力。
如下处理流水线所示:
在线策略适应 该老虎机策略在部署期间持续更新,无需离线训练。在每个重规划周期,agent 观察到基于占用覆盖率、语义相似度和新实例发现率的一步增量所派生的每回合奖励。子任务完成后,基于 agent 感知到的目标到达证据与置信度计算稀疏宏奖励。该宏奖励使用指数衰减的信用分配机制分布到子任务的轨迹上,使策略偏向于对成功结果负有直接责任的臂,同时仍为早期的探索动作分配信用。累积的奖励信号增量更新特定于臂的协方差矩阵与响应向量,使系统能够随着上下文证据的积累,自然地从早期的覆盖率驱动探索过渡到目标明确且感知语义的导航。
请参阅下方的硬件验证设置:
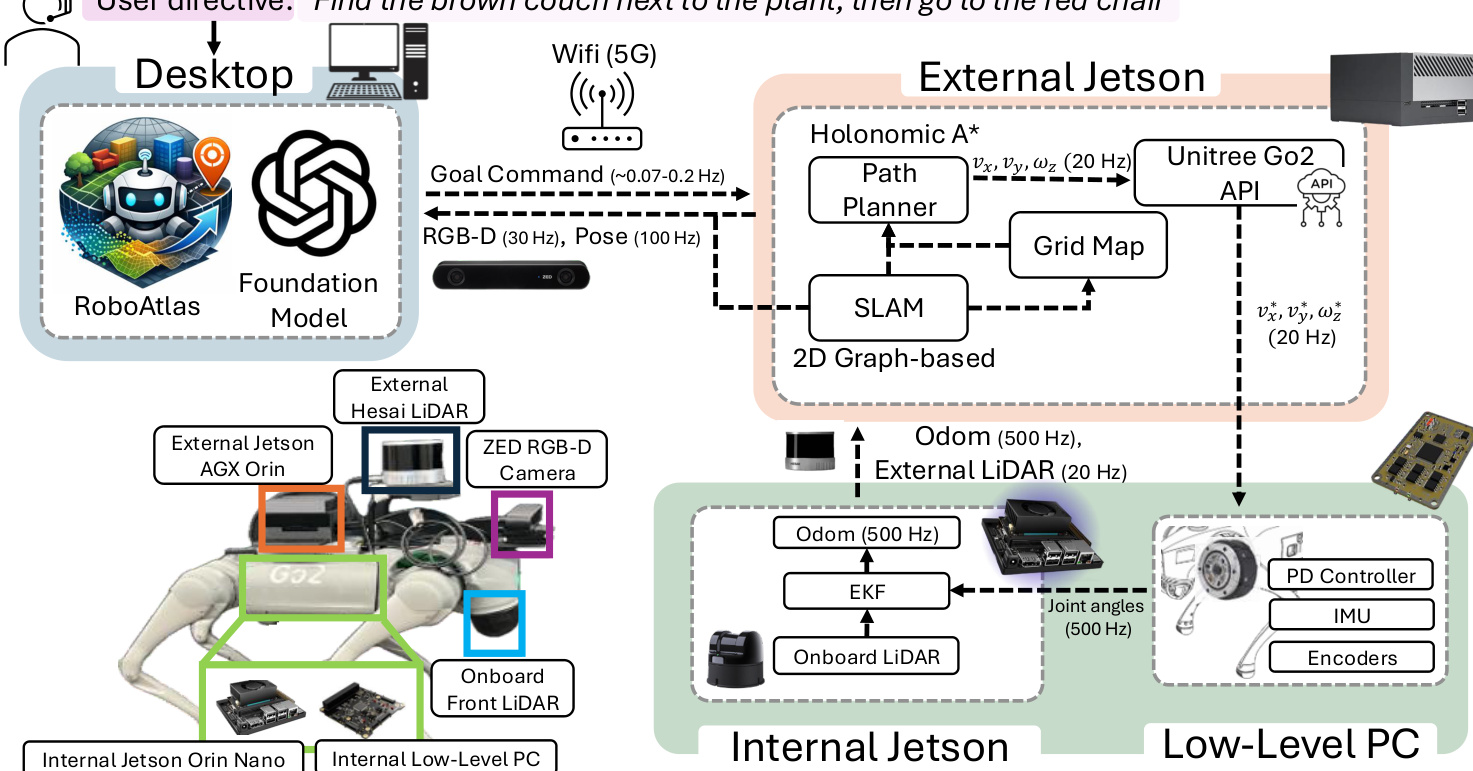
实验
该框架在真实物理硬件、基于物理的仿真以及照片级真实环境中进行评估,验证了其实时 3D 语义映射、自适应决策与长视界导航能力。实验表明,随着环境覆盖率的增加,上下文老虎机策略动态地从几何探索过渡到语义推理,从而在未知和预建图环境中实现稳健的目标获取。在所有平台和基准测试中,该系统始终实现高任务成功率并优于先前方法,即使与较小规模的基础模型配合使用也是如此。最终,这些结果证实该方法有效衔接了几何探索与语义导航,尽管其整体可靠性仍取决于映射保真度、推理延迟与奖励公式。
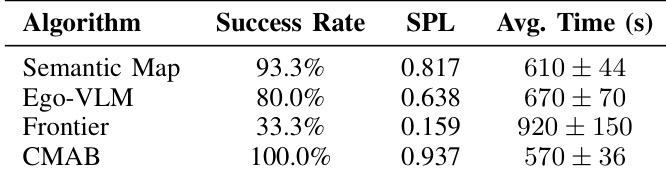
实验评估了四种导航算法,证明上下文多臂老虎机(CMAB)方法显著优于固定策略基线。CMAB 实现了最高的成功率与效率,相比语义地图、自我中心 VLM 或前沿探索方法,它以更短的路径和更快的速度完成任务。这些结果凸显了基于环境上下文动态选择专家的优势,而非依赖单一导航策略。CMAB 在所有测试算法中实现了最高的成功率和最快的完成时间,展现出卓越的性能。前沿探索被证明是效率最低的策略,产生的成功率最低且执行时间最长。语义映射和自我中心 VLM 等单专家方法表现出中等性能,在可靠性与速度上均不及自适应的 CMAB 方法。
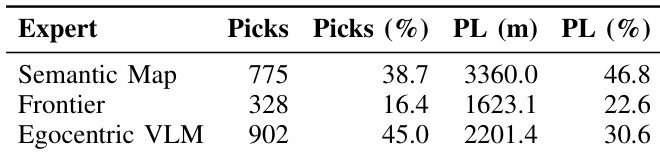
奖励结构分析将总奖励分解为各个组成部分,以解释老虎机的行为。语义信号,特别是余弦相似度和 VLM 置信度,主导了奖励分布,显著超过了覆盖率等探索性因素。这表明随着地图变得更加丰富,系统将重心转向语义推理与利用。余弦相似度是主导成分,贡献了近一半的总奖励值。VLM 置信度是第二大正向贡献者,凸显了视觉推理的重要性。回溯惩罚降低了总奖励,而任务完成率和覆盖率相较于语义项作用较小。
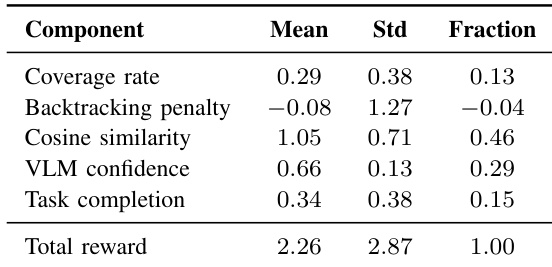
该表格展示了三种决策专家在低、中、高环境覆盖率阶段的归一化奖励。数据表明了一种战略转移:前沿探索在早期的低覆盖率阶段奖励最高,自我中心 VLM 在中覆盖率阶段领先,而语义地图结合自我中心 VLM 在高覆盖率阶段占据主导。这一演进过程表明,随着环境理解的加深,系统从几何探索过渡到语义推理。前沿探索在低覆盖率阶段产生最高奖励,优先考虑快速的几何地图扩展。自我中心 VLM 在中覆盖率阶段成为奖励最高的策略,表明对局部语义线索的依赖。语义地图和自我中心 VLM 在高覆盖率阶段获得最高奖励,反映了对语义利用的侧重。
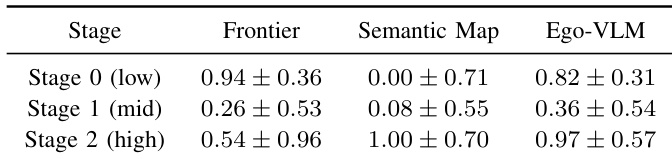
本文在物理四足机器人上评估了 RoboAtlas 框架,展示了其在真实场景中执行多样化用户指令的能力。该系统在所有试验中实现了完美成功率,成功定位了从简单对象到复杂关系查询的各类目标。最终的安全距离因指令而异,本文将其归因于深度估计的不准确性以及避障所需的安全余量。机器人在所有测试的用户指令中均达到 100% 的成功率。安全距离因任务而异,机器人维持的安全余量影响了最终到达目标的距离。观察到的距离误差归因于深度估计的不准确性以及避障系统强制实施的安全余量。
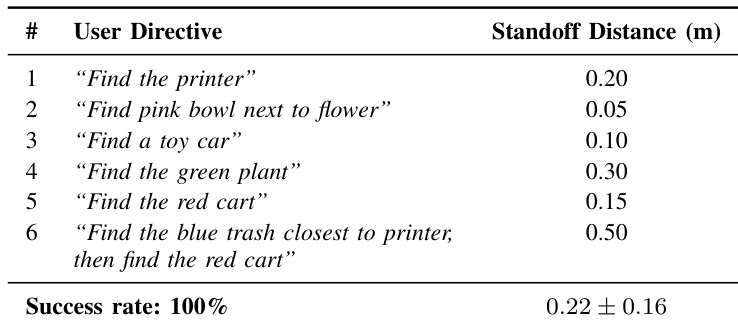
上下文多臂老虎机策略在评估期间将决策分配给三个不同的专家。语义地图专家负责大部分总路径长度,表明其在远程导航与利用中的核心作用。相比之下,自我中心 VLM 专家被选中的频率最高,但贡献的行驶距离比例较小,表明其侧重于频繁的近程调整。前沿专家被选中的频率最低,却占据了路径长度的显著部分,凸显了其在探索中的特定效用。自我中心 VLM 专家被选中的频率最高,但贡献的总路径长度比例较小,表明其用于频繁的近程微调。相对于其选择频率,语义地图专家占据了最大的路径长度份额,反映了其在远程语义利用中的作用。前沿专家被选中的频率最低,却贡献了不成比例的路径长度,表明其保留用于初步探索。
实验通过仿真与物理四足机器人试验,将上下文多臂老虎机导航框架与固定策略基线进行对比,验证了其自适应决策能力。定性分析表明,随着环境理解的加深,系统战略性地从早期的前沿几何探索转向语义推理与利用,视觉与语义信号在奖励结构中占据主导地位。专家分配进一步揭示了互补的分工:语义地图负责远程导航,自我中心 VLM 管理频繁的近程调整,前沿探索引导初始建图。综合来看,这些发现证实基于上下文线索动态选择专家的方法始终优于单一策略方法,从而能够在多样化的真实世界指令中实现可靠且高效的任務执行。