Command Palette
Search for a command to run...
OpenThoughts-Agent:面向智能体模型的数据配方
OpenThoughts-Agent:面向智能体模型的数据配方
摘要
智能体语言模型极大地拓展了人工智能的应用,然而关于如何为具备广泛能力的 agents 构建训练数据,目前公开的信息寥寥无几。现有的开源工作(如 SWE-Smith、SERA 和 Nemotron-Terminal)通常针对单一基准,使得如何训练能够在多样化智能体任务中泛化的模型这一问题仍未得到解决。OpenThoughts-Agent (OT-Agent) 项目通过一套完全开源的数据构建流水线来解决这一空白,旨在训练智能体模型。我们开展了超过100项受控消融实验,系统性地探究了该流水线的各个阶段,从而揭示了任务来源与多样性的重要性。随后,我们基于该流水线构建了包含10万条示例的训练集,并在该数据集上对 Qwen3-32B 进行微调。该模型在七项智能体基准测试上取得了 44.8% 的平均准确率,较现有基于开源数据的最强智能体模型(Nemotron-Terminal-32B,40.9%)提升了 3.9 个百分点。此外,我们的训练数据展现出显著的缩放特性,在控制计算量的对比实验中,于所有训练集规模下均优于其他开源数据集。我们已在 openthoughts.ai 公开发布了训练集、数据流水线、实验数据及模型,以支持未来针对智能体模型训练的开源研究。
一句话总结
作者推出了 OpenThoughts-Agent 项目,这是一个完全开源的数据策展管道,经过一百多次消融实验的优化。实验表明,在生成的包含 100K 个样本的数据集上微调 Qwen3-32B,可在七个 agentic 基准测试中达到 44.8% 的平均准确率,较 Nemotron-Terminal-32B 提升 3.9 个百分点。该模型展现出强大的扩展特性,同时作者公开了所有数据集、管道代码和模型,以支持未来的 agentic 模型研究。
核心贡献
- OpenThoughts-Agent 项目提供了一个完全开源的数据策展管道,系统性地处理用于训练 agentic 语言模型的数据获取、标注与过滤。完整的训练数据集、数据管道、实验日志及微调后的模型均已公开,以支持可重复的研究。
- 超过 100 项受控消融实验系统性地隔离了管道各阶段的影响,并在任务来源多样性以及监督微调与强化学习数据之间的交互方面提供了可操作的见解。
- 在精心策展的 100K 样本数据集上微调 Qwen3-32B,在七个 agentic 基准测试中取得 44.8% 的平均准确率,较现有最强开源数据基线提升 3.9 个百分点。计算资源受控的评估进一步表明,该数据集展现出强大的扩展特性,在每种训练规模下均持续优于其他开源语料库。
引言
agentic 语言模型通过使系统能够执行复杂的多步计算机任务,彻底改变了人工智能领域,这使得高质量训练数据成为推进开放研究和实际部署的关键。然而,现有的开源数据策展工作通常仅针对单一基准测试,或将监督微调与强化学习割裂开来,导致在如何构建具备广泛能力且可泛化的 agent 方面存在关键认知空白。为解决这一问题,作者采用了一个完全透明的数据策展管道,并通过一百多次消融实验进行系统优化。他们构建了一个多样化的 100K 样本数据集,微调了 Qwen3-32B,并展示了其在跨基准测试中的强大泛化能力与优越的扩展行为。同时,所有相关产物均已公开,以加速未来的 agentic AI 研究。
数据集

-
数据集构成与来源: 作者构建的 OpenThoughts-Agent 数据集由针对监督微调编程与 terminal agent 优化的 (任务, 轨迹) 对组成。最终数据集源自四个主要来源:SWE-Smith(合成 GitHub 问题修复任务)、IssueTasks(合成问题描述)、StackExchange SuperUser(人工撰写的 Linux 与基础设施问题)以及 StackExchange Tezos(人工撰写的加密货币问题)。这些来源共同覆盖了软件工程、系统管理、安全、生物学和机器学习领域。
-
子集详情与扩展: 初始管道消融实验为每种策略生成 10,000 条轨迹,以平衡计算成本与统计可靠性。最终的 OpenThoughts-Agent-v2 数据集扩展至 100,000 条 agentic 轨迹。由于 Tezos 来源仅包含 997 个唯一任务描述,作者使用指令重写技术对其进行合成增强,将表层形式扩展至超过 21,000 种变体,且不引入新的底层问题。其余三个来源保留其原始任务池。
-
训练用途与混合比例: 该数据在消融研究中用于 Qwen3-8B 的全参数监督微调,并在最终扩展阶段用于 32B 模型。轨迹由 GLM-4.7-AWQ 作为 teacher 在隔离的 Daytona 沙箱中,使用 terminus-2 agent harness 生成。对于 100K 数据集,作者保持前四来源的混合比例,并基于 GPT-5-nano 响应长度信号应用按比例上采样策略。每个唯一任务至少获得一次 rollout,剩余容量按其质量分数按比例分配,以确保在所有数据集规模下实现全覆盖。
-
处理与过滤规则: 管道对 agentic rollout 应用严格的启发式过滤器。作者丢弃生成过程中超时的轨迹,移除 subagent 轨迹,并过滤掉回合数少于五次的任何轨迹。这一五次回合的最低要求在所有来源中统一执行,以优先保障更高质量的多回合监督。作者验证了,即使在固定 token 预算下进行匹配,更长轨迹带来的性能提升依然持续存在,证实该收益源于更丰富的监督信号而非额外的计算资源。
方法
作者提出了一种结构化的六阶段监督微调(SFT)数据策展管道,旨在为 agentic 模型生成高质量训练数据。该框架通过一系列混合、过滤与生成步骤,系统地将原始输入转化为最终数据集。
参见框架示意图:

该流程始于 Source Tasks(源任务),作为原始输入池。随后这些任务进入 Mix Tasks(混合任务)阶段,在此阶段组合多样化的任务类型以确保广泛的覆盖范围与鲁棒性。混合之后,Filter Tasks(过滤任务)阶段应用标准从池中剔除低质量或不相关的任务,为生成做准备。
任务集经过精炼后,管道进入 Generate Rollouts(生成轨迹)阶段。在此阶段,为选定的任务生成轨迹,以模拟 agent 行为。这些生成的轨迹随后在 Filter Rollouts(过滤轨迹)阶段进行评估,仅保留高质量且成功的轨迹。
最后阶段涉及模型选择与数据集组装。在 Select Teacher(选择 Teacher)阶段,会选定一个特定模型作为生成最终数据或进一步精炼的 teacher。最终形成 Final Recipe(最终配方),代表已策展完毕并准备用于监督微调的数据集。作者指出,该管道经过了受控消融实验,以明确各阶段的贡献。
实验
评估设置结合了监督微调与强化学习,跨越多个编程与 agentic 基准测试,以系统验证任务生成、数据混合、过滤、teacher 选择以及强化学习数据获取。定性结果表明,融合排名靠前的生成策略并针对复杂问题进行过滤,能够产生最均衡的训练数据;而表现最强的基准测试模型并不一定是最有效的 teacher。强化学习消融实验进一步表明,中等强度的监督检查点从策略优化中获益最多,且数据源对行为轨迹起着决定性作用:类似竞技编程的任务促进有效的探索与严谨的工具使用,而其他数据集则倾向于策略压缩。总体而言,实验证实,经过精心策展的多回合 agentic 轨迹能够持续提升下游推理能力,并在不同模型规模下展现出可靠的扩展性。
作者评估了不同的任务描述过滤策略以提升下游 agent 性能。研究发现,基于 GPT-5 生成的响应长度进行过滤是最有效的方法,具体表现为筛选需要较长响应的任务。该方法在所有测试基准中持续优于其他过滤技术与随机基线。按 GPT-5 响应长度过滤任务(尤其是较长响应)取得了最佳的整体性能。该策略较随机基线实现了约 3 个百分点的显著提升。被识别为需要更多 token 来解答的任务在多样化基准中展现出一致的收益。

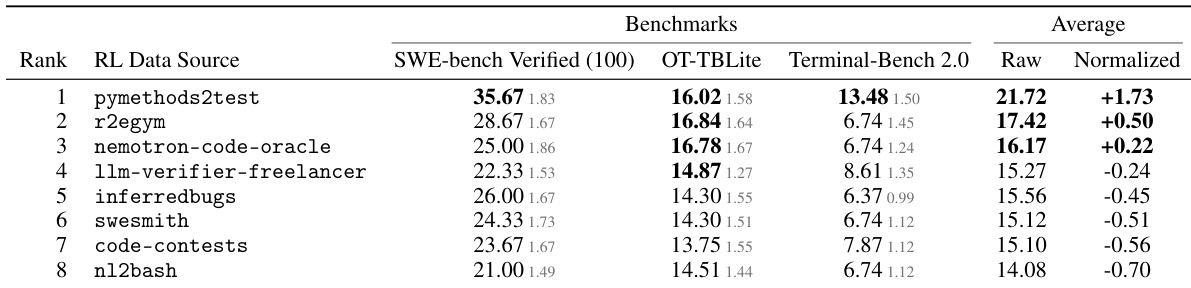
作者评估了多种强化学习数据源以训练 8B 模型,并根据其在多个软件工程与 terminal 基准上的表现进行排名。结果表明,训练数据的选择对下游性能影响显著,其中类似竞技编程的任务产生了最高的整体准确率。尽管专门的合成数据源在分布内基准上表现优异,但更广泛的工具使用数据集在分布外任务上展现出更强的泛化能力,尽管两者均无法匹敌排名第一的数据源的均衡表现。源自竞技编程问题的排名第一数据源在所有评估基准中取得了最高的平均性能。与异构程度更高的工具使用数据集相比,合成数据与竞技编程数据源在分布内任务上表现更强。更广泛的工具使用数据源提供了更好的分布外泛化能力,但在分布内评估中落后于领先数据源。
作者在 Terminal-Bench 2.0 及其更新版本 Terminal-Bench 2.1 上评估了一个代表性基线模型,以评估基准修订的影响。结果表明,相较于原始版本,新基准的准确率仅有微小提升。在两个基准版本之间,性能保持相对稳定。对于所测模型,原始基准与修订基准之间的准确率差距极小。这种稳定性支持了主要报告初始基准版本结果的决定。

作者通过在不同数据量下调整训练超参数,分析了数据集扩展对 32B 模型微调的影响。较小数据集采用更多 epoch 与更宽松的梯度裁剪进行训练,而较大数据集则使用较少 epoch 与更严格的梯度约束。随着数据集规模的增长,实际运行时间呈比例增加。自适应训练策略:实验设置根据数据规模调整超参数,对较小数据集采用更多 epoch 和更宽松的梯度裁剪,对较大数据集则减少 epoch 并收紧裁剪。训练时间的扩展性:实际运行时间随数据量显著增加,从最小数据集的较短耗时延伸至最大数据集的更长耗时。配方分类:实验将训练运行分为两种不同的配方标签,较大数据规模始终使用相同的特定配置。

作者探讨了混合不同任务生成策略对模型性能的影响。结果表明,融合排名靠前的策略(具体为混合前 4 至 8 项)在所有评估基准中产生了最强的均衡性能。该方法通过避免过度专业化并在多样化任务上保持高准确率,优于使用单一策略。混合前 4 至 8 项任务生成策略在所有基准中取得了最高性能。与使用单一顶尖策略相比,这种混合方法避免了过度专业化。当混合过多策略(如前 16 项)时,性能会出现下降。

通过对数据过滤、训练来源、基准修订、扩展协议及策略组合的一系列受控评估,本研究验证了优化模型性能的关键因素。按预测响应长度过滤任务能有效隔离具有挑战性的问题,从而持续提升 agent 能力;与专门或广泛的工具使用数据源相比,竞技编程数据集展现出最稳健的训练基础。基准更新带来的准确率变化极小,证实了评估的稳定性;结合自适应超参数调整,训练规模随数据量呈现可预测的扩展。此外,策略性地混合中等数量的任务生成方法可防止过度专业化,并在多样化评估中最大化均衡性能。