Command Palette
Search for a command to run...
用于机器人控制的上下文内世界建模
用于机器人控制的上下文内世界建模
Siyin Wang Junhao Shi Senyu Fei Zhaoyang Fu Li Ji Jingjing Gong Xipeng Qiu
摘要
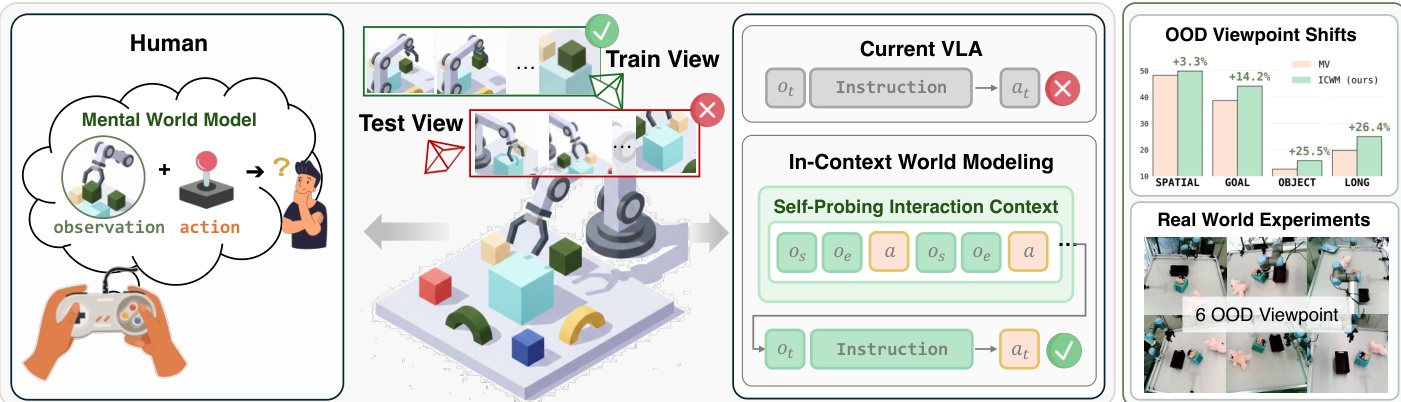
现代视觉-语言-动作(VLA)模型通常仅以当前观测和语言指令为条件,因此往往难以泛化至新颖场景,例如改变的相机视角或机器人形态。由于未将底层系统配置视为变量,这些模型隐式地假设了训练期间所遇到的固定执行上下文,导致面对任何新环境时均需进行数据密集型的微调。在本研究中,我们提出了上下文世界建模(In-Context World Modeling, ICWM)框架,该框架将系统识别视为一种上下文适应问题。ICWM 使机器人策略能够从短期自主生成的、与任务无关的交互历史中推断出关键系统变量。与利用演示数据来指定执行何种任务的传统上下文学习(In-Context Learning)不同,ICWM 利用上下文窗口来理解系统的运行机制。通过在任务执行前处理这些交互数据,该模型隐式地捕获了当前系统的物理世界动态,从而能够在无需更新参数的情况下适应新颖的配置。在仿真环境与真实机器人平台上的大量实验表明,ICWM 在应对新颖相机视角时显著优于标准的 VLA 基线模型。
一句话总结
将系统辨识视为无需参数更新的上下文内自适应,上下文世界建模(In-Context World Modeling, ICWM)使 VLA 模型能够从自生成的、任务无关的短交互历史中推断系统变量,从而适应新颖的相机视角和机器人形态,并在仿真与现实世界实验中显著优于标准 VLA 基线。
核心贡献
- 上下文世界建模(ICWM)使视觉-语言-动作策略能够从自生成的、任务无关的交互中推断系统配置,在测试时实现自适应而无需参数更新。
- 与传统的指定“做什么”的上下文学习方法不同,ICWM 利用上下文窗口来理解系统如何运作,隐式地捕捉世界动态,以适应新颖的相机视角、机器人形态和语义场景变化。
- 在仿真基准和现实世界机器人上的实验表明,ICWM 在新颖相机视角上显著优于标准 VLA 基线,并能泛化到其他配置变化,而无需任务特定的演示或奖励信号。
引言
在机器人操作中,视觉-语言-动作(VLA)模型将视觉观测和语言指令直接映射为动作,但当部署条件(如相机视角或机器人形态)与训练时发生变化时,它们往往表现不佳。标准 VLA 公式仅依赖于当前观测进行条件化,隐式地将底层系统配置视为固定不变的,并将其吸收进静态模型参数中。先前的自适应策略依赖于任务特定的人类演示、奖励信号或参数微调,因此缺乏在测试时辨识系统动力学的实用机制。作者提出了上下文世界建模(ICWM),将该问题重新表述为测试时系统辨识任务:机器人自主生成一小段任务无关的探索性动作,并将由此产生的视觉变化作为上下文前置,使策略能够隐式地恢复当前的感知-运动映射,从而适应新颖的配置,无需参数更新或人类提供的演示。
数据集
作者在一个配备 Robotiq 平行夹爪和 12 个相机阵列的 6 自由度 UR5e 机械臂上收集了一个真实世界多视角操作数据集。该数据集用于训练一个具备上下文系统辨识机制的视觉-语言-动作模型。
-
任务覆盖范围与规模
包含四项任务,每项任务录制了 100–150 次人类遥操作演示:
将盒子上的玩具放入篮子(空间推理与消歧),
将黄色杯子叠放到红色杯子上(精细对齐),
提起篮子(以手柄为中心的结构性操作),
拿起茄子并将其放在红色盘子上(杂乱场景中的多物体定位)。
每次演示均提供多视角 RGB 流、末端执行器动作和相应的语言指令。 -
相机划分与泛化协议
12 个相机被分为相等的两组:6 个指定用于训练,另外 6 个专门保留用于零样本泛化测试。这种均衡的划分迫使模型从交互上下文中推断系统动力学,而非记忆相机到机器人的几何关系。 -
训练数据与处理
训练使用来自 6 个训练相机的全部演示,除自然的演示数量外不进行显式的任务平衡。对于每个训练样本,作者将 N 个任务无关的交互片段 前置到一个完整的演示回合之前。这些片段从涵盖所有任务和视角的完整训练轨迹集中提取的短交互片段池中随机抽取;采样确保了交互上下文的多样性。然后模型接收整个序列,并以前置的交互上下文、当前观测和语言指令为条件,使用下一动作预测损失进行优化。除此外置片段的步骤之外,不进行任何图像裁剪或特殊元数据构建。 -
隐式动力学信号
由于交互片段是从多样化相机配置下采集的轨迹中抽取的,前置上下文的差异充当了隐式训练信号:模型必须学习提取能表征当前系统配置的动作到观测的映射关系,从而实现对未知视角的零样本适应。
方法
作者提出了上下文世界建模(ICWM),以解决标准视觉-语言-动作(VLA)模型在分布外系统配置(如新颖相机视角或机器人形态)下泛化能力崩溃的问题。不同于需要专用参数来预测未来观测或逆向动力学的传统世界模型,ICWM 隐式地实现了世界建模。它利用标准序列建模,直接从任务无关的交互历史中提取时不变的因果结构,将世界建模视为测试时涌现的推理能力。
如下图所示,作者将标准 VLA 方法与他们的 ICWM 方法进行了对比。当前 VLA 将观测和指令直接映射为动作,在视角变化下失败,而 ICWM 结合了自探测的交互上下文来适应特定的视觉和物理设置。
该方法建立在部分可观测马尔可夫决策过程(POMDP)公式之上,其中潜在状态分解为一个时不变的系统配置 ψ 和一个时变的场景状态 ξk。作者将交互上下文定义为 T=(o0:t,a1:t),并证明在部分可观测性和信息保持转移的温和假设下,该上下文关于 ψ 所携带的信息严格多于任何单一观测。这使得任务无关的随机运动能够丰富关于系统配置的信息。
有关训练和推理流程的详细视图,请参考框架图。
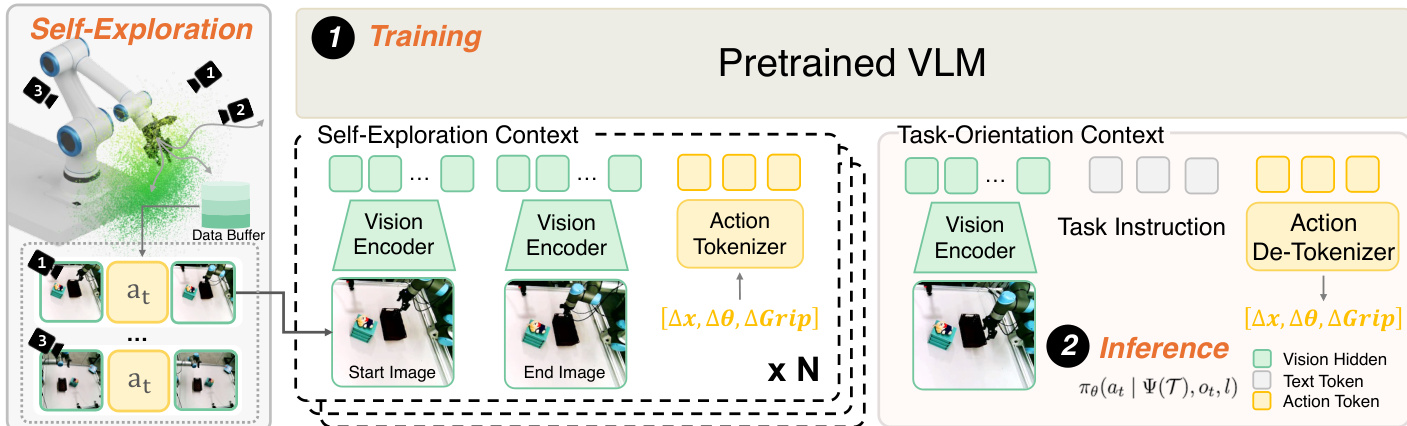
在训练期间,模型使用在不同系统配置下收集的数据进行训练。任务无关的交互片段被前置到每个训练样本中作为上下文。具体来说,给定一个短的交互片段历史 T={(ois,ai,oie)}i=1N,系统配置通过一个函数 Ψ(T) 隐式推断。策略被重新表述为以该推断出的表征为条件:
at∼πθ(at∣Ψ(T),ot,l)这种以交互为中心的条件化方式使模型能够在正确的上下文中解释当前观测 ot。
在部署时,ICWM 通过一个无需梯度更新的两阶段推理协议实现免演示自适应。
主动探测阶段:在执行任务之前,机器人执行 N 个任务无关的探测动作以收集交互上下文 T。随机目标姿态在安全工作空间内采样,机器人执行动作以达到这些姿态,并记录状态转移 (ois,ai,oie)。这些运动在空间上是多样化的,以覆盖局部动力学流形,同时不干扰与任务相关的物体。
上下文执行阶段:一旦收集到 T,配置推理函数 Ψ 处理上下文以恢复潜在的系统配置。以 Ψ(T)、当前观测 ot 和语言指令 l 为条件,策略生成任务动作。由于 Ψ 与 VLA 主干共享参数,这被实现为单次前向传播,其中 Transformer 首先处理 T 以构建配置感知的隐藏状态,然后再处理任务查询。
实验
评估采用了 LIBERO 上的跨视角协议和真实的 UR5e 多相机平台,在未见视角、长时程任务、语义干扰和修改后的机器人运动学条件下,测试了上下文世界建模(ICWM)与多视角行为克隆和显式相机参数方法的对比。在这些设置中,ICWM 通过使用短交互前缀隐式地辨识系统几何结构,而非进行模式匹配,始终优于基线;消融实验表明,移除视觉结果或提供错位上下文会严重降低性能,证实了模型主动依赖成对的观测-动作序列进行校准。该方法还泛化到干扰物体、新颖纹理和形态变化(如变化的连杆长度),在运动学不确定性增加时保持了稳定的优势,同时驱动收益的是交互格式本身,而非特定的探测策略。总体而言,ICWM 提供了一种无参数机制,将动作根植于当前系统动力学中,从而能够稳健地适应多样的分布偏移。
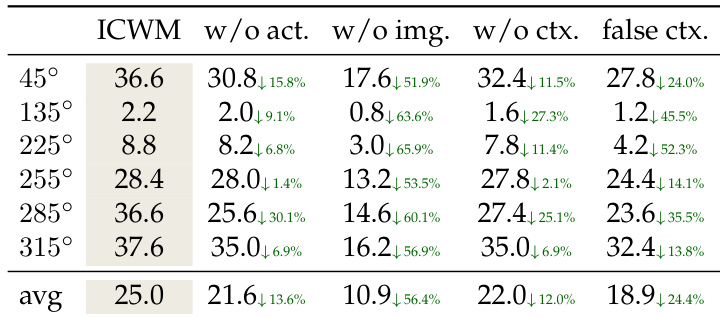
作者对交互上下文的组成部分进行了消融研究,以评估它们对上下文世界建模方法的必要性。结果表明,移除视觉结果会导致最严重的性能下降,因为模型无法区分探索性运动和任务演示。此外,提供来自不同视角的错位上下文比完全不提供上下文表现更差,这证实了模型在配置推断中主动依赖上下文内容。移除图像 token 会导致最大程度的性能崩塌,表明视觉结果对于动作的根植至关重要。来自偏移视角的错误上下文比无上下文产生更差的结果,表明错位信息会主动误导策略。移除动作 token 导致中等程度的下降,这表明视觉流提供了一个空间锚点,但完整的校准需要完整的观测-动作元组。
作者在四个任务套件的域外观角度上评估了上下文世界建模方法,并将其与多视角基线、显式配置方法和预训练模型进行比较。结果表明,所提出的方法在所有任务类别中始终取得最高的平均成功率,证明了对未见相机角度具有优越的泛化能力。虽然标准多视角训练和显式角度输入提供了一定的鲁棒性,但它们都未能达到通过交互上下文进行隐式世界建模所获得的性能。所提出的方法在平均成功率上优于所有基线,包括多视角行为克隆和显式配置。预训练的视觉-语言-动作模型在未见视角下明显表现不佳,与所提出的方法相比,其成功率通常接近零。由于几何约束,135 度视角对所有评估方法来说都是一个常见挑战,但所提出的方法仍保持相对优势。
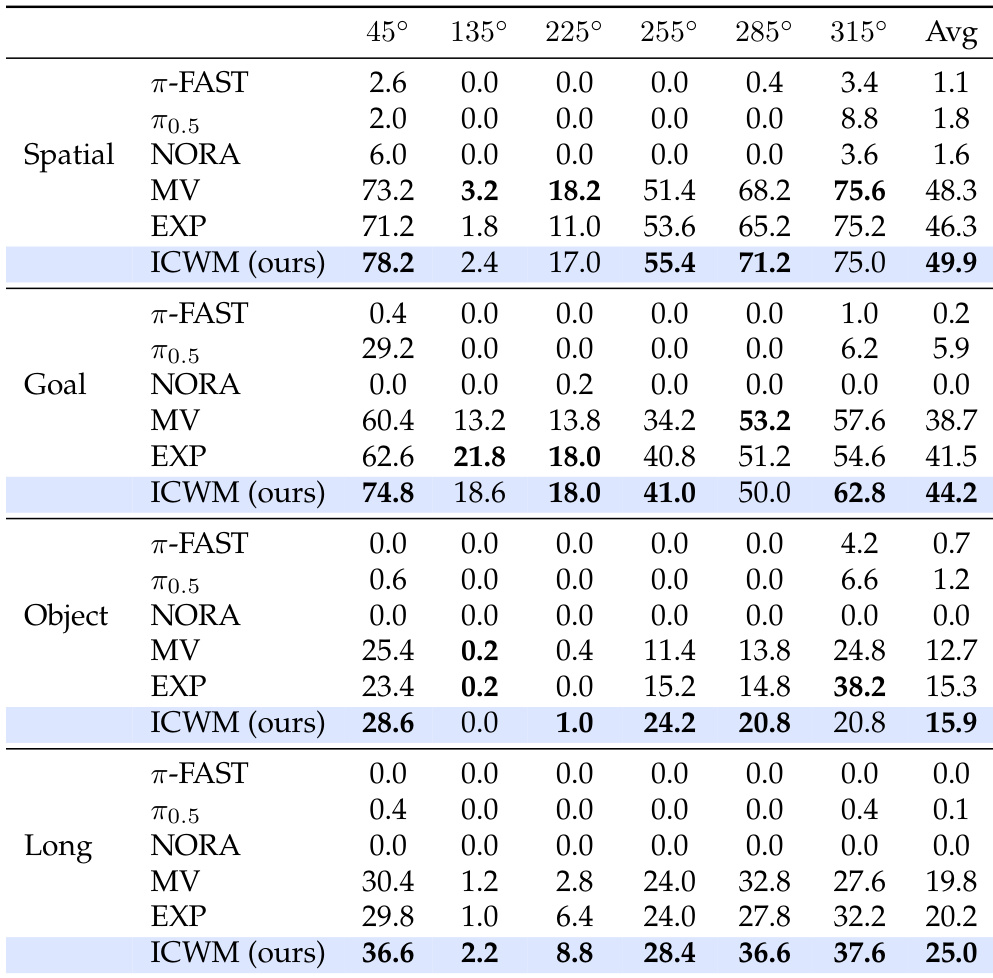
作者在四个任务套件的域内视角上评估了上下文世界建模,并将其与多视角基线、显式配置方法和预训练模型进行比较。结果表明,所提出的方法在所有任务类别中始终取得最高的平均成功率,展现出相较于标准多视角训练和增强了真实相机角度的方法的优越性能。虽然所有模型在长时程任务中都面临更大困难,但所提出的方法保持了明显的领先优势,而预训练模型在许多配置中表现出接近零的成功率。与多视角和显式配置基线相比,所提出的方法在所有任务套件中取得了最高的平均成功率。预训练模型的性能显著低于训练过的基线,在特定视角下往往完全失败。长时程任务对所有模型都构成更大挑战,但所提出的方法仍然保持了最佳的余量优势。
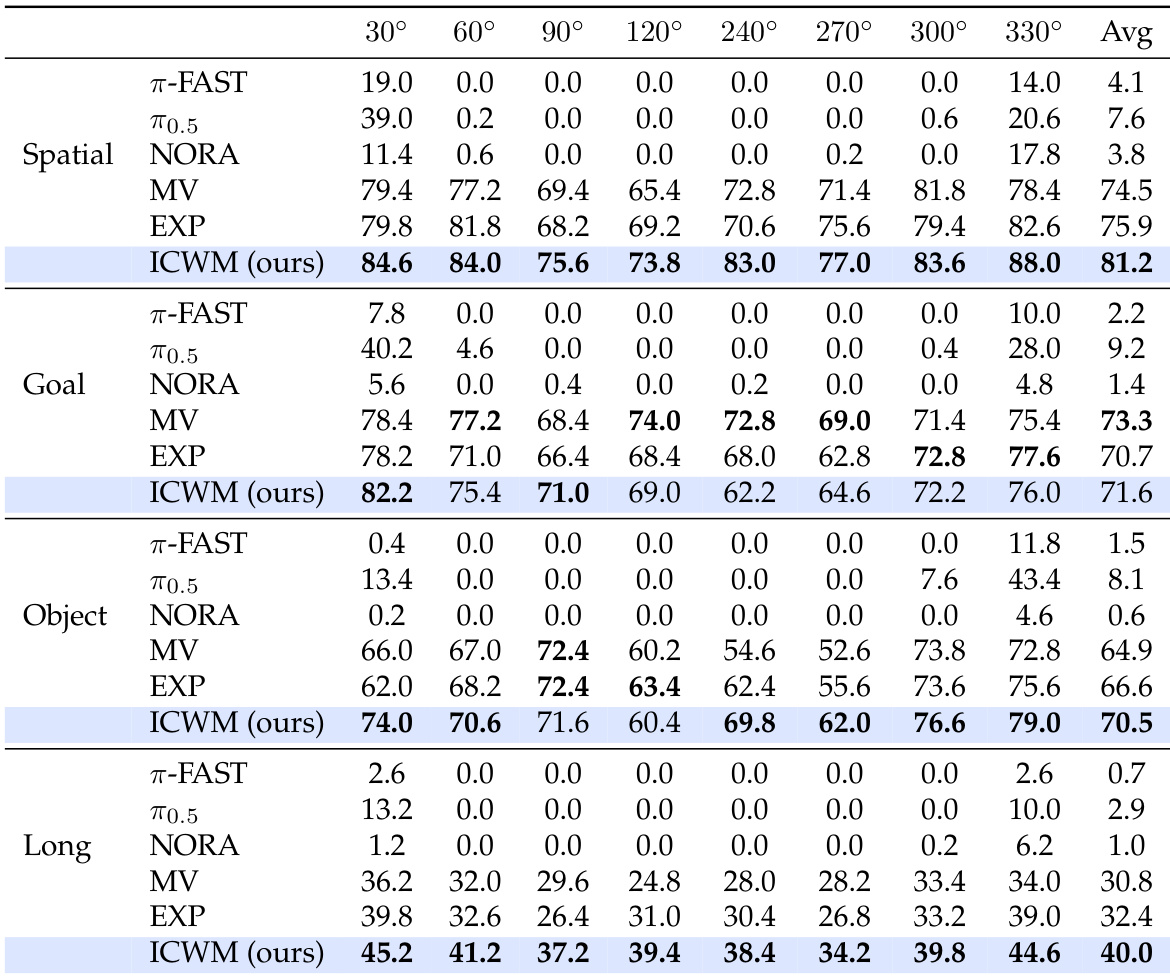
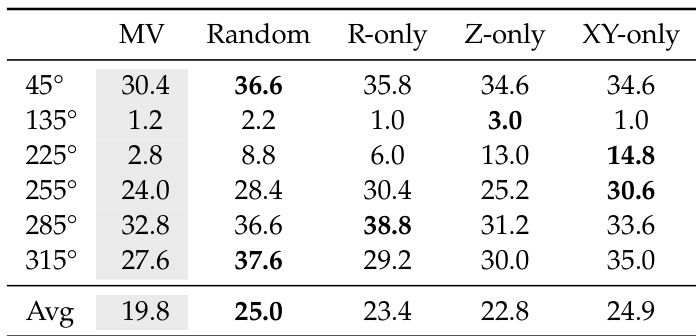
作者在分布外观角上评估了上下文世界建模的不同探测策略。结果表明,所有测试策略都显著优于多视角基线,表明驱动性能增益的是交互格式本身,而非特定的运动模式。没有哪种单一探测策略在所有视角上都占据主导地位,表明不同的轴揭示了局部动力学流形的不同方面。所有四种探测策略在分布外观角上始终优于多视角基线。没有哪种单一探测策略在所有视角上都占主导地位,因为不同的轴暴露了局部动力学流形的不同方面。在所测试的策略中,随机探测取得了最高的平均性能。
作者通过对交互上下文的消融研究、视角泛化测试和探测策略比较来评估上下文世界建模。消融实验表明,视觉结果对于动作的根植至关重要,而错位上下文会主动误导策略。在域内和域外观角上,该方法始终优于多视角和显式配置基线,而预训练模型往往完全失败。探测实验表明,驱动性能增益的是交互格式本身,因为所有策略都超越了多视角基线,且没有出现单一的占主导地位的模式。