Command Palette
Search for a command to run...
改进的大型语言扩散模型
改进的大型语言扩散模型
Shen Nie Qiyang Min Shaoxuan Xu Zihao Huang Yuxuan Song Yong Shan Yankai Lin Wayne Xin Zhao Chongxuan Li Ji-Rong Wen
摘要
现代大型语言模型主要采用自回归分解和因果注意力机制进行训练。我们提出了 iLLaDA,这是一个拥有 80 亿参数(8B)的掩码扩散语言模型(Masked Diffusion Language Model),采用完全双向注意力机制从头开始训练。iLLaDA 在预训练和监督微调(SFT)阶段均保持掩码扩散目标函数不变,其中预训练规模扩展至 12T token,并在包含 25B token 的指令语料库上进行 12 个 epoch 的微调。为了提升效率,我们进一步采用了变长生成技术,并引入了基于置信度的评分机制用于多项选择任务评估。与 LLaDA 相比,iLLaDA 在通用、数学和代码领域的各项基准测试中均取得了广泛提升;例如,iLLaDA-Base 在 BBH 上提升了 21.6 分,在 ARC-Challenge 上提升了 14.9 分,而 iLLaDA-Instruct 在 MATH 上提升了 14.5 分,在 HumanEval 上提升了 16.5 分。尽管采用非自回归训练方式,iLLaDA 在多项基准测试中仍与 Qwen2.5 7B 保持竞争力。这些结果表明,从头开始进行完全双向扩散训练是构建高性能语言模型的一条具有竞争力的路径。模型权重及代码已公开:https://github.com/ML-GSAI/LLaDA。
一句话总结
作者提出了iLLaDA,一个8B参数的掩码扩散语言模型,从头开始训练,使用完全双向注意力,并在12T预训练token上进行掩码扩散目标训练,在25B指令token上微调12个epoch,融合了可变长度生成和基于置信度的评分机制,相比LLaDA取得了全面提升,并与Qwen2.5 7B保持竞争力。
核心贡献
- iLLaDA,一个8B参数的掩码扩散语言模型,从头开始训练,使用完全双向注意力,并在整个预训练阶段(共12T token)和基于25B token指令语料库的监督微调(共12个epoch)中保持掩码扩散目标。
- 采用可变长度生成以提高推理效率,并引入了基于置信度的评分机制用于多项选择评估。
- iLLaDA相比之前的LLaDA模型有了广泛提升,基础版在BBH上提升了21.6分,在ARC-Challenge上提升了14.9分,并且与Qwen2.5 7B保持竞争力,表明完全双向扩散从头训练是强语言模型的一个可行方向。
引言
本文探讨了在语言生成领域扩展扩散模型的挑战,该领域一直由自回归架构主导。扩散模型在图像合成等连续领域表现出色,但在离散文本数据上则面临困难,在大规模情况下质量和效率都落后于自回归Transformer。作者提出了大型语言扩散模型的关键改进,缩小了这一差距,证明基于扩散的语言模型可以实现与自回归模型相当的性能,同时提供并行解码和可控生成等潜在优势。
方法
作者提出了iLLaDA,一个8B参数的掩码扩散语言模型,从头开始训练,使用完全双向注意力。核心方法在预训练和监督微调阶段均保持掩码扩散目标,使模型能够学习鲁棒的双向表示。
在预训练过程中,模型优化一个基于似然的离散数据掩码扩散目标。给定长度为L的干净序列x0,作者从0到1的均匀分布中采样一个掩码比例t。每个token以概率t独立地被替换为掩码token,形成损坏序列xt。然后模型被训练来预测所有被掩码的token,使用以下损失函数:
L(θ)≜−Et,x0,xt[t1∑i=1L1[xti=M]logpθ(x0i∣xt)]
此处,指示函数确保损失仅针对被掩码的token计算,从而将该方法与使用固定掩码比例的传统掩码语言建模区分开来。
模型的主干是一个密集Transformer,包含RMSNorm、SwiGLU和RoPE,没有任何注意力或MLP偏置。一个关键的架构修改是使用分组查询注意力替代标准的多头注意力。这一设计选择显著减少了缓存式实现中键和值状态的显存占用。此外,作者将输入嵌入和语言模型头参数绑定,以控制总参数量。该模型与其前身之间的架构差异如下图所示:
预训练过程的最大序列长度为8192个token。为了提高效率和稳健性,作者以30%的概率随机将序列分成两个较短的片段。每个批次中打包了变长样本,注意力计算使用基于FlashAttention的变长核,该核利用累积序列偏移量在无填充的情况下分隔样本。学习率线性预热至2×10−4,并保持恒定,直到预训练损失趋于平缓,然后切换到余弦衰减计划,最小学习率为5×10−6。优化使用AdamW优化器,权重衰减为0.1。
在监督微调中,作者不同于先前通常保持提示token可见并仅对回答区域施加掩码的方法。相反,他们采用了与预训练完全相同的数据处理和掩码方案。每个指令样本被格式化为提示-回答序列,后跟一个终止|EOS| token。所有格式化后的样本被连成一个连续的指令语料,从中采样8192个token的训练序列。随即对整个序列施加随机掩码,这意味着提示token、回答token和终止token都可能被掩码。这种统一的掩码格式自然支持变长块生成。
微调语料包含约250亿token,模型训练12个epoch。学习率计划以线性预热至5×10−6开始,然后保持恒定,最后在训练过程的最后10%内线性衰减至5×10−7。再次使用AdamW优化器,权重衰减为0.1。
实验
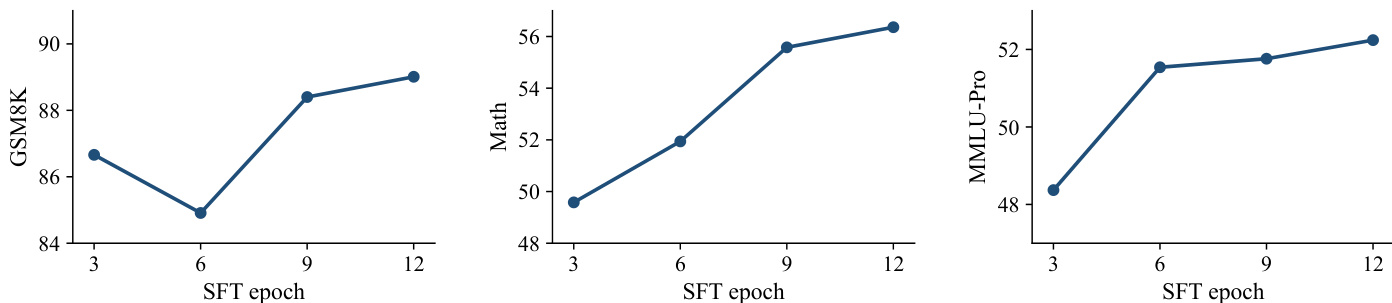
iLLaDA在广泛的语言理解、推理、数学和代码生成基准上进行了评估,包括基础版和指令微调版,并与先前的扩散模型及自回归Qwen2.5 7B进行了比较。基础模型显著提升了双向扩散性能,在若干推理任务上匹敌或超越自回归基线,而指令模型则大幅缩小了差距,但由于缺乏强化学习对齐,在数学和代码方面仍有所落后。消融实验验证了基于置信度的多项选择评分和延长监督微调能带来明显改进,性能在多个epoch中持续提升。总体而言,实验表明双向扩散预训练能够获得强大的通用和推理能力,证明了有竞争力的大型语言模型不必依赖自回归生成。
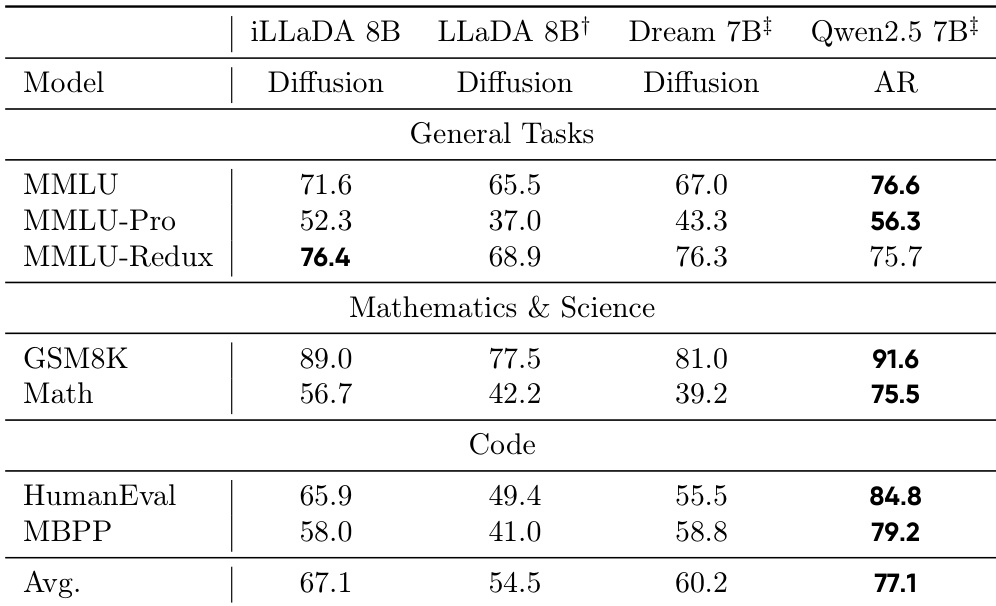
作者将iLLaDA——一个双向掩码扩散语言模型——与其他扩散模型以及一个强大的自回归基线在标准基准上进行了评估。结果表明,iLLaDA在通用、数学和编码任务上显著优于先前的扩散模型,取得了其中最高的平均分。虽然自回归基线在多数基准上仍处于领先,但iLLaDA表现出有竞争力的性能,甚至在MMLU-Redux等特定任务上超越了它。iLLaDA在评估的扩散语言模型中取得了最佳平均性能,相比先前版本有了显著改进。该模型缩小了与强大自回归基线的差距,在通用和数学推理基准上表现具有竞争力。iLLaDA在MMLU-Redux基准上超过了自回归基线,突显了其强大的多任务理解能力。
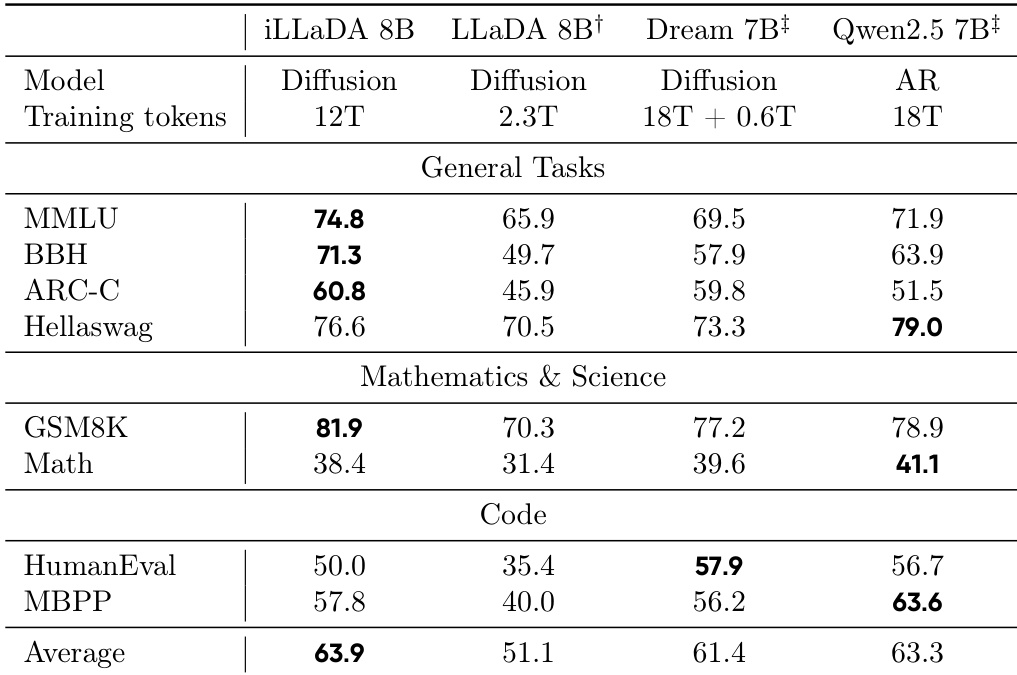
作者比较了基础模型在通用、数学和编码基准上的性能,将提出的iLLaDA 8B扩散模型与LLaDA 8B、Dream 7B以及自回归Qwen2.5 7B进行对比。结果表明,iLLaDA 8B取得了最高的平均性能,相比之前的LLaDA模型有了大幅提升。虽然iLLaDA 8B在若干推理和通用任务上超越了自回归Qwen2.5 7B,但自回归模型在特定编码和高等数学领域仍保持优势。iLLaDA 8B在所有类别中取得了最高的平均分,较LLaDA 8B基线有显著提升。iLLaDA 8B在MMLU、BBH和ARC-Challenge等通用理解和推理基准上超越了自回归Qwen2.5 7B。自回归Qwen2.5 7B和Dream 7B在代码生成任务上保持性能优势,分别在MBPP和HumanEval上领先。
作者对多项选择评分规则进行了消融研究,比较了基于似然的方法与基于置信度的评分方法。结果表明,基于置信度的评分规则在各个基准上始终优于似然基线,因此被采用于多项选择评估。基于置信度的评分在所有测试基准上均取得了比基于似然评分更高的性能。在PIQA和HellaSwag等通用语言理解任务上观察到了改进。基于置信度的方法在ARC-Challenge基准上也取得了更好的结果。

评估将双向掩码扩散语言模型iLLaDA与先前的扩散模型及自回归基线在通用理解、数学推理和编码基准上进行了比较。iLLaDA在扩散模型中始终取得最高平均性能,并缩小了与自回归模型的差距,甚至在MMLU、BBH和ARC-Challenge等某些多任务理解和推理基准上超越了它。对多项选择评分的消融进一步显示,基于置信度规则稳超基于似然的评分,该规则被用于所有评估。总体而言,iLLaDA表现出强大且有竞争力的能力,尤其在推理和阅读理解方面,尽管自回归模型在一些编码任务上仍保持优势。