Command Palette
Search for a command to run...
OCR推理的鲁棒性如何?评估视觉语言模型在视觉扰动下的OCR推理鲁棒性
OCR推理的鲁棒性如何?评估视觉语言模型在视觉扰动下的OCR推理鲁棒性
Yuxing Cheng Yuan Wu Yi Chang
摘要
视觉-语言模型(VLMs)在基于光学字符识别(OCR)的基准测试中取得了优异性能,并日益聚焦于文本密集型理解,但其在受控视觉退化条件下的鲁棒性仍未得到充分研究。这一研究空白对OCR推理至关重要,因为视觉损坏可能引发OCR识别错误与结构扭曲,从而为推理任务引入不确定性。为系统性地探究该问题,本文提出OCR-Robust基准,旨在评估视觉扰动条件下OCR推理的鲁棒性。该基准共包含812个样本,分为两个互补的子集:OCR1.0涵盖文档、场景文本、收据、手写体及数学内容;OCR2.0则侧重于图表、几何图形与表格。为实现高效且具信息量的评估,我们对18种候选扰动开展了预实验,并依据其影响程度与跨模型区分能力,筛选出5种代表性扰动类型,每种类型设置3个严重程度等级。我们采用干净准确率、相对损坏保留率(Relative Corruption Retention, RCR)、最坏情况保留率(Worst-Case Retention, WCR)以及复合损坏鲁棒性指数(Corruption Robustness Index, CRI)对鲁棒性进行评估,并对涵盖专有系统、开源VLM以及OCR+LLM流水线在内的18个模型进行基准测试。实验结果表明,更高的干净准确率并不必然意味着更强的鲁棒性;在结构敏感的OCR任务中,模型在最坏情况下可能出现显著的性能退化;此外,在扰动条件下,图表与表格相较于类文档输入表现出显著更高的脆弱性。
一句话总结
作者提出了 OCR-Robust,这是一个包含 812 个样本的基准测试,涵盖 OCR1.0 和 OCR2.0 两个子集。该基准通过干净准确率、相对损坏保留率(Relative Corruption Retention)、最坏情况保留率(Worst-Case Retention)以及损坏鲁棒性指数(Corruption Robustness Index),在三种严重程度下对五种视觉扰动类型进行系统评估,从而量化模型在富含文本的推理任务中的鲁棒性。
核心贡献
- 本文提出了 OCR-Robust 基准测试,包含 812 个样本,分为用于自然文本的 OCR1.0 和用于图表、表格等结构化视觉内容的 OCR2.0。该数据集提供了一个可控的诊断环境,用于系统评估视觉扰动如何影响富含文本的感知及下游推理过程。
- 一套规范化的扰动选择流程对 18 种候选视觉损坏进行评估,筛选出五种具有区分度的类型,每种类型均设置三个严重程度等级。该方法论建立了一个可复现的框架,用于在受控降级条件下探测模型敏感性。
- 本研究开发了一套鲁棒性指标体系,包括干净准确率、相对损坏保留率(RCR)、最坏情况保留率(WCR)以及综合损坏鲁棒性指数(CRI),该指数整合了基线能力、平均保留率和最坏情况风险。通过对 18 款闭源、开源及 OCR 结合 LLM 模型的评估,展示了这些指标如何量化视觉损坏导致的性能下降。
引言
视觉语言模型在文档理解和文本识别的干净基准测试中取得了显著成果,但在实际应用中,当图像出现模糊、光照不均或物理形变时,其可靠性往往难以保证。既往研究大多忽视这一差距,将评估重点放在原始数据或通用物体识别上,忽略了视觉损坏引入离散符号错误并严重干扰下游推理过程的具体风险。作者提出了 OCR-Robust 基准测试,旨在系统评估视觉扰动下的 OCR 推理鲁棒性。该基准包含自然与结构化内容的多样化数据集、经过规范筛选的五种有效扰动类型,以及包含相对损坏保留率和最坏情况保留率在内的指标体系,用于诊断模型脆弱性。
数据集

-
数据集构成与来源 作者提出了 OCR-Robust 基准测试,包含 812 个样本,旨在评估视觉扰动下的 OCR 推理鲁棒性。该数据集由两个互补子集组成:涵盖文档、场景文本、收据、手写体和数学内容的 482 个样本的 OCR1.0,以及专注于图表、几何图形和表格的 330 个样本的 OCR2.0。OCR2.0 的数据来源于 ChartVQA、GNS-260K 和 TableVQA-Bench。OCR1.0 整合了来自 DocVQA、TextVQA、MTWI、SROIE、Screen2Words、M6Doc、OCR-Reasoning 和 InfographicVQA 的数据,数学子集则源自 GSM8K 和 TheoremQA。
-
子集详情与构建 针对 OCR2.0,作者采用视觉多样性采样策略,提取 ResNet50 特征,执行包含 150 个簇的凝聚层次聚类,并选择最接近簇中心的样本。OCR1.0 对样本采用直接筛选,对其他子集采用视觉语言模型辅助标注。作者使用 GPT-5.2、Gemini-3-Pro 和 Claude-Sonnet-4.5 生成推理问题,每张图像随机选用一个模型,随后进行人工验证。数学子集通过合成方式构建,将原始问题转换为自由格式答案,利用 GPT-4o-image 渲染图像,并使用 PaddleOCR 进行过滤以确保字符召回率超过 0.9。
-
使用方式与评估协议 该数据集仅作为评估基准,而非训练集。作者采用零样本评估协议来衡量模型性能。基于 18 个候选扰动的预实验,筛选出五种扰动类型,每种类型设置三个严重程度等级。最终采用的扰动包括玻璃模糊(glass blur)、颜色偏移(color shift)、弹性形变(elastic transform)、运动模糊(motion blur)和雪花(snow)。作者使用 OpenCV 和 PIL 实现扰动处理,固定随机种子以保证可复现性,并将扰动后的图像保存为 PNG 格式以避免压缩伪影。预实验阶段的严重程度校准采用 LPIPS 距离,以确保不同扰动类型在感知上保持一致。
-
处理流程与质量控制 作者实施严格的质量控制,包括对答案可验证性、OCR 必要性及图文一致性的手动审查。通过感知哈希算法(距离阈值为 5)移除近似重复图像。图像需满足最低 224×224 像素的分辨率要求,且均方根对比度阈值需大于 15。为进行多样性采样,图像在特征提取前会预处理为 256 像素并中心裁剪至 224 像素。作者还基于 PaddleOCR 的字符召回率对合成数学样本进行过滤,以维持文本保真度。
方法
评估协议首先执行严格的答案标准化步骤,以确保真实标签与预测结果之间的对比一致性。两种答案均经过标准化处理,包括将文本转为小写、移除标点符号(小数点和货币符号除外)、去除首尾空白字符,以及将多个连续空格合并为单个空格。完成标准化后,系统会尝试直接精确匹配。
在精确匹配失败的情况下(多选题除外),协议采用备用机制,调用 GPT-4o 作为语义裁判。该方法特别适用于自由格式答案,此类答案在保留底层含义的同时可能存在表述差异。为验证该自动化裁判的可靠性,作者对调用 GPT-4o 的 367 个案例进行了人工审查。结果显示系统具有高度稳定性,GPT-4o 与人工标注者的一致性达到 99.18%,OCR1.0 和 OCR2.0 的 Cohen’s κ 分数分别为 0.967 和 0.903。人工检查中仅发现 3 例判断不一致。
为引导模型输出,评估框架融入了基于特定答案类型的格式提示。这些提示统一附加至提示词中。例如,货币价值问题可能包含指定预期格式的提示,如 "$ + Integer"。通用提示词结构整合输入图像、问题文本及特定格式提示,指示模型直接输出答案而不附加解释。
提示词模板结构如下所示:

如图上所示,提示词模板确保模型接收关于预期输出格式的明确指令。尽管格式提示在理论上可能偏向于接受结构化输出训练的模型,但作者未观察到系统性偏差,并指出相似架构模型之间的性能差距依然显著。
实验
OCR-Robust 基准测试在受控视觉扰动下评估闭源视觉语言模型、开源变体以及解耦的 OCR-LLM 流水线,以检验其在自然场景与结构化文档中的推理韧性。结果表明,闭源系统始终表现出更优的最坏情况保留率,而扩大模型规模或采用思维链推理虽能提升基线准确率,却未能可靠缓解由损坏引发的失效问题。此外,结构化视觉内容比自然文本更易受降级影响,模块化流水线仍受限于光学字符提取瓶颈,而非下游推理能力。这些发现表明,鲁棒的视觉理解需要超越单纯规模扩展或提示工程的专用架构策略,将 OCR 鲁棒性定位为独立的评估挑战。
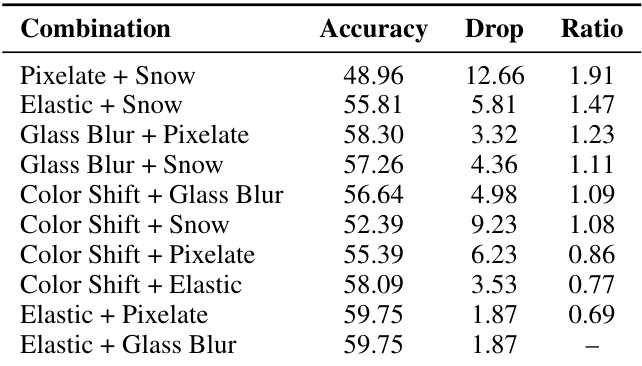
作者通过评估视觉降级的三重组合来研究复合扰动。结果显示,增加多种扰动类型并不总是导致成比例的性能下降。包含颜色偏移和雪花的组合表现出相似的性能与次加性特征,而包含像素化的组合则获得更高准确率但呈现超加性降级比率。包含颜色偏移、玻璃模糊和雪花的组合表现出相似的性能与次加性降级比率。弹性形变、玻璃模糊与像素化的组合实现更高准确率及超加性降级比率。研究发现,重叠的失效模式会限制多重扰动的累积影响。

作者评估了各类多模态语言模型与 OCR 流水线对视觉扰动的鲁棒性。结果表明,闭源系统在损坏条件下通常比开源模型保持更好的性能稳定性。此外,评估显示模型对影响结构化视觉内容的扰动比对自然场景文本的扰动更为敏感。闭源模型在热力图中始终显示较浅的颜色,表明其相对准确率下降幅度低于开源模型。结构化内容的热力图整体色调较深,表明模型在此类数据上遭受更大的性能降级。颜色偏移和雪花等扰动在多数模型中关联深色区域,表明其导致更显著的准确率损失。

作者利用 GPT-5.1 对复合扰动进行预实验分析,以考察多种视觉降级如何相互作用。他们评估了五种扰动类型的两两组合,并计算降级比率,以确定组合效应相较于单一扰动是加性、次加性还是超加性。像素化与雪花的组合导致最大的准确率下降及超加性交互,表明纹理损伤与遮挡会强烈叠加。涉及较弱扰动的配对(如弹性形变或玻璃模糊与其他组合)通常呈现次加性特征,即组合影响小于各效应之和。颜色偏移与雪花的组合表现出近加性交互,而其他配对则根据具体扰动类型呈现不同程度的次加性。
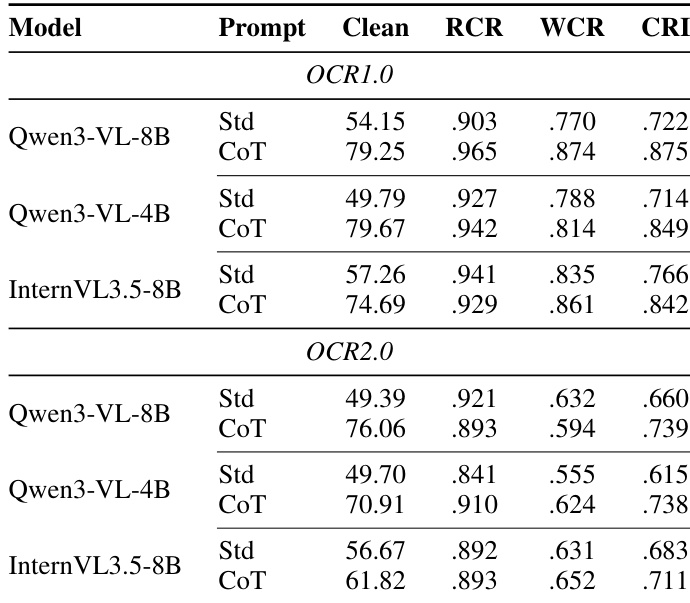
作者评估了思维链(CoT)提示与标准提示在两个 OCR 推理数据集上对三款开源视觉语言模型的影响。数据显示,CoT 始终能显著提升干净准确率,并普遍提高损坏鲁棒性指数。然而,其对最坏情况保留率和相对损坏保留率等具体指标的影响并不一致,尤其在第二个数据集上表现明显,这表明扩展推理主要强化基线性能,而非均匀提升抗损坏韧性。与标准提示相比,CoT 提示在所有模型和数据集上均稳定产出更高的干净准确率。损坏鲁棒性指数通常随 CoT 改善,但最坏情况保留率的收益并非适用于所有模型与数据集组合。CoT 带来的性能提升在第一个数据集上更为稳定,而第二个数据集尽管准确率有所提高,却显示出保留率指标更大的波动性。
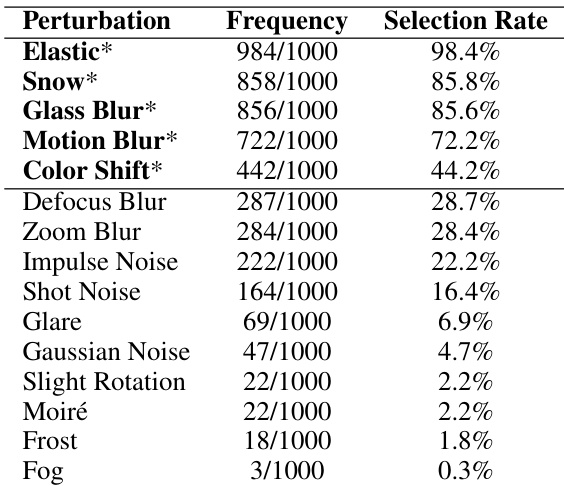
作者通过重采样预实验问题一千次,执行 Bootstrap 稳定性分析以评估扰动选择的可靠性。下表展示了各候选扰动在这些重采样中的频率与选择率。数据证实,最终确定的五种扰动被选中的频率始终高于其他候选项,验证了实验设置的合理性。弹性形变被选中的频率最高,出现在绝大多数重采样迭代中。标记为最终选择的五种扰动始终优于散焦模糊和各种噪声类型等替代方案。颜色偏移的选择频率明显低于排名靠前的扰动,表明其在选择标准中占据的权重较低。
实验评估了多模态与 OCR 模型对单一、两两组合及三重视觉扰动的鲁棒性,检验了思维链提示的影响,并通过 Bootstrap 重采样验证了扰动选择的有效性。结果表明,闭源系统通常比开源模型保持更高的稳定性,尤其是在处理结构化视觉内容时;由于失效模式重叠,复合降级很少导致成比例的性能下降。此外,思维链提示始终能提升基线准确率与整体鲁棒性,但并未均匀增强最坏情况下的损坏保留率;最终扰动组合在重采样试验中表现出极高的选择一致性,证实了实验设计的可靠性。